
在检索增强生成(RAG)和 Agent 工作流中,文档解析的质量直接决定了下游链条的上限。然而,复杂的表格、潦草的手写体以及受损的扫描件一直是技术团队的痛点。2025 年 12 月,Mistral AI 发布了 Mistral OCR 3(模型型号 mistral-ocr-2512),旨在通过更小、更精悍的模型,解决大规模结构化文档处理的成本与精度难题。
本文将深入探讨 Mistral OCR 3 的核心升级、架构逻辑及其在 Document AI 生态中的地位。
核心能力:四大维度的精度飞跃
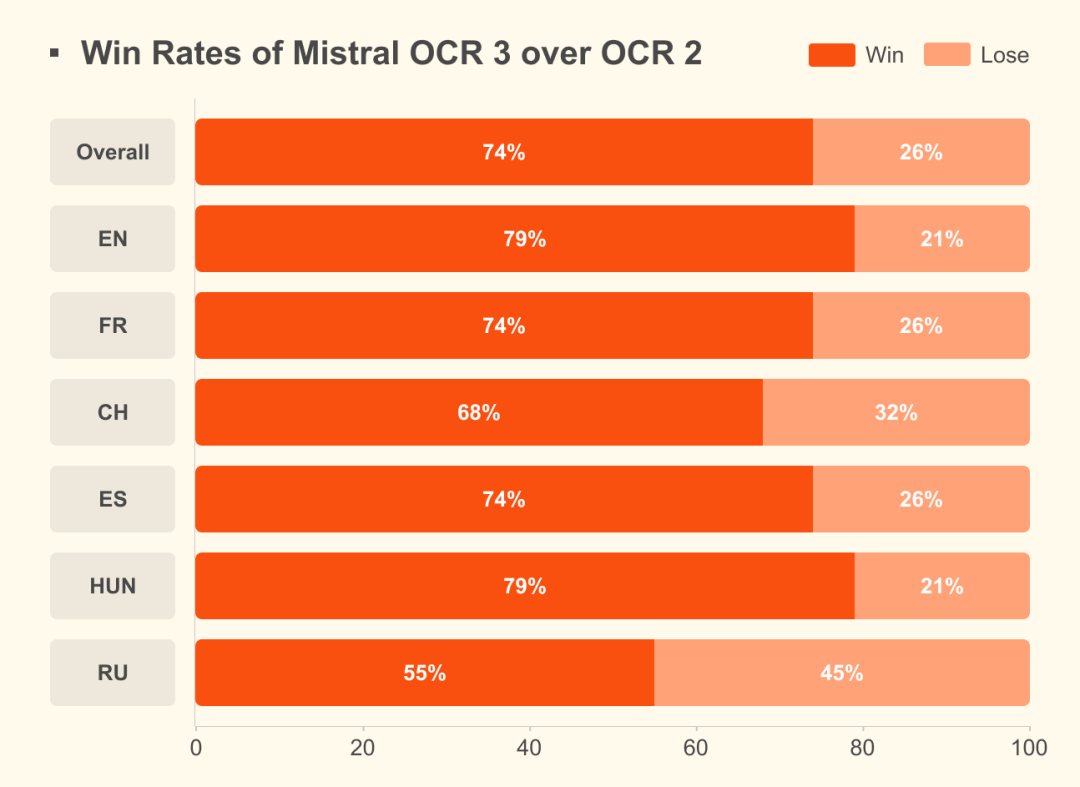
Mistral OCR 3 并非简单的增量更新。在针对真实业务场景的内部基准测试中,其综合胜率比前代产品 OCR 2 高出 **74%**。我们将其核心能力升级总结为以下四个方面:
- 手写体深度解析:支持对草书、混合标注以及在印刷模板上叠加的手写文字进行精准捕捉。这对于医疗处方、金融保险单据的自动化处理至关重要。
- 高密度表单识别:显著提升了发票、收据和合规表格中复选框、标签及紧凑条目的检测能力。
- 扫描件的鲁棒性:针对低 DPI、图像压缩伪影、纸张倾斜或背景噪声等恶劣输入环境,表现出更强的容错性。
- 复杂表格重构:这是本次更新的重头戏。它不仅能提取数据,还能重构包含跨行、跨列(colspan/rowspan)、多级表头和嵌套层级的 HTML 表格结构。
数据流结构:为 RAG 架构原生设计
Mistral OCR 3 的输出策略非常明确:为下游大模型提供“易读”且“保序”的数据。其 API 默认返回 Markdown 格式,这在当前的大模型语境下是公认的最佳上下文表征方式。
1. 统一的输入接口
开发者可以通过单一 API 端点处理多种格式,包括 PDF、PPTX、DOCX 以及各种图像格式(PNG, JPEG, AVIF)。
2. 结构化的 JSON 响应
模型的响应对象包含一个 pages 数组,每个页面都经过精细化的结构拆解。以下是典型的输出逻辑:
{
"pages": [
{
"index": 0,
"markdown": "### 季度财务报告\n\n[tbl-3.html](tbl-3.html)",
"images": [...],
"tables": [
{
"id": "tbl-3",
"content_html": "<table>...</table>"// 包含完整的 colspan 和 rowspan
}
],
"dimensions": { "height": 1120, "width": 800 }
}
],
"usage_info": { "pages_processed": 1 }
}
关键逻辑解析: 通过在 Markdown 中嵌入占位符(如 ![img-0.jpeg]),Mistral OCR 3 实现了文本与多媒体内容的物理对齐。当开启 table_format="html" 时,模型会生成高保真的 HTML 源码。这种设计规避了传统 OCR 识别表格时容易出现的“列对齐错误”问题,确保了 RAG 管道在检索表格数据时的精确度。
开发实战:从 Playground 到大规模生产
Mistral Document AI 将 OCR 3 整合进了全链路工具栈中。
|
|
|
| Studio Playground |
|
无需代码,直接上传 PDF 即可获取 Markdown 或 JSON。 |
| Batch API |
|
|
| BBox Extraction |
|
获取文本块和元素的边界框(Bounding Boxes)。 |
| Structured Annotations |
|
结合自定义 Schema,直接将非结构化文档转为特定业务对象。 |
成本效益分析:激进的价格策略
Mistral AI 显然试图通过高性价比策略抢占企业级市场。
- Batch 模式:通过
/v1/batch 端点,标准 OCR 价格降至 1 美元 / 1,000 页。
这种价格体系相比于某些主流云服务商的 OCR 接口具有显著优势,尤其是在处理百万级页面的大型项目时,成本优势会被无限放大。
结语
Mistral OCR 3 的核心竞争力不在于追求单一的字符识别率(OCR 领域的边际效应已递减),而在于结构化还原能力。它通过输出保留布局的 Markdown 和语义清晰的 HTML 表格,打通了纸质文档与向量数据库之间的“最后一公里”。










