近日,国产AI大模型领军企业DeepSeek宣布,将连续五天开源五大核心代码,消息一经发布便在AI圈引发广泛关注。2月25日,第二篇如约而至。接下来,让我带你一起深入了解开源第二日的精彩内容。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">想象一下你正在用电脑玩一个大型的多人在线游戏。游戏中的每个玩家都有各自的任务和角色,而游戏服务器则需要确保每个玩家的操作都能实时同步。要是有些玩家的操作反应慢了,可能就会导致延迟,影响整个游戏体验。在 AI 系统中,尤其是在处理非常大的语言模型时,GPU 就像这些玩家,而 DeepEP 就是保证这些“玩家”之间沟通顺畅、及时的系统。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">DeepEP是由DeepSeek开发的一个高效通信库,专为大型混合专家(MoE)模型设计。大家可以把MoE想象成一个巨大的团队,每个“专家”都有自己擅长的领域,处理不同的任务。比如说,假设你有一个很庞大的团队,每个成员负责不同的知识领域,想要在最短的时间内处理好一个复杂的问题,每个人都必须有效沟通。但这些专家们并不是每时每刻都在工作,只有在特定的情况下,某些专家会被“召唤”来处理任务。这就需要快速的内部沟通系统,DeepEP 就是这样的系统。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">当一个大型模型像 MoE 这样需要分布在多个 GPU 上进行计算时,如何让这些 GPU 之间快速、有效地交换信息就成为了一个大问题。传统的方法可能导致**“沟通堵塞”**,就像一条繁忙的高速公路,所有的数据都在同一条路上走,造成延迟。而 DeepEP 就是通过优化这些通信路径,确保每一条信息都能在最快的时间内传递,从而避免了“交通拥堵”。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;height: auto;"/>ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">1. 快速的“信息高速公路”--高吞吐量与低延迟的 GPU 内核ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">DeepEP 提供了一种叫做all-to-all GPU 内核的技术,它就像一个超级快速的传送带,可以确保数据在 GPU 之间快速流动。尤其是在 MoE 模型中,数据并不是每时每刻都需要被所有的专家处理,只有少数专家被激活来完成工作,DeepEP 通过高效的内核操作,减少了不必要的通信,使得这些“专家”之间的信息交流变得更加高效。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">2. 节省“内存空间”--低精度操作支持ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">DeepEP 支持使用FP8这样的低精度计算方式,就像你使用高效压缩算法,将文件压缩后存储,既节省空间,又能保证文件的完整性。FP8 的使用,让 AI 模型在训练和推理时能够减少内存消耗,这对于大规模的分布式系统来说至关重要,能够让更多的模型和数据在同样的硬件上运行。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">3. 更智能的数据传输--优化的非对称域带宽转发 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;height: auto;"/>ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">1. 快速的“信息高速公路”--高吞吐量与低延迟的 GPU 内核ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">DeepEP 提供了一种叫做all-to-all GPU 内核的技术,它就像一个超级快速的传送带,可以确保数据在 GPU 之间快速流动。尤其是在 MoE 模型中,数据并不是每时每刻都需要被所有的专家处理,只有少数专家被激活来完成工作,DeepEP 通过高效的内核操作,减少了不必要的通信,使得这些“专家”之间的信息交流变得更加高效。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">2. 节省“内存空间”--低精度操作支持ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">DeepEP 支持使用FP8这样的低精度计算方式,就像你使用高效压缩算法,将文件压缩后存储,既节省空间,又能保证文件的完整性。FP8 的使用,让 AI 模型在训练和推理时能够减少内存消耗,这对于大规模的分布式系统来说至关重要,能够让更多的模型和数据在同样的硬件上运行。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif;font-size: 18px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">3. 更智能的数据传输--优化的非对称域带宽转发有时,数据需要在不同的域之间传输,比如从一台机器的NVLink到另一台机器的RDMA网络。这就好像你要从不同的城市之间运输物资,DeepEP 优化了这一过程,使得这些跨域的数据传输更加高效,不会出现“物流堵塞”。 4. 两种内核设计,满足不同需求 DeepEP 设计了两种不同的内核: - 高吞吐量内核就像一条高速公路,适用于需要快速“运输”的任务,比如训练时的大规模数据传输。
- 低延迟内核就像是紧急救援通道,专门为需要低延迟的任务设计,确保任务在最短时间内完成,比如推理时的快速响应。
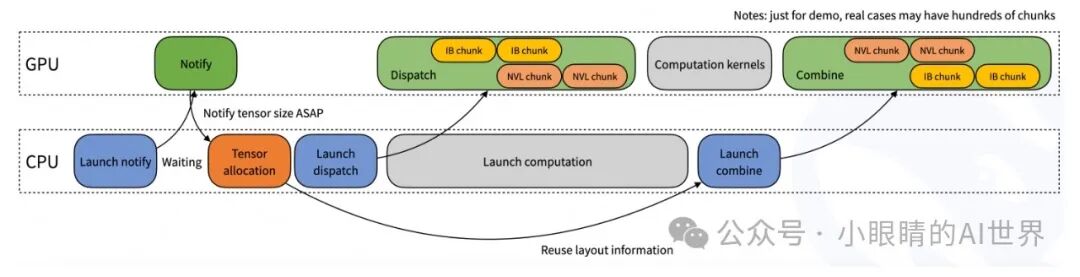 我们通过测试可以看到,DeepEP 在NVIDIA H800 GPU和CX7 InfiniBand RDMA 网络卡上的表现非常出色,几乎达到了硬件的极限。举个例子,当我们测量 DeepEP 在内部节点之间的通信时,发现它能够处理153 GB/s的数据分发和158 GB/s的数据组合。而在外部节点之间,即使是最复杂的 64 专家配置,DeepEP 的组合带宽依然能达到45 GB/s,这意味着它在处理大规模分布式计算任务时,效率非常高。 低延迟内核的性能也表现出色,特别是在高负载下,DeepEP 保持了良好的延迟与带宽平衡,证明其在训练和推理任务中的强大能力。 虽然 DeepEP 目前在性能上表现非常强劲,但它仍然面临一些争议。例如,一些研究者认为,MoE 模型的通信优化可能因硬件配置而有所不同,DeepEP 的优化方法可能并不适用于所有场景。然而,随着研究的深入和应用的拓展,DeepEP 有望在未来成为更广泛场景下的标准通信库。 想象你是一个大规模语言模型的“指挥官”,DeepEP 就像你的超级通信系统,让各个“专家”之间能够高效地合作,共同完成任务。在 AI 推理和训练的世界里,DeepEP 就像一条高速、高效的沟通之路,它使得数据在 GPU 间流动更迅速、更平稳,减少了瓶颈,提高了处理速度,节省了宝贵的内存资源。 随着DeepSeek开源更多相关工具,DeepEP 不仅提升了技术性能,还推动了 AI 开发的开放和协作。它为大规模分布式 AI 系统的开发提供了坚实的技术基础,未来,DeepEP 将在更多领域中发挥更大的作用,推动 AI 技术迈向更高的峰巅。
|










