|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">当前,大型语言模型(LLMs)已经改变了我们对生成文本的理解。这些模型实在厉害,可以像人类一样写出文本、创造新内容,还能给出聪明的回答,这让人工智能的发展更进一步。 不过,尽管这些模型接受了很多数据的训练,它们只能知道这些数据中的信息,这就让它们很难提供最新的内容。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">这样,模型可能会给出过时的答案或错误的信息,这种现象叫做信息幻觉。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">为了改进这个问题,出现了一种叫做“检索增强生成”(RAG)的新方法,它把传统语言模型的优点和检索系统结合起来,让这些模型能更好地应对各种应用。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;display: table;padding: 0.3em 1em;background: rgb(0, 152, 116);color: rgb(255, 255, 255);border-radius: 8px;box-shadow: rgba(0, 0, 0, 0.1) 0px 4px 6px;transition: 0.3s;">什么是RAG?ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">RAG是一种检索增强方法,旨在提高LLMs的性能。通过在文本生成过程中引入信息检索步骤,RAG确保模型的回答更加准确和及时。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">RAG已经有了显著的发展,主要形成了两种模式:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">•Naive RAG:这是最基本的版本,系统只是简单地从知识库中检索相关信息,并直接交给LLM生成回答。 •Advanced RAG:这种版本在检索前后增加了额外的处理步骤,进一步优化了检索到的信息,确保生成的回答更加准确且与上下文无缝衔接。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;display: table;padding: 0.3em 1em;background: rgb(0, 152, 116);color: rgb(255, 255, 255);border-radius: 8px;box-shadow: rgba(0, 0, 0, 0.1) 0px 4px 6px;transition: 0.3s;">Naive RAGingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">Naive RAG是RAG体系中最初设计的版本,是将检索数据与LLM模型结合以提供高效回答的一种直接方法。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);transition: 0.3s;">基本系统包含以下组件:1.文档分块:过程开始时,文档会被拆分为更小的块。这样做是因为较小的块更易于管理和处理。例如,当你有一份长文档时,将其分段可以使系统在后续更容易检索相关信息。 2.嵌入模型:嵌入模型是RAG系统中的关键部分。它将文档块和用户查询转换为数值形式,即嵌入。这种转换是必要的,因为计算机更容易理解数值数据。嵌入模型使用先进的机器学习技术,以数学方式表示文本的含义。例如,当用户提问时,模型会将问题转化为一组数字,这些数字能够捕捉到查询的语义。 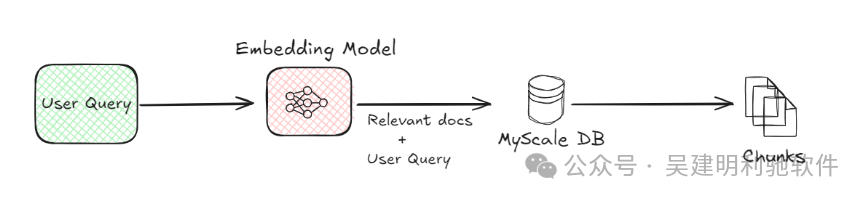
3.向量数据库(MyScaleDB):文档块转换为嵌入后,它们会被存储在向量数据库中,如MyScaleDB。向量数据库专门设计用于高效存储和检索这些嵌入。当用户提交查询时,系统使用向量数据库通过比较查询的嵌入与数据库中存储的嵌入来找到最相关的文档块。这样的比较有助于识别与用户问题最相似的块。 4.检索:向量数据库识别出相关的文档块后,它们会被检索出来。这个过程非常重要,因为它筛选出将用于生成最终回答的信息,确保只有最相关的数据被传递到下一阶段。 5.LLM(大型语言模型):检索到相关块后,LLM接管工作。它的任务是理解检索到的信息,并生成一个连贯的回答。LLM会根据用户的查询和检索到的块提供一个既相关又符合语境的回答。 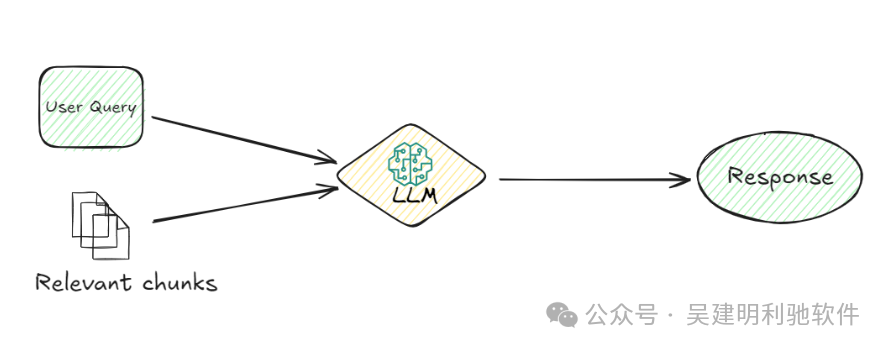
6.回答生成:最后,系统根据LLM处理过的信息生成回答,并将其传递给用户,以清晰简洁的方式提供所需信息。
通过理解从用户查询到最终回答的数据流,我们可以认识到Naive RAG系统的每个组件如何在确保用户收到准确且相关的信息中发挥重要作用。 优势•简单实现:RAG的设置非常简单,因为它直接将检索与生成结合,减少了复杂性,无需对语言模型进行复杂的修改或添加额外的组件。 •无需微调:RAG的一个显著优点是它不需要对LLM进行微调,这不仅节省了时间,降低了运营成本,还可以更快地部署RAG系统。 •增强准确性:通过利用外部的最新信息,Naive RAG显著提高了生成回答的准确性,确保输出不仅相关,还反映最新的数据。 •减少幻觉:RAG通过在生成过程中使用真实、事实数据来缓解LLMs生成错误或虚构信息的问题。 •可扩展性和灵活性:Naive RAG的简单性使其更容易在不同应用中扩展,因为它可以在不对现有检索或生成组件进行重大更改的情况下进行调整。这种灵活性使得它可以跨多个领域以最小的定制进行部署。
缺点•处理能力有限:检索到的信息直接使用,未经过进一步处理或优化,可能导致生成的回答在连贯性上存在问题。 •依赖检索质量:最终输出的质量在很大程度上依赖于检索模块找到最相关信息的能力。检索质量差可能导致回答的准确性或相关性降低。 •扩展性问题:随着数据集的增长,检索过程可能变慢,影响整体性能和响应时间。 •上下文限制:Naive RAG可能难以理解查询的广泛上下文,导致生成的回答虽然准确,但可能未完全符合用户的意图。
Advanced RAG在Naive RAG的基础上,Advanced RAG增加了一层复杂性。与Naive RAG直接使用检索信息不同,Advanced RAG在生成最终输出之前对检索到的数据进行额外处理,以优化相关性和整体质量。 
检索前优化在Advanced RAG中,检索过程甚至在实际检索发生之前就得到了优化,主要包括以下几个步骤: •索引改进:MyScale的MSTG(多策略树图)索引算法在速度和性能方面优于其他索引方法。MSTG结合了层次图和树结构的优点,使其在处理未筛选和已筛选搜索时都表现出色。 
•查询重写:在检索过程开始之前,系统会对用户的原始查询进行增强,以提高其准确性和相关性。这一步通过查询重写、扩展和转换来实现。例如,如果用户的查询太过宽泛,查询重写可以通过添加更多上下文或具体术语来优化它,而查询扩展可能会添加同义词或相关术语,以捕捉更广泛的相关文档。 •动态嵌入:在Naive RAG中,可能会使用单一的嵌入模型来处理所有类型的数据,这可能导致效率低下。而在Advanced RAG中,会根据具体任务或领域对嵌入进行微调和调整。这样,嵌入模型可以更好地捕捉特定类型查询或数据集的语境理解。 •混合搜索:Advanced RAG还采用了混合搜索方法,结合了不同的搜索策略以增强检索性能。这可能包括基于关键词的搜索、语义搜索和神经搜索。例如,MyScaleDB支持过滤后的向量搜索和全文搜索,允许使用复杂的SQL查询。
检索后处理在检索过程完成后,Advanced RAG不会停留于此。它进一步处理检索到的数据,以确保最终输出的最高质量和相关性。 优势Advanced RAG相对于Naive RAG具有以下优势: •更高的相关性:通过重排序,确保最相关的信息优先展示,提高了生成回答的准确性和流畅度。 •动态嵌入:根据特定任务定制的嵌入模型,有助于系统更准确地理解和响应不同查询。 •更准确的检索:通过混合搜索,Advanced RAG确保检索到的信息高度相关且精确。 •更高效的回答:上下文压缩去除了不必要的细节,使得处理过程更快,生成的回答更集中、更高质量。 •增强的用户查询理解:通过在检索前重写和扩展查询,Advanced RAG确保对用户查询有更充分的理解,生成更准确和相关的结果。
对比通过比较Naive RAG和Advanced RAG,我们可以看到,Advanced RAG在Naive RAG的基础上引入了关键改进,提高了准确性、效率以及整体检索质量。 | 标准 | 基础RAG | 高级RAG | | 准确性与相关性 | 通过使用检索到的信息提供基本准确性。 | 通过高级过滤、重排序和更好的上下文使用提高准确性和相关性。 | | 数据检索 | 使用基本的相似性检查,可能会遗漏一些相关数据。 | 使用混合搜索和动态嵌入等技术优化检索,确保数据高度相关和准确。 | | 查询优化 | 以直接的方式处理查询,未做太多增强。 | 通过查询重写和添加元数据等方法改进查询处理,使检索更精确。 | | 可扩展性 | 随着数据量的增长,可能变得不够高效,影响检索效果。 | 设计用于高效处理大型数据集,采用更好的索引和检索方法保持高性能。 | | 多阶段检索 | 进行单次检索,可能会遗漏重要数据。 | 采用多阶段过程,通过重排序和上下文压缩等步骤精炼初步结果,确保最终输出准确且相关。 |
结论Naive RAG和Advanced RAG都是非常强大的RAG框架,但各有特点和适用场景。 Naive RAG简单直接,响应速度快,特别适合那些需要快速实现和容易维护的场景。它通过把检索和生成过程直接结合起来,提升了答案生成的能力,非常适合时间紧迫或资源有限的情况。 而Advanced RAG则适合那些对质量和准确性要求较高的应用场景。它在检索前后增加了处理步骤,使生成的答案不仅准确,而且更连贯。这样做能更好地应对复杂的需求,提供更高质量的回答。 |










