8 卡 GPU 服务器
随着模型复杂程度增加,单张 GPU 无法完成训练任务,需要联合多张 GPU,尤其在 LLM 时代,8 卡 GPU 服务器已经成为了新的常态。
在 8 卡 GPU 服务器中,CPU 仍然承担着系统管理、任务调度、逻辑运算等工作,而 GPU 则主要负责大规模并行计算任务。

GPU 互联技术分类
在深度学习的训练过程中,随着 GPU 算力的飞速飙升,GPU 之间的互联数据传输速度已经成为了制约训练效率的瓶颈。从网络构成的角度,可以分为:
本文讨论的是单机 GPU 卡间互联。解决的问题就是如何将 8 张 GPU 互联起来,使其能够互相进行高效的通信。从互联技术的层面有以下 4 大类:
PCIe 直连
PCIe 直连,即:GPU 直接连接到 CPU,而没有通过 PCIe Switch。但 PCIe 直连存在显著的 PCIe lane 总量紧缺的问题。
以 Gooxi AMD Milan 平台 4U 8 卡 AI 服务器为例:
- 2 颗第三代 AMD CPU,每颗 AMD CPU 128 个 PCIe lane,总计 128x2 lane。(注:第三代 Intel CPU 每颗只有 64 lane)。
- 2 颗 CPU 之间使用 3 条 xGMI 互联,占用 32x3 lane,剩余 160 lane 给到 NIC、GPU 等 I/O 外设设备。
- 每张 GPU 占用 16 lane,8 卡 GPU 总计 16x8 lane,剩余 32 lane。
- 剩余的 32 lane 可供其他 NIC、RAID 卡使用。
PCIe Switch 互联
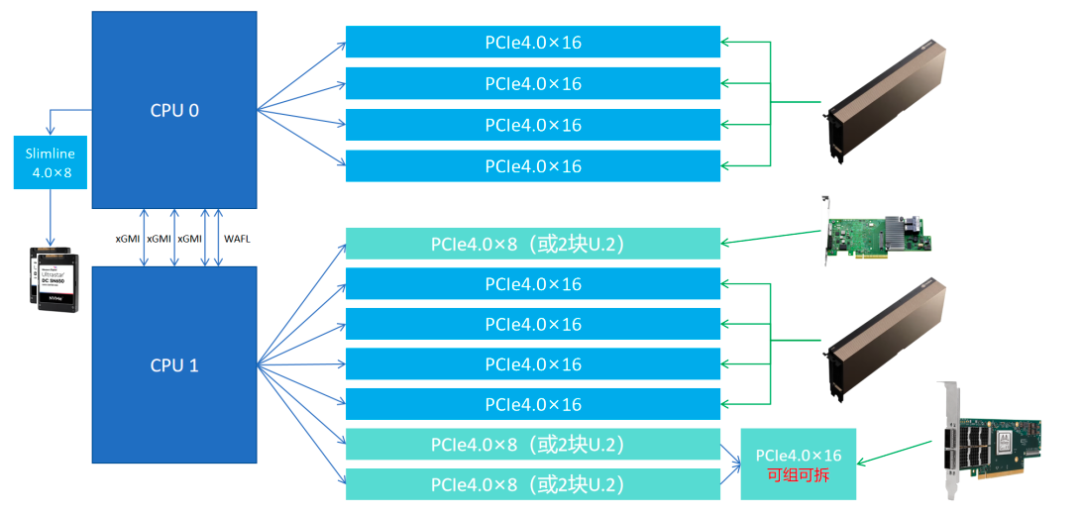
上述 PCIe 直连拓扑中,PCIe lane 的数量显然是紧缺的。为了解决这个问题,新的 PCIe 标准中引入了 PCIe Switch 的模块。在主板上和 2 个 CPU Socket 一一对应,采用 2 个 PCIe Switch 芯片来进行信号扩展。
PCIe Switch 互联,即:多个 GPU 通过 PCIe Switch 直接与 CPU 相连。GPU 发出的信号首先到 PCIe Switch,然后 Switch 对应的 CPU 再对数据进行分发调度到,显然会引入额外的网络延迟,限制了系统性能。

PCIe Switch 只占用了 16 条 CPU 上的 PCIe lane,通过信号放大的方式,每个扩展芯片可以扩展多 5 个 x16 的插槽。以此解决 CPU 直连 PCIe lane 数量不足的问题。
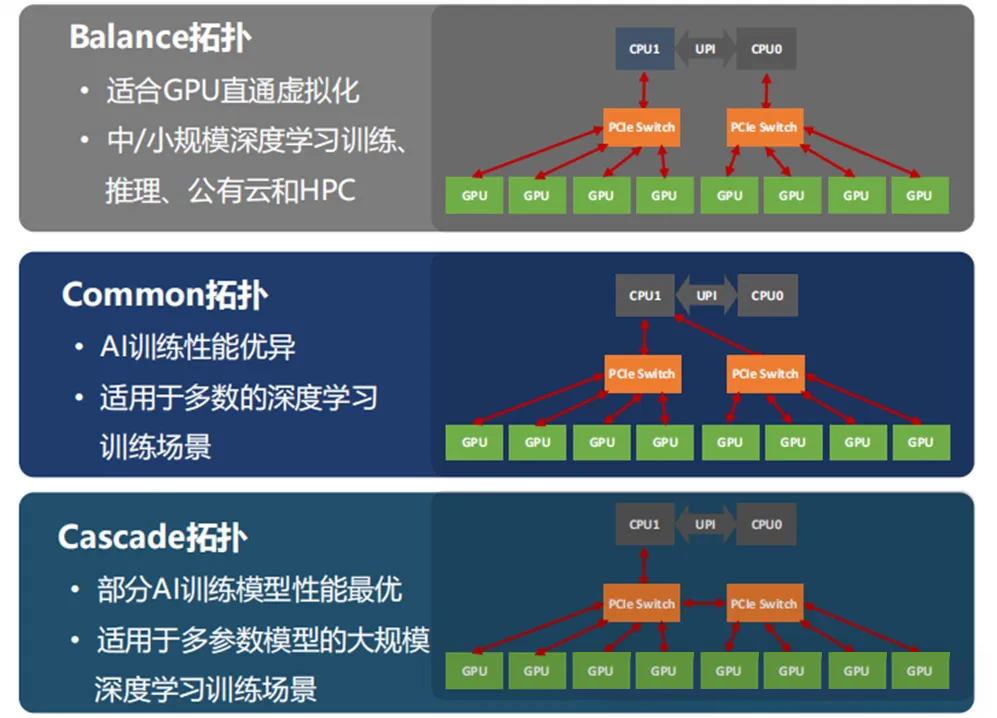
通过 PCIe Switch,服务器可以实现 CPU-GPU、GPU-GPU 之间的连接,同时也出现了 3 种连接模式,即:balance、common、cascade 拓扑。
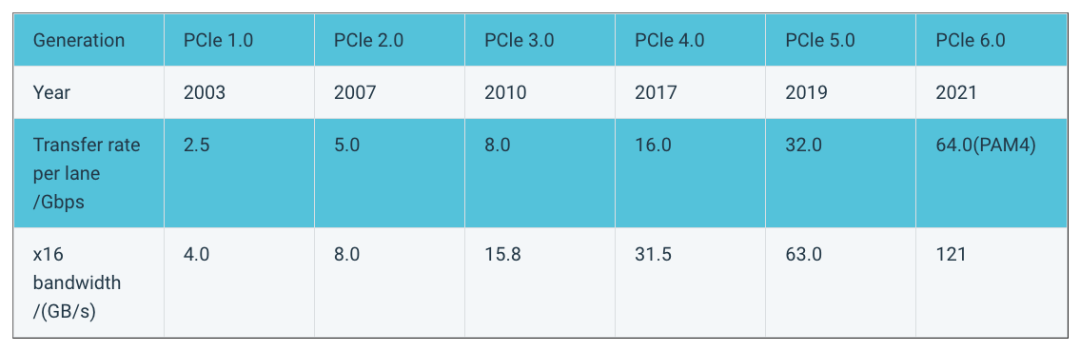
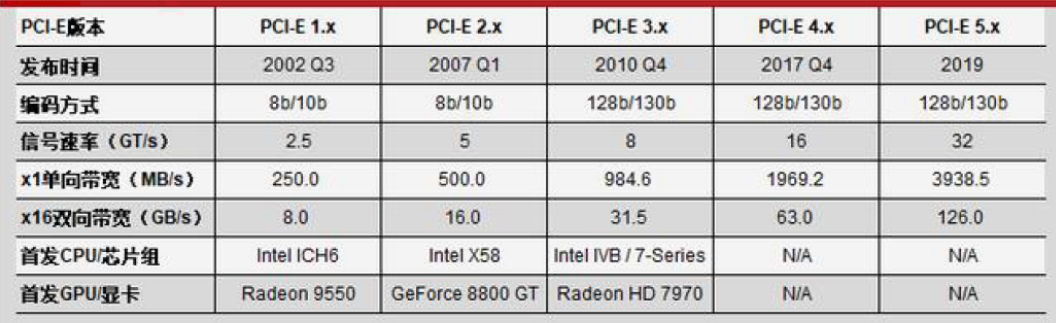
虽然 PCIe 提供的双向带宽 GB/s 正在以每代翻一倍的速度提升,例如 PCIe 5.x x16 已经可以提供 126GB/s 的双向带宽,相对于 GPU 算力对带宽需求而言依旧很慢。
另外,PCIe Switch 互联拓扑中的 GPU 之间可能存在 GPU0→Switch0→CPU0→CPU1→Switch1→GPU7 的通信链路,它的通信不可避免的存在一定的延迟,因而更适合用于对信号效率不敏感且追求性价比的使用场景,如:推理、云计算等领域。
NVLink 互联
2014 年,NVIDIA 推出 NVLink 技术来代替 PCIe,旨在突破 PCIe 互联的带宽性能瓶颈,实现 GPU 芯片之间的高带宽、低延迟数据传输。
NVLink 互联,即:GPU 通过 NVLink 两两直连,而不再需要通过 PCIe Switch。
- https://www.nvidia.com/en-us/design-visualization/nvlink-bridges/
NVLink 是一种点对点的高速互连技术,单条 NVLink 就是一条全双工双路信道,每条 NVLink 链路可以将 2 个 GPU 直连起来,并且每个 GPU 可以提供多条 NVLink 接口连接多个 GPU。

以第四代 NVLink 和 Hopper GPU 芯片架构为例,已经支持高达双向 900GB/s 的带宽,比 PCIe 5.x x16 的 126GB/s 提升了 7 倍的速率。并且每个 GPU 提供了 18 个 NVLink 接口。
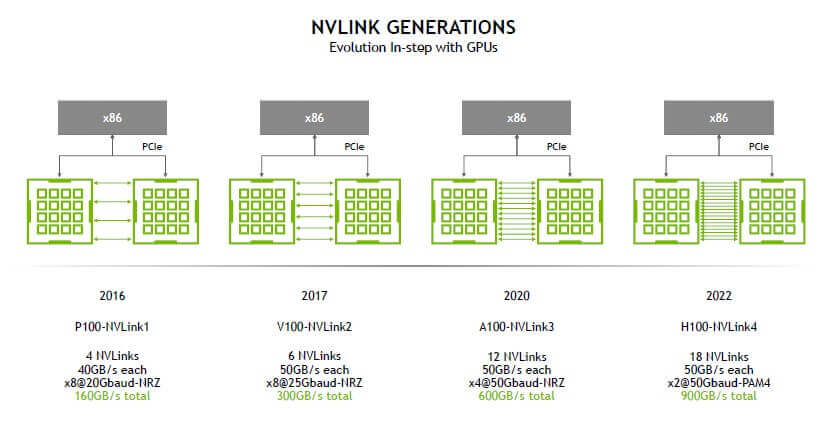
NVLink 1.0 与 DGX-1 系统
2014 年,与 NVLink 1.0 同期发布了 P100 GPU 以及 DGX-1 8 卡 GPU 服务器解决方案。
每张 P100 提供 4 条 NVLink 接口,每条 Link 支持双向 40GB/s 的带宽,所以单块 P100 GPU 支持总计 4 x 40 = 160GB/s 的带宽。是同时代 PCIe 3.x x16 双向带宽的 5 倍。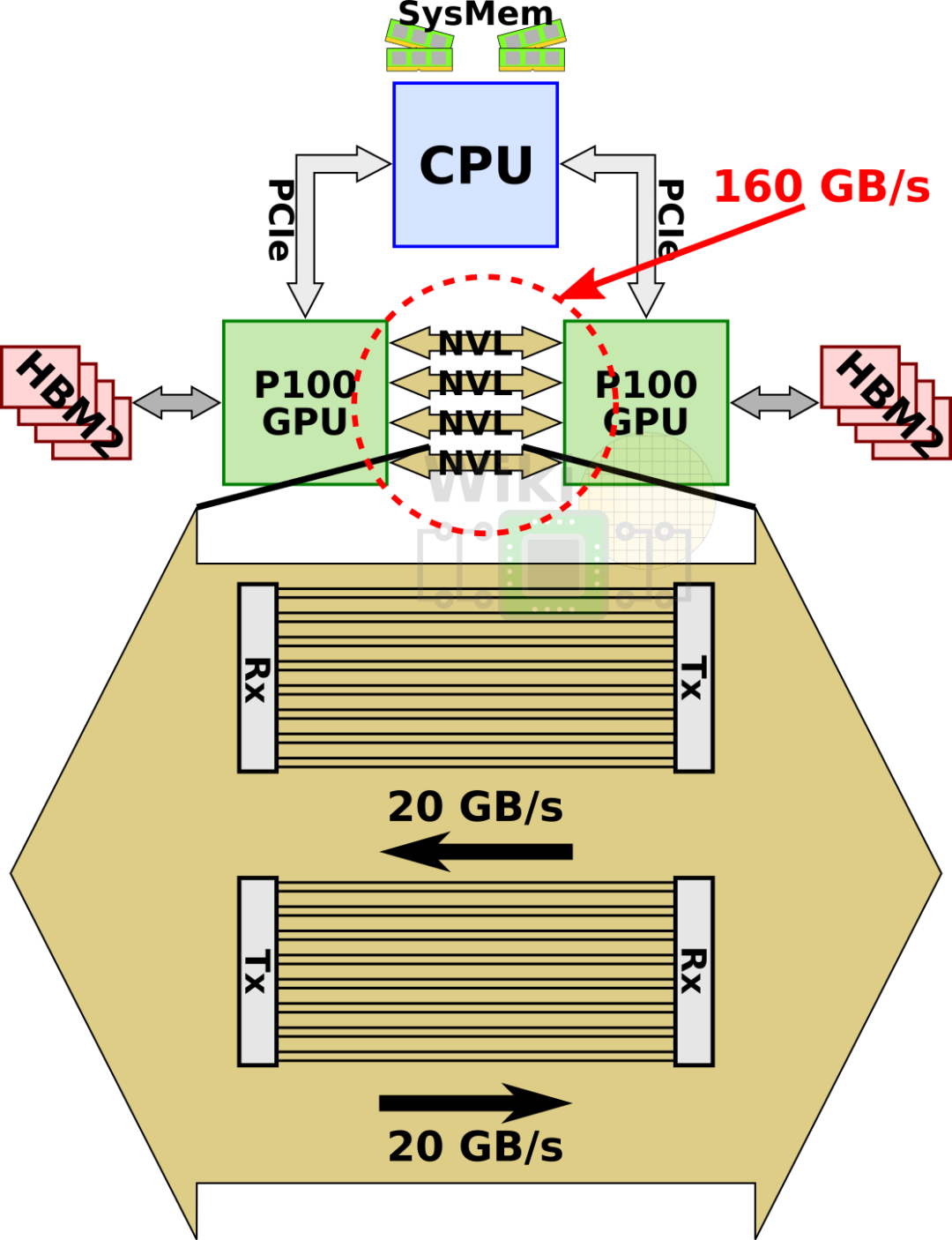
由于 P100 只支持 4 条 Line,所以 8 块 GPU 被分为了 4 + 4 两组,并且 GPU 之间只能组成一种称之为 Cube-Mesh 的互联拓扑。如下图所示。
因为 8 张 GPU 所需要的 PCIe lane 总数已经超出了 2 块 Intel Xeon CPU 所能够提供的数量,所以每组 4 张 GPU 被连接到同一个 PCIe Switch 上与 Xeon CPU 相连。最终就形成了下面这张经典的 NVLink 互联拓扑图。
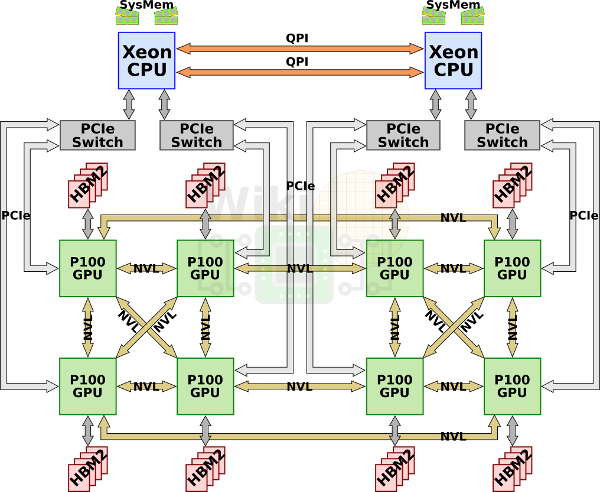
- DGX-1 服务器还将 GPU 之间的多条 NVLink 都集成到了服务器主板之上,整体布线方案干净利落。

NVLink 2.0 与 DGX-1 系统
2017 年,NVLink 2.0 与 V100 同期发布,单 Link 双向带宽提升到了 50GB/s(400Gb/s),单 V100 Link 接口增加到 6 个,使得单张 V100 的总带宽提高到了 6 * 50 = 300GB/s,是 NVLink 1.0 的近 2 倍。
将 NVLink 2.0 应用到 DGX-1 之后,其核心的 Cube-Mesh 拓扑依旧没有变。而每张 V100 新增的 2 个 Link 接口则用于倍化了一些 GPU 之间的互联带宽。如下图所示。
NVSwitch 全互联
NVSwitch 1.0 与 DGX-2 系统
经典的 Cube-Mesh 拓扑依旧无法实现 GPU-GPU 之间的全互联。直到 2018 年,NVIDIA 推出了 DGX-2 和 NVSwitch 1.0。
DGX-2 解决方案加倍了 v100 的数量到 16 张,同时 HBM2 升级到 32GB/块,共计 512GB,CPU 也升级为双路 2.7G 24 核 Xeon 白金 8168 CPU。其中最值得关注的就是 NVSwitch 技术。
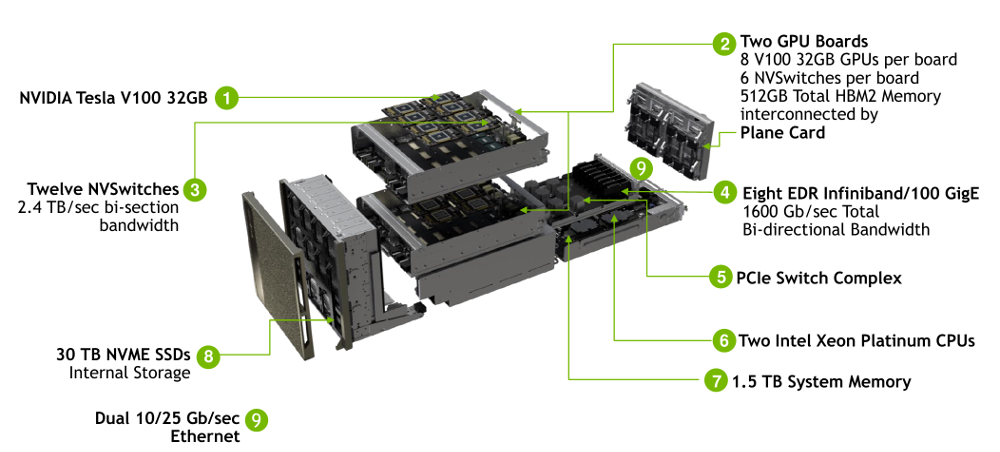
NVSwitch,即:NVLink Switch,作为单机内多个 GPU NVLink 的 Hub,本质是一块 ASIC 高速交换芯片,集成在 DGX/HGX 等 NVIDIA 独家整机方案中(区别于网络交换机)。下为集成了 4 张 NVSwitch 芯片的实物图。
NVSwitch 具有 18 个 NVLink Port,支持 NVLink 2.0,所以每个 Port 的带宽为双向 50GB/s,整体带宽为 900GB/s。其中,2 个 Port 预留用于连接 2 颗 CPU,剩余的 16 个 Port 用于连接 GPU。对于 V100(6 Link 口)而言,只需要 6 个 NVSwitch 即可实现 8 张 GPU 之间的 Full-Mesh 拓扑。如下图所示。

更进一步的,对于 DGX-2 而言,其具有 2 个 GPU Board(基板),共计 16 张 GPU,依旧可以通过 NVSwitch 1.0 来实现 16 张 GPU 和 2 颗 CPU 之间的 Full-Mesh 拓扑,如下图所示。
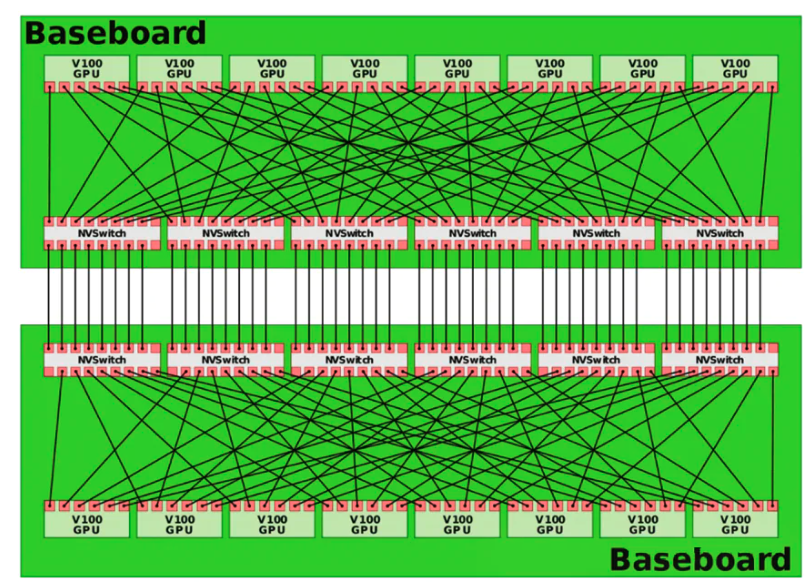
可见,NVSwitch 1.0 技术实现了全部 CPU-GPU、GPU-GPU 之间的单 Link 双向 50GB/s,单 GPU 300GB/s 的满带宽高速互联,使得 GPU 计算性能不再收到 PCIe 和 Cube-Mesh 拓扑的限制。
另外,NVSwitch Full-Mesh 拓扑还解决了 NVLink Cude-Mesh 的远程访问不一致性问题,在 DGX-2 中,每块 GPU 之间都以相同的速度和一致性延迟传输数据。
值得注意的是,NVSwitch 目前依旧是 NVIDIA 的闭源方案,其他厂商的服务器设备并不具备该特性。如果 NVIDIA 开放 NVSwitch 方案,那么在 AI 服务器行业中将会构建一种新的标准。
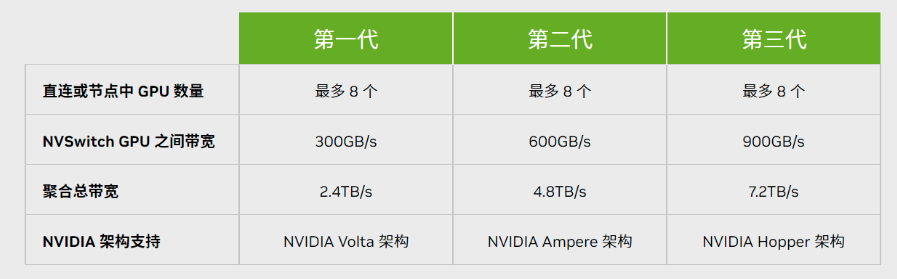
NVLink 3.0、NVSwitch 2.0 与 DGX A100
2020 年,NVIDIA 发布了 NVLink 3.0、NVSwitch 2.0,以及 A100 GPU。
- 每张 A100 具有 12 条 Link 接口,单 Link 双向 50GB/s(400Gb/s),单卡满带宽 600GB/s,比 NVLink 2.0 提升了 1 倍。
- 由于 Link 数量的增加,NVSwitch 2.0 的 Port 数量也增加到了 36 个,单 Port 双向 50GB/s。
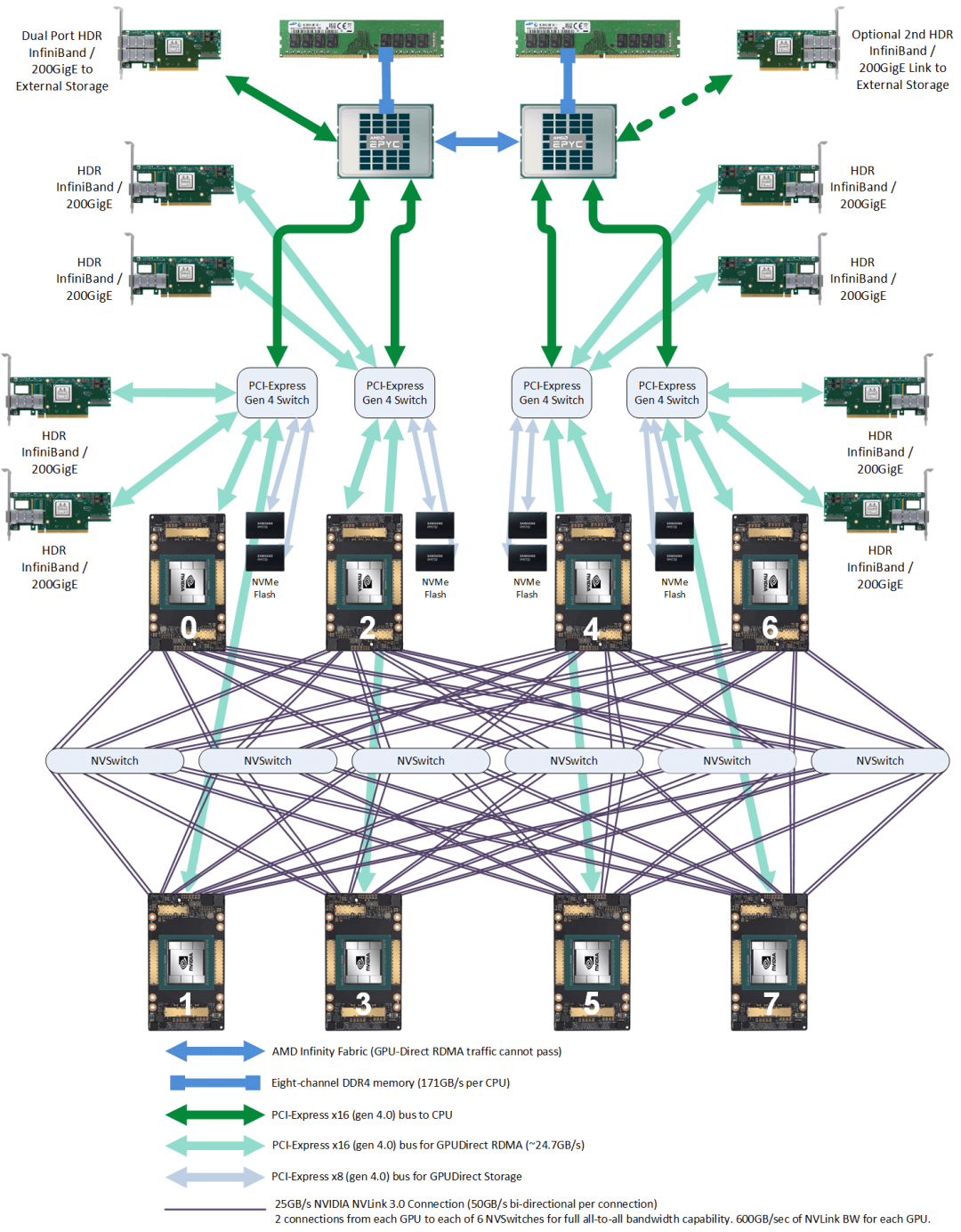
由 8 张 A100 和 4 个 NVSwitch 2.0 组成了 DGX A100 系统如下图所示。
- 2 张存储网卡:200G,PCIe 直连 CPU。用于从外部存储读写数据,例如读训练数据、写 checkpoint 等。以及用于作为 SSH 管理网络。
- 8 张 GPU 专属网卡:200G,PCIe Switch 互联。用于跨机传输 GPU 之间的数据。

NVLink 4.0、NVSwitch 3.0 与 DGX H100
2022 年,发布了 NVLink 4.0、NVSwitch 3.0 以及 H100 GPU。
- 每张 H100 具有 18 条 Link 接口,单 Link 双向 50GB/s(400Gb/s),单卡满带宽 900GB/s。
- 由于 Link 数量的增加,NVSwitch 2.0 的 Port 数量也增加到了 64 个,单 Port 双向 50GB/s。
DGX H100 系统由 8 张 H100 与 4 颗 NVSwitch 芯片组成,如下图所示。
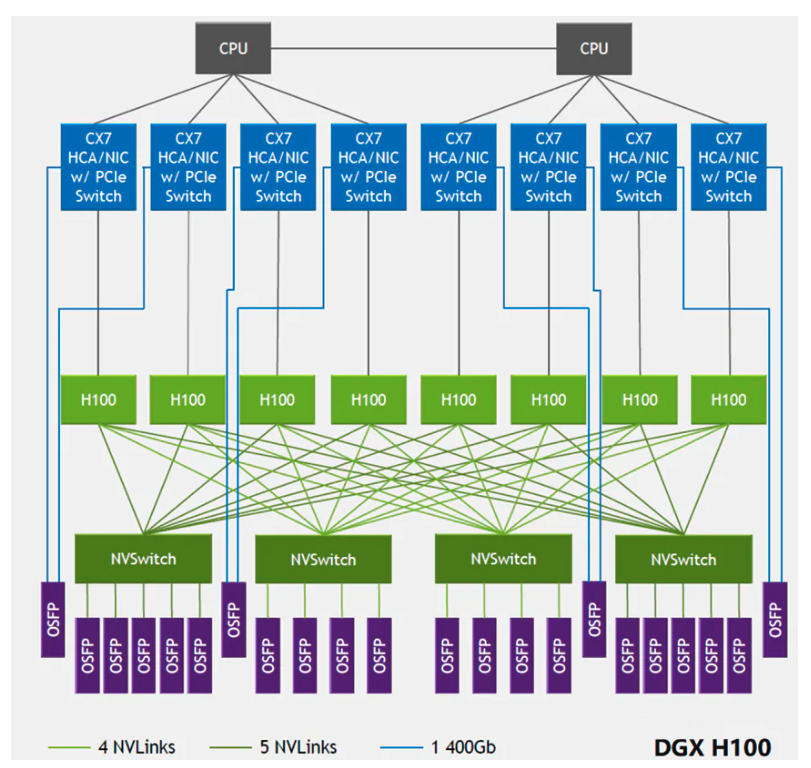
值得注意的是,从 NVSwitch 3.0 开始 NVIDIA 真的将 NVSwitch 芯片拿出来做成了交换机,是真正的 “NVLink Switch”,用于实现跨主机连接 GPU 设备。NVSwitch 3.0 集成了多个 800G OSFP 网络光模块,使得可以连接到 NVLink Switch。
NVSwitch v.s. PCIe Switch
NVSwitch v.s. PCIe Switch 拓扑
NVLink 性能迭代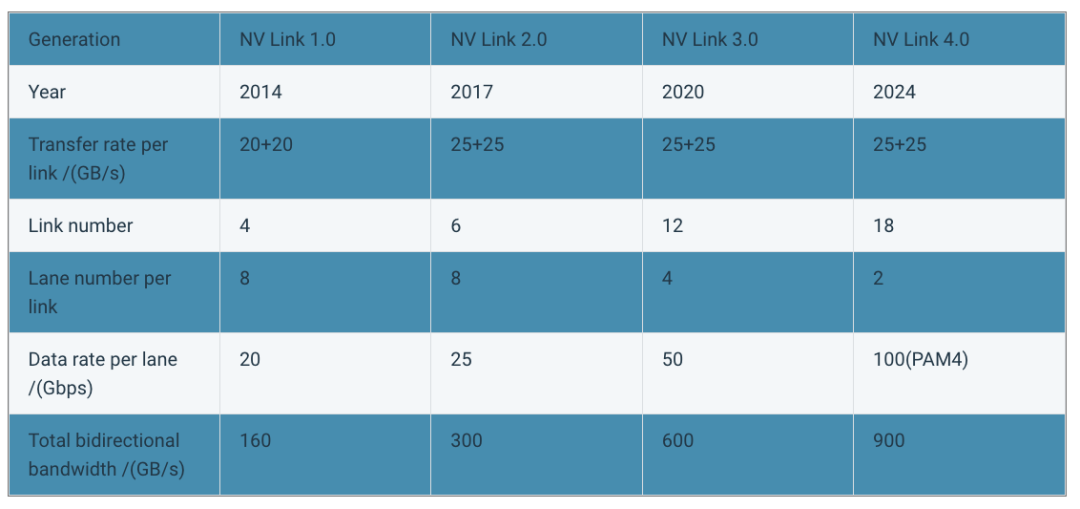
PCIe 性能迭代