他们采用的是另外一种路径:避免了强制将中间推理过程转换成具体的语言token,而是直接用推理状态(Meta团队称为“想法”)在潜空间里展开思维链推理。
这一方法同样是放弃了token,只不过是限制在思维链这个场景中。
在这个叫Coconut的思维链中,Meta的研究员直接利用最后一个隐藏状态(即“想法”)作为下一个输入嵌入。整个推理过程是连续可微的,可以通过梯度下降来优化。
这就像是让模型在"想法"的空间中直接推理,而不是必须把每一步都转换成具体的语言来表达。

它的逻辑训练方式也一样相对特殊,在前几步训练时,它还是采用一般思维链的方式训练,用话语和token作为要素训练模型,在之后他们逐渐加多“想法”的占比,直到最后完全用“想法”取代token形成的语句。

这一方法有效提高了大语言模型的推理能力,在部分测试项目上甚至高于传统的CoT。
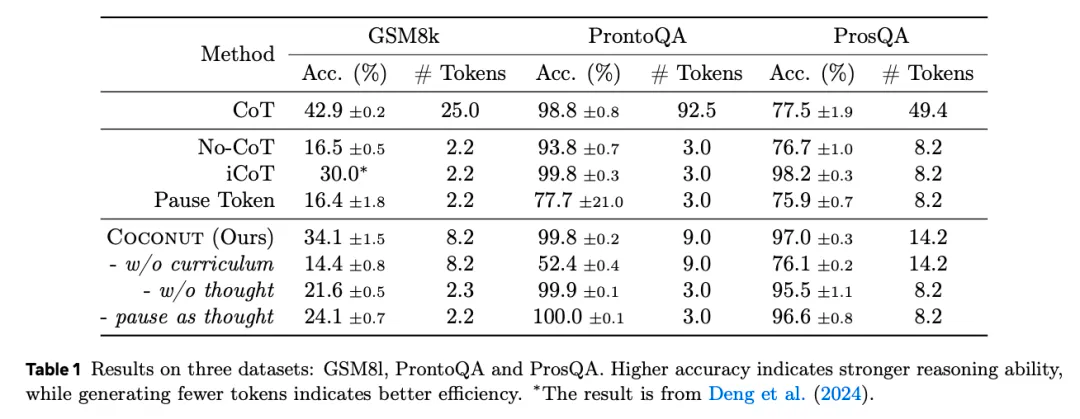
而且通过这一方法,LLM 推理就不光再是链式的,而是一个由最后一个隐藏状态引发的树状搜索序列,可以一次性选择多个潜在节点。更不容易出现由于第一个步骤确定后,无法引向正确节点的幻觉。











 anguage Modeling in a Sentence Representation Space》,让大模型直接从概念学起。
anguage Modeling in a Sentence Representation Space》,让大模型直接从概念学起。