|
今天给大家带来一篇腾讯最新开源的向量模型的论文,模型开源,在CMTEB上拿了第一名!嵌入/向量模型是Agent、RAG中很关键的一个组件,所以也是一个卷的很激烈的一个领域。
Conan-embedding: General Text Embedding with More and Better Negative Samples
随着RAG(检索增强生成)技术的日益普及,嵌入模型的能力正受到越来越多的关注。嵌入模型主要通过对比学习进行训练,其中负样本是一个关键组件。以往的研究提出了各种硬负样本挖掘策略,但这些策略通常被作为预处理步骤使用。在本文中,我们提出了conan-embedding模型,该模型最大化地利用更多、更高质量的负样本。具体来说,由于模型处理预处理负样本的能力在训练过程中不断发展,我们提出了一种动态硬负样本挖掘方法,以便在整个训练过程中使模型接触到更多具有挑战性的负样本。其次,对比学习需要尽可能多的负样本,但受限于GPU内存的限制。因此,我们使用了Cross-GPU平衡损失(Cross-GPU balancing Loss)来提供更多的负样本进行嵌入训练,并在多个任务之间平衡批量大小。此外,我们还发现LLM(大型语言模型)生成的提示-响应对可以用于嵌入训练。我们的方法有效地增强了嵌入模型的能力,目前在Chinese Massive Text Embedding Benchmark(CMTEB)排行榜上排名第一。
模型开源地址:https://huggingface.co/TencentBAC/Conan-embedding-v1 Conan-embedding模型,主要是提出了两个的新点子:Dynamic Hard Negative Mining和Cross-GPU Batch Balance Loss - Dynamic Hard Negative Mining: 就是在训练过程中动态地挖掘难负例,每100次迭代检查一次,如果负例的分数乘以1.15小于初始分数且绝对值小于0.8,就认为这个负例不再困难,并用新的难负例替换它。
 - Cross-GPU Batch Balance Loss, CBB Loss: 对比学习需要尽可能多的负样本,但受到GPU内存限制。利用多个GPU引入更多的负样本,在多个任务之间平衡负样本的数量,提高训练效率和效果。
论文里还提到了,用LLM生成的prompt-response对来训练嵌入模型,这样可以让模型更聪明,处理起文本来更得心应手。 Conan-embedding在CMTEB的六个任务上都取得了优异的成绩,超越了之前所有的模型。消融研究也证明了动态硬负样本挖掘和CBB Loss这两个方法的有效性。 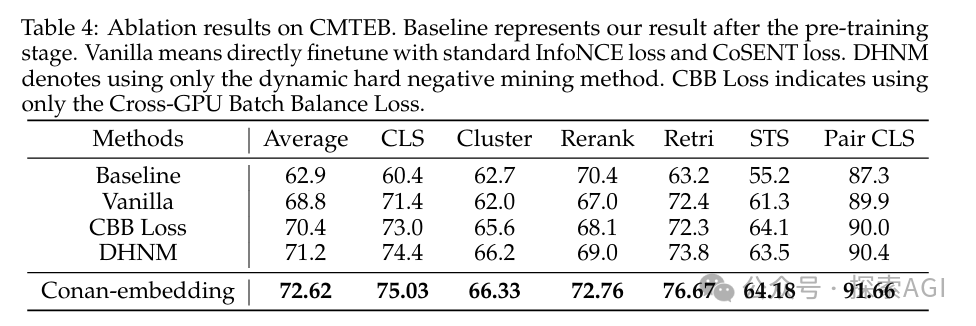 | 









