|
 Google DeepMind高级研究科学家Rishabh Agarwal的一篇非常有深度的演讲稿,主要探讨了如何通过自生成数据来改进LLM的推理能力。 Google DeepMind高级研究科学家Rishabh Agarwal的一篇非常有深度的演讲稿,主要探讨了如何通过自生成数据来改进LLM的推理能力。
当前 LLM 训练面临的一个关键挑战: 高质量训练数据的稀缺,传统方法依赖从网络抓取或人工收集高质量数据,这种方式既耗时又昂贵,难以扩展,特别是对于复杂任务而言。  为解决这一问题,演讲者提出了一个创新性的想法: 让模型自己生成训练数据。但这里存在一个潜在的问题: 如果简单地让模型生成数据并用于训练,可能会导致 "模型崩溃"。  ReST_EM算法介绍了一种称为 ReST_EM (Reinforcement Self-Training via Expectation-Maximization) 的算法来解决这个问题: - E-step:从模型生成样本,并使用二元反馈进行筛选。
这个过程本质上对应于基于期望最大化的强化学习。 实验结果ReST_EM 在数学和编程等问题解决任务上取得了显著效果,甚至超过了人类数据训练的模型。这表明自生成数据可能比人类数据更加 "in-distribution" (即更符合模型的分布)。  验证器 (Verifier) 的引入进一步探讨了如何利用错误解答来训练验证器。验证器可以帮助模型在测试时更好地利用计算资源,提高性能。 - Next-Token 预测:将验证器训练为下一个 token 的预测器,这有助于统一生成和验证任务。
- 链式推理(Chain-of-Thought):允许验证器使用链式推理来评估解决方案。
 计算匹配采样通过计算匹配采样,可以在给定计算资源的情况下,让小模型生成更多样本,从而提高大模型的性能。 - 考虑计算成本:根据模型参数和推理 token 数量来优化采样成本。
- 知识蒸馏:使用较小的模型来生成更高质量的合成数据。
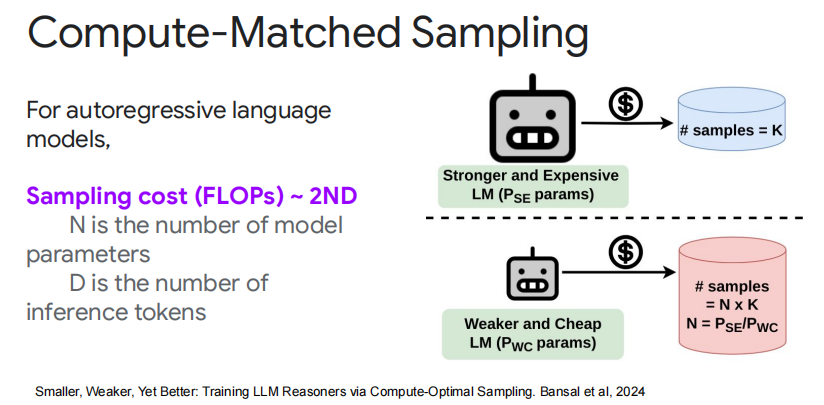  上下文学习 (In-Context Learning)最后探讨了是否可以通过上下文学习来替代微调过程,提出了强化上下文学习 (Reinforced ICL) 的概念。 - 多样本 In-Context 学习:在模型的上下文中使用多个样本来增强学习效果。
- 迭代学习:通过迭代过程来提高模型在复杂任务上的性能。
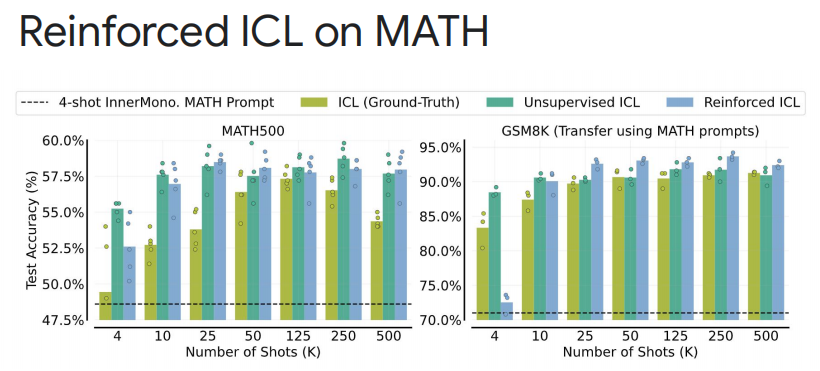 Rishabh Agarwal通过这些方法,展示了如何通过自生成数据和验证器来提高 LLMs 在问题解决任务上的性能,尤其是在数学和编程领域。此外,还讨论了如何通过优化计算成本和利用较小模型来进一步提高数据生成的效率和质量。
| 









