https://github.com/Encyclomen/HGMem
Improving Multi-Step RAG with Hypergraph-Based Memory for Long-Context Complex Relational Modeling
https://arxiv.org/pdf/2512.23959
港中大 & WeChat AI 联合团队

RAG双重暴击:“超长+全局推理”
|
|
|
|
|
用一段流水账 plain text 记录历史,丢细节、丢引用、丢结构 |
|
最多二元关系(A→B),无法表达“三元及以上”高阶关联 |
结果:在 100k+ token 的金融/法律/小说类文档里,一旦问题需要“全局 sense-making”(例如“为什么 Xodar 被送给 Carter 当奴隶?”),现有方法就像拼图只拼边缘,中间永远缺一块。
HGMEM——把“记忆”升级成“超图”
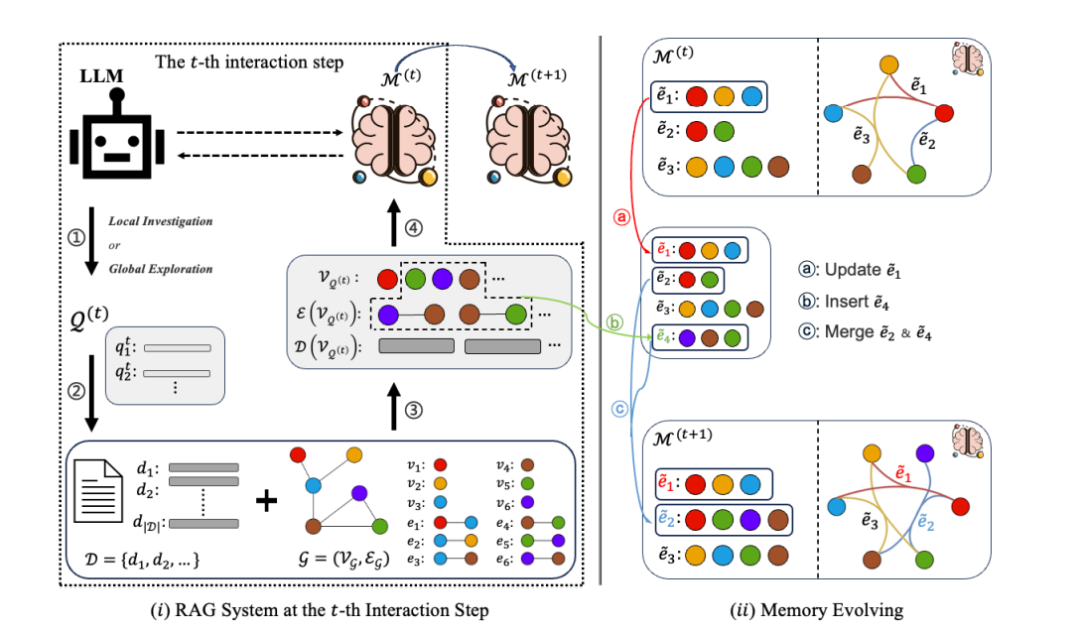 图1:左侧为第 t 步交互流程;右侧为超图记忆的演化示意
2.1 核心思想
把“工作记忆”不再当成一块硬盘,而是一张可动态生长、可高阶连接的超图:
- 每个超边(hyperedge)= 一个“记忆点”,可一次性连接 ≥2 个实体
- 支持三种原子操作:Update ∣ Insert ∣ Merge
- 每一步先“自我检查”→ 决定局部深挖 or 全局探索 → 检索 → 用 LLM 把新证据合并成更高阶的超边
2.2 关键模块一览
|
|
|
|
用 hypergraph-db 实时维护节点 & 超边 |
|
|
Local Investigation ↔ Global Exploration 切换 |
|
|
|
|
|
|
|
 图2 记忆演化案例 图2 记忆演化案例图2:Cowslip Moth 案例中,三条低阶事实被合并成一条“昆虫-植物共生”高阶关系
实验:成绩与成本双赢
3.1 主要结果
在 4 个超长文档基准(NarrativeQA / NoCha / Prelude / LongBench-V2)上,同样用 GPT-4o 或 Qwen-32B 做 backbone,HGMEM 全线 SOTA:
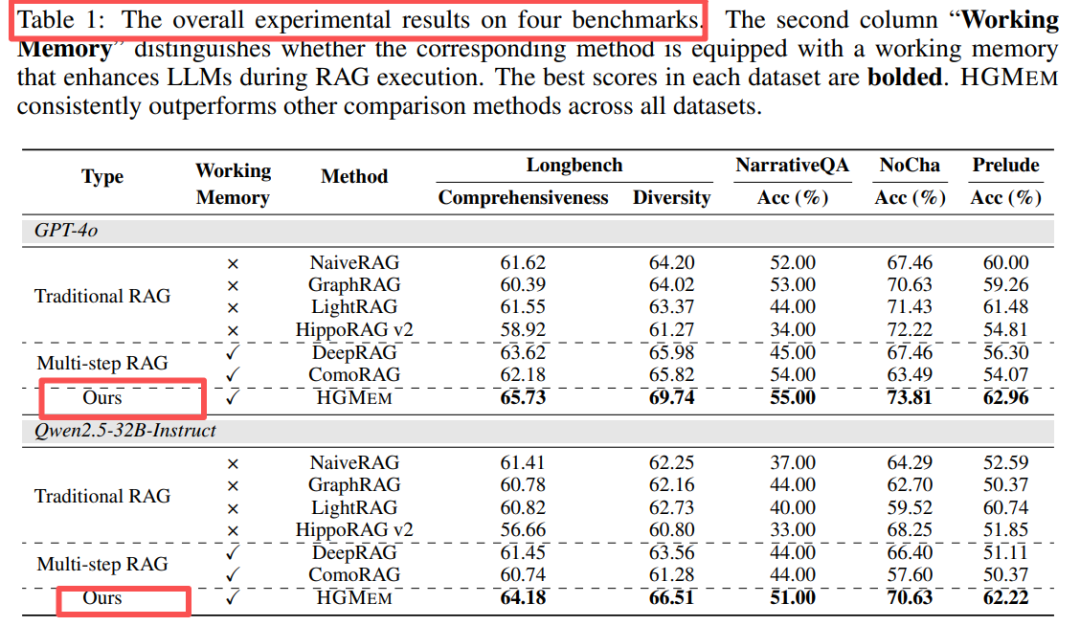 表1:↑ 表示合并操作带来的高阶关联对“sense-making”类问题尤为关键
3.2 成本对比
与同样带工作记忆的 DeepRAG / ComoRAG 相比,HGMEM 平均 token 消耗与延迟几乎持平,并未因“超图”而额外增负:
 表5 在线开销对比 表5 在线开销对比表5:合并操作仅增加 <7% token,却带来显著精度提升
一句话总结
HGMEM 把“记忆”从静态硬盘升级成动态超图,让大模型在超长文本里像侦探一样层层抽丝、合并线索、全局破案,而且不增成本——多步 RAG 的“记忆”就该这么玩!
| 









