|
LightRAG最近挺火, 它将图谱结构整合到文本索引和检索过程中,解决了传统RAG系统在处理复杂实体关系和上下文连贯性方面的不足。 这听上去很熟悉,和GraphRAG很像。 但LightRAG屌在哪里呢?有两个地方: - 双层检索结构,底层提取细分实体,高层提取整体关系
-增量更新算法,不需要更新整个索引
先说第一点: 举个例子,我想知道,苹果的营养价值是什么? 这一步LightRAG和GraphRAG大致相同。 它们首先将所有源文档拆分为较小的文本块,使用大型语言模型提取其中的实体(如“苹果”、“维生素C”、“膳食纤维”)及其关系(如“苹果富含维生素C”)
不同就在于后面的处理: 针对用户查询,LightRAG这里会分为两步: 低层检索,针对查询中的具体实体(如“苹果”、“营养”),从知识图谱中检索相关的具体信息和关系。 高层检索,针对查询的整体主题(如“苹果的营养价值”),检索更广泛的主题和概念。然后将低层和高层检索到的信息整合在一起,形成一个全面的知识基础,LLM基于整合后的信息生成连贯且上下文相关的回答。
而GraphRAG之前我仔细讲过,它会将知识图谱划分为多个社区,每个社区代表一组紧密相关的实体和关系。 例如,一个社区可能专注于“苹果的维生素C含量”,另一个社区则聚焦于“苹果的膳食纤维益处”。 它针对用户查询,识别相关社区摘要,将所有部分回答进行归约总结,生成最终的全局回答。

双层检索让LightRAG能够直接整合信息,而GraphRAG要等所有社区摘要生成之后才能总结信息。 这就是LightRAG的创新之处,别小看这一点,实际上能节省很多成本。
第二点: LightRAG支持快速适应新数据,无需重建整个索引。 这对企业或者法律、新闻等等数据频繁更新且需要快速适应新信息的领域来说简直是神器。 而GraphRAG需要重构整个社区关系,效率相对较低。
实测: 这里我用colab跑了一次LightRAG,数据用的是民?典全文: 全文9万多字,一共花了0.1刀,用的是4omin:
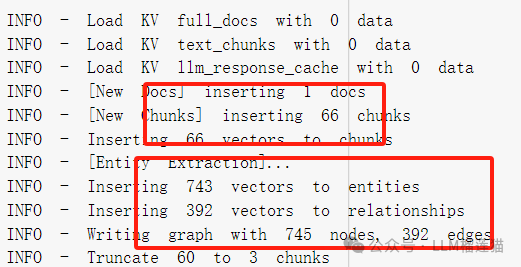
-生成了66个文本块 -从66个块中提取了1102个实体和439个关系(包括重复) - 最终插入了743个唯一实体向量和392个唯一关系向量(这里LightRAG会对实体和关系进行去重)- 最终构建了一个包含745个节点和392条边的图。
询问: 我老公没有经过我的同意买了一辆100万的豪车,这算不算我的负债,列名详细的法律依据条例?

LightRAG的回答跨越了婚姻法的领域,全面地引用了法典三处的条例,不仅有实体的细节(底层),也有全面的考虑(高层检索) 作为对比我用扣子,直接把文档作为知识库嵌入,得到的回答只是简单索引了一条,缺少全面的理解和概述:

假设我要增加一条条例:
夫妻之间每天都要一起吃饭,否则共同财产就自动由儿女继承。

这里看到插入的速度很快,从代码可以看到并没有重启整个文档的索引和重构,只是添加了实体数量和关系数量。 问: 夫妻之间有没有什么特别奇怪的条例? 回答:  。 。
| 









