|
在使用 dify 进行知识问答时,你是否遇到过这样的困扰:只想查询知识库中的某几个特定文档,系统却检索了库中全部内容,导致返回的信息冗余甚至不够精准?这种“全库扫描”式的检索不仅影响效率,还可能干扰最终的回答质量。 事实上,精准控制检索范围是一个强需求场景。例如,腾讯云推出的 智能问答(IMA) 就支持仅从指定文档中检索答案,大幅提升了问答的准确性和效率。那么,在 Dify 中如何实现类似能力? 本文将介绍如何巧妙利用 Dify 的 元数据(Metadata)功能,通过灵活配置文档标签,实现“指哪查哪”的精准检索,让你的知识问答更加高效可控。 工作原理1️⃣标记文档:通过元数据,给选中的文档打上同一个“标签”(如 UUID)。 2️⃣检索时筛选:在知识检索节点里,设置只搜索带这个标签的文档。 3️⃣动态调整:每次提问前,先更新这个标签(生成新的UUID),就能灵活控制每次搜索的范围。 新建元数据为Dify知识库开启元数据功能。在 知识库 页面,选择一个知识库点击进入。我们以公众号知识库为例。  点击 元数据 按钮,弹出如下元数据管理的对话框 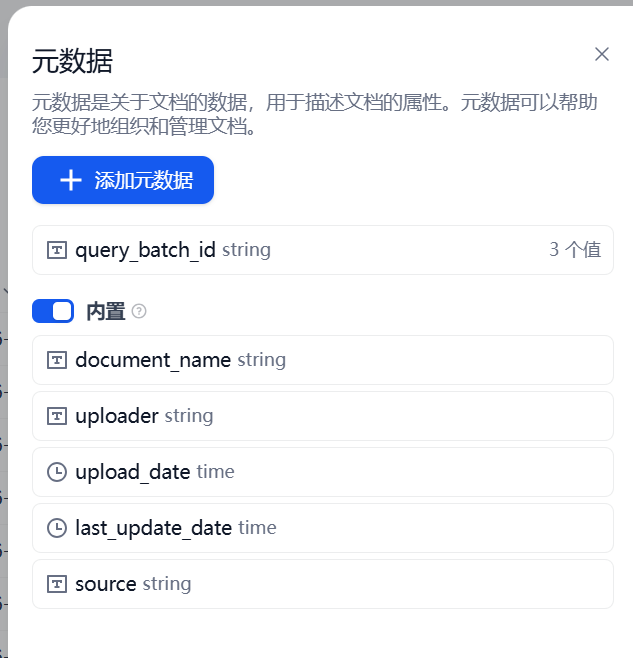 点击 新建元数据 按钮,新增一个名为query_batch_id的元数据  创建工作流 代码执行模块中,通过调用更新文档元数据的接口,更新文档的query_batch_id为最新的uuid。 importrequests
importuuid
defmain(dataset_id:str, document_ids:str)-> dict:
document_ids = document_ids.split(",")
url ="api:5001"
api_key ="dataset-sLRzvhU8GzqFd1fjZ1rqZi8o"
## your can get metadata_id from by get method ```GET /datasets/{dataset_id}/metadata```
metadata_id ='43d84af2-40b3-4158-b424-721e6049f1e8'
headers = {
'Authorization':f'Bearer{api_key}',
}
batch_id = uuid.uuid4().hex
json_data = {
'operation_data': [
{
'document_id': document_id,
'metadata_list': [
{
'id': metadata_id,
'value': batch_id,
'name':'query_batch_id',
"type":"string"
},
],
}fordocument_idindocument_ids
],
}
response = requests.post(f'http://{url}/v1/datasets/{dataset_id}/documents/metadata', headers=headers, json=json_data)
ifresponse.status_code !=200:
return{
"is_success":0,
"err_message":response.text,
"query_batch_id":""
}
return{
"is_success":1,
"err_message":"",
"query_batch_id":batch_id
}
知识检索节点打开 元数据过滤 功能,过滤条件使query_batch_id元数据,等于本次更新的uuid。  工作流测试我们选中了毕昇LLMs平台和Dolphine-API两份文档,来进行问答。这之前得手动从浏览器中找下知识库ID和文档ID。 先测试和两个文档都无关的问题,模型提示未检索到知识。  再测试一个和文档有关的问题,模型检索到了知识。 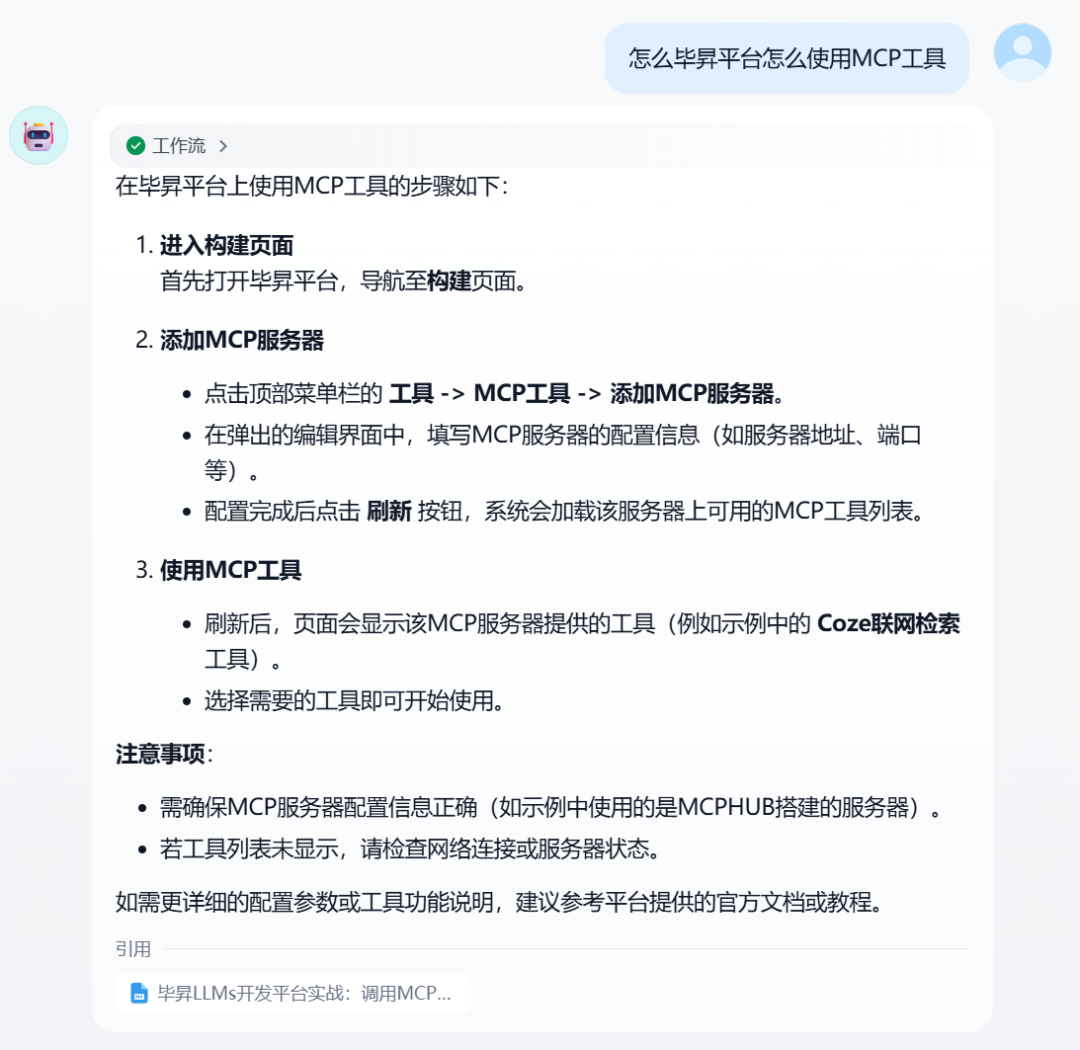 | 









