|
随着自然语言处理技术的快速发展,RAG(Retrieval-Augmented Generation)作为一种结合了检索和生成的方法,逐渐成为构建高效问答系统的重要工具。然而,在实际应用中,RAG系统仍然面临许多挑战。本文将详细介绍RAG过程中常见的问题及其解决方案,并结合应用场景进行优化,帮助开发者和研究人员更好地应对这些挑战,后续的文章中将详细讲解每一个问题的解决思路及代码实现。 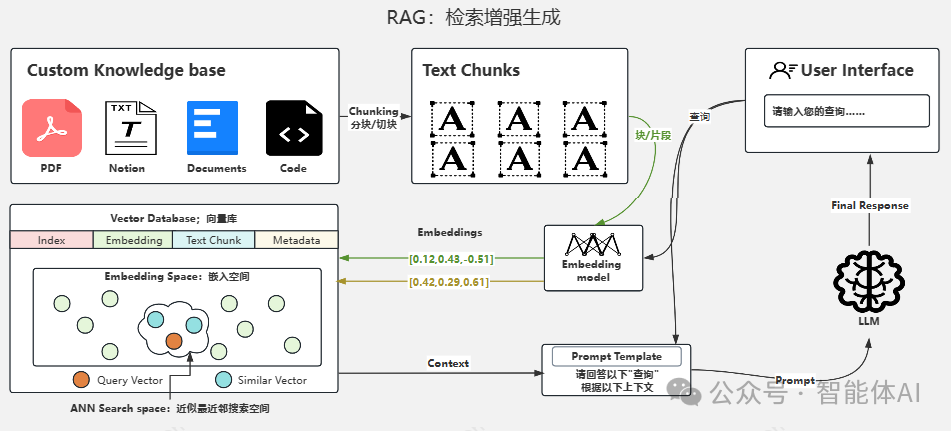
一、Query 相关的问题及解决方案问题1:Query 表达不充分描述:用户的查询可能无法准确地表达其需求,特别是在电商或特定领域的搜索中,用户的查询可能包含多个条件,这些条件难以通过简单的embedding来表达。解决方案: 多条件处理:将用户的查询拆分成多个子查询,分别处理后再合并结果。例如,用户查询“我想要一条黑色皮质迷你裙,价格低于20美元”,可以将其拆分为“黑色”、“皮质”、“迷你裙”、“价格低于20美元”等多个条件,分别进行检索,最后合并结果。 属性提取:从用户的查询中提取关键属性(如价格、颜色等),并通过这些属性进行精确过滤。例如,使用大模型对用户的查询进行解析,提取出“黑色”、“皮质”、“迷你裙”、“价格 < 20美元”等属性,然后通过这些属性在数据库中进行精确检索。
应用场景:在电商平台中,用户查询“我想要一条黑色皮质迷你裙,价格低于20美元”。系统首先使用大模型解析出关键属性“黑色”、“皮质”、“迷你裙”和“价格 < 20美元”,然后通过这些属性在数据库中进行精确检索,确保返回的商品列表符合用户的查询条件。 问题2:Query 转换不精准描述:将用户的自然语言查询转换为系统能够理解的形式时,可能存在转换不准确的问题,导致检索结果与用户需求不符。 解决方案: 大模型辅助:使用大模型对用户的自然语言查询进行理解和转换,生成更精确的检索条件。例如,使用BERT或其他预训练模型对用户的查询进行嵌入,然后通过这些嵌入向量在向量数据库中进行搜索。 多角度生成:生成多个不同角度的查询,以覆盖更多的可能性。例如,用户查询“我想要一条黑色皮质迷你裙”,可以生成多个查询变体,如“我想要一条黑色迷你裙,材质是皮质”、“我想要一条皮质迷你裙,颜色是黑色”等,然后对这些变体进行检索,合并结果。
应用场景:在旅游搜索引擎中,用户查询“我想找一个有免费Wi-Fi的海滩附近的酒店”。系统使用大模型生成多个查询变体,如“我想找一个有免费Wi-Fi的海滩附近的酒店”、“我想找一个海滩附近有免费Wi-Fi的酒店”等,然后对这些变体进行检索,确保返回的酒店列表符合用户的查询条件。
二、Retrieval 相关的问题及解决方案问题1:检索结果不相关描述:从向量数据库中检索出的文档可能与用户的查询不相关,无法提供有效的上下文信息。 解决方案: 应用场景:在医疗问答系统中,用户查询“如何治疗普通感冒”。系统首先使用宽泛的条件“普通感冒”进行检索,然后根据用户的进一步提问(如“普通感冒的症状”)进行更具体的检索,确保返回的信息与用户的查询高度相关。 问题2:检索结果不完整描述:即使检索结果包含相关信息,也可能缺乏完整性,无法全面回答用户的问题。 解决方案: Sentence Window Retrieval:通过窗口机制,提取与检索结果相邻的上下文信息,确保信息的完整性。例如,如果检索结果是一个句子,可以提取该句子前后几个句子的信息,形成一个更大的上下文。 Parent-Child Trans Retrieval:将文档划分为父级和子级片段,先检索父级片段,再根据父级片段的结果检索子级片段,确保信息的精确性和完整性。例如,将一个文档划分为多个父级片段,每个父级片段再划分为多个子级片段,先检索父级片段,再根据父级片段的结果检索子级片段。
应用场景:在法律咨询系统中,用户查询“创办企业的法律要求有哪些?”系统使用Sentence Window Retrieval方法,提取与检索结果相邻的上下文信息,确保返回的法律条款和要求信息完整且准确。 问题3:检索结果冗余描述:检索出的文档可能包含大量无关信息,导致上下文过于冗长,影响系统性能和用户体验。 解决方案: 应用场景:在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用TF-IDF方法对检索结果进行过滤,去除冗余信息,确保返回的新闻文章简洁且相关。 问题4:检索结果排序不当描述:检索出的文档未经过有效排序,可能导致重要的信息未能优先呈现。 解决方案: 应用场景:在学术论文检索系统中,用户查询“近期机器学习的研究进展”。系统使用BM25算法对检索结果进行排序,确保最新的研究成果优先呈现。
三、Context 相关的问题及解决方案问题1:上下文不充分描述:检索出的上下文信息可能不足以回答用户的问题,导致生成的回答不准确或不完整。 解决方案: 应用场景:在教育辅导系统中,用户查询“量子力学的关键概念有哪些?”系统从多个数据源(如教科书、学术论文、在线课程)检索相关信息,并将知识图谱中的关键概念融入上下文中,确保生成的回答全面且准确。 问题2:上下文过多描述:过多的上下文信息不仅增加了系统的负担,还可能导致生成的回答中包含不必要的信息。 解决方案: 应用场景:在金融资讯系统中,用户查询“最近亚洲的经济趋势”。系统对检索结果进行去重处理,并使用T5模型生成摘要,确保返回的经济趋势信息简洁且相关。 问题3:上下文不相关描述:检索出的上下文信息可能与用户的问题不相关,影响回答的质量。 解决方案: 应用场景:在健康咨询系统中,用户查询“疫情期间如何改善心理健康”。系统对检索结果进行相关性评分,确保返回的心理健康建议与用户的查询高度相关。
四、Ranking 相关的问题及解决方案问题1:排序算法选择困难描述:选择合适的排序算法以确保检索结果的有效性和相关性是一个挑战。 解决方案: 应用场景:在音乐推荐系统中,用户查询“2000年代的热门歌曲”。系统使用A/B测试方法,对比不同排序算法的效果,最终选择综合性能最优的排序算法。 问题2:异常值影响描述:异常值的存在可能严重影响排序结果,导致重要的信息被忽略。 解决方案: 应用场景:在新闻推荐系统中,用户查询“最新新闻”。系统使用Z-score方法检测和处理异常值,确保返回的新闻文章真实可靠。
五、Response 相关的问题及解决方案问题1:回答不准确描述:生成的回答可能偏离用户的实际需求,或者包含错误的信息。 解决方案: 应用场景:在法律咨询系统中,用户查询“如何申请专利”。系统结合多个大模型的输出,生成详细的专利申请指南,并使用语法检查方法修正生成的回答中的错误。 问题2:回答不相关描述:生成的回答可能与用户的问题不相关,无法提供有效的帮助。 解决方案: 应用场景:在旅游搜索引擎中,用户查询“巴黎最好的旅游景点”。系统验证生成的回答与检索出的巴黎景点信息的相似度,确保返回的旅游建议与用户的查询高度相关。 问题3:回答冗余描述:生成的回答可能包含大量无关信息,影响用户体验。 解决方案: 应用场景:在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用T5模型生成回答的摘要,确保返回的新闻文章简洁且相关。
六、其他问题及解决方案问题1:文档解析难度高描述:不同格式的文档(如PDF、HTML、PPT等)解析难度大,可能影响数据的质量和系统的性能。 解决方案: 应用场景:在科研文献管理系统中,用户上传了多篇不同格式的论文。系统使用PDFMiner和BeautifulSoup等工具对这些文档进行解析,提取出标题、作者、摘要等关键信息,确保数据的准确性和完整性。 问题2:多轮对话中的Query不完整描述:在多轮对话中,用户的Query可能不完整,因为用户可能依赖于之前的对话内容,导致当前的Query信息不足。 解决方案: 应用场景:在一个客服聊天机器人中,用户在多轮对话中询问关于某个产品的详细信息。系统将用户的对话历史与当前Query结合起来,生成一个新的Query:“我想了解这款产品的详细规格和价格”,确保生成的回答包含所有相关信息。 问题3:Query扩展生成不准确描述:生成的Query扩展可能不准确,导致检索结果与用户需求不符。 解决方案: 应用场景:在电商平台中,用户查询“我想要一条黑色皮质迷你裙”。系统生成多个Query扩展,并根据用户的反馈选择最合适的Query扩展,确保返回的商品列表符合用户的查询条件。 问题4:检索结果融合不充分描述:从多个数据源检索出的结果可能需要进一步融合,以提供更全面的信息。 解决方案: 应用场景:在教育辅导系统中,用户查询“量子力学的关键概念有哪些?”系统从多个数据源(如教科书、学术论文、在线课程)检索相关信息,并将知识图谱中的关键概念融入上下文中,确保生成的回答全面且准确。 问题5:排序结果不稳定描述:排序结果可能受噪声影响,导致不稳定的排序结果。 解决方案: 应用场景:在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用鲁棒性更强的排序算法,减少噪声的影响,并根据用户的点击率和满意度动态调整排序权重,确保返回的新闻文章真实可靠。 问题6:生成的回答不连贯描述:生成的回答可能缺乏连贯性,影响用户的阅读体验。 解决方案: 应用场景:在环保咨询系统中,用户查询“全球变暖的原因和影响”。系统生成多个段落,分别回答“全球变暖的原因”和“全球变暖的影响”,确保回答的整体连贯性和逻辑性。
七、总结通过对RAG过程中常见问题的深入分析和解决方案的提出,我们可以显著提升系统的性能和用户体验。具体来说,通过优化Query处理、检索、上下文生成、排序和生成回答等各个环节,可以有效解决RAG系统在实际应用中面临的问题。希望这些优化方案能够为开发者和研究人员提供有益的参考,帮助他们在构建高效问答系统时取得更好的成果,后续的文章中将详细讲解每一个问题的解决思路及代码实现,敬请期待。 | 









