|
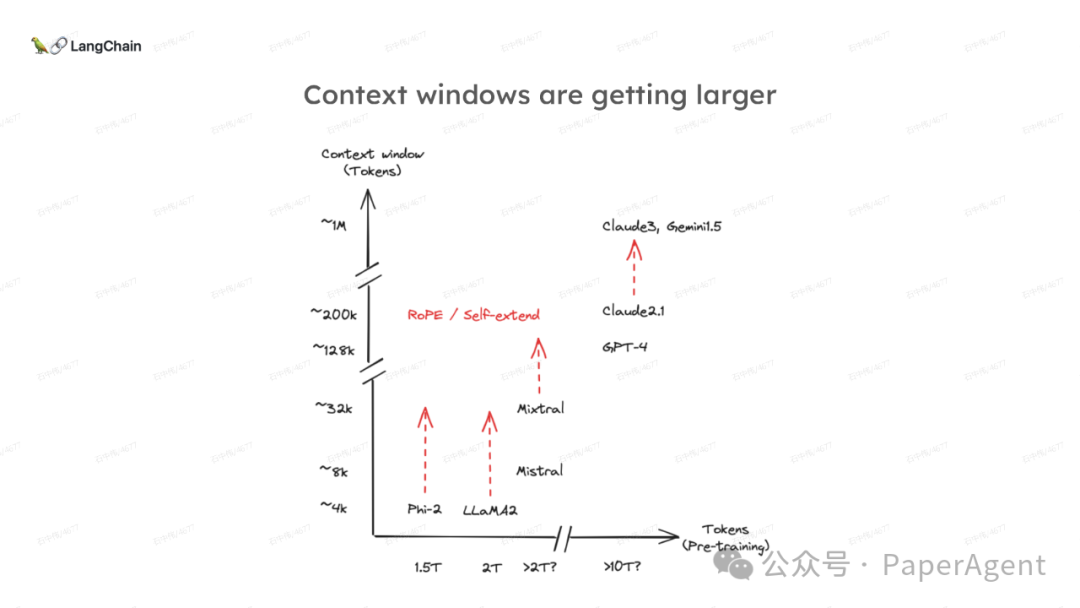
随着大模型上下文窗口扩大到100K-200K Token(开源)或者200万-1000万字(商业),不少人开始质疑检索增强生成(RAG)是否已经过时? | 企业机构 | 模型名称 | 上下文长度 | 开/闭源 | 是否中文 | | 360 | 360Zhinao-7B-Chat-360K | 360K | 开源 | 是 | | 猎户星空 | Orion-14B-LongChat | 200K-320K | 开源 | 是 | | 元象XVERS | XVERSE-Long-256K | 256K | 开源 | 是 | | 上海AI Lab | InternLM2-Chat-7B/20B | 200K | 开源 | 是 | | 零一万物 | Yi-6B-200K | 200K | 开源 | 是 | | 百川智能 | Baichuan2-192K | 192K | 开源 | 是 | | NousResearch | Yarn-Mistral-7b-128k | 128K | 开源 | 否 | | Anima | Anima-7B-100K | 100K | 开源 | 否,中文需要申请 | | Anthropic | Claude 2.1 | 200K | 闭源 | 是 | | 智谱AI | GLM4 | 128K | 闭源 | 是 | | OpenAI | ChatGPT-Turbo | 128K | 闭源 | 是 | | 月之暗面 | Kimi Chat | 20万字 | 闭源 | 是 | | 月之暗面 | Kimi Chat Longer | 200万字 | 闭源 | 是 | | 通义千问 | qwen | 1000万字 | 开/闭源 | 是 |
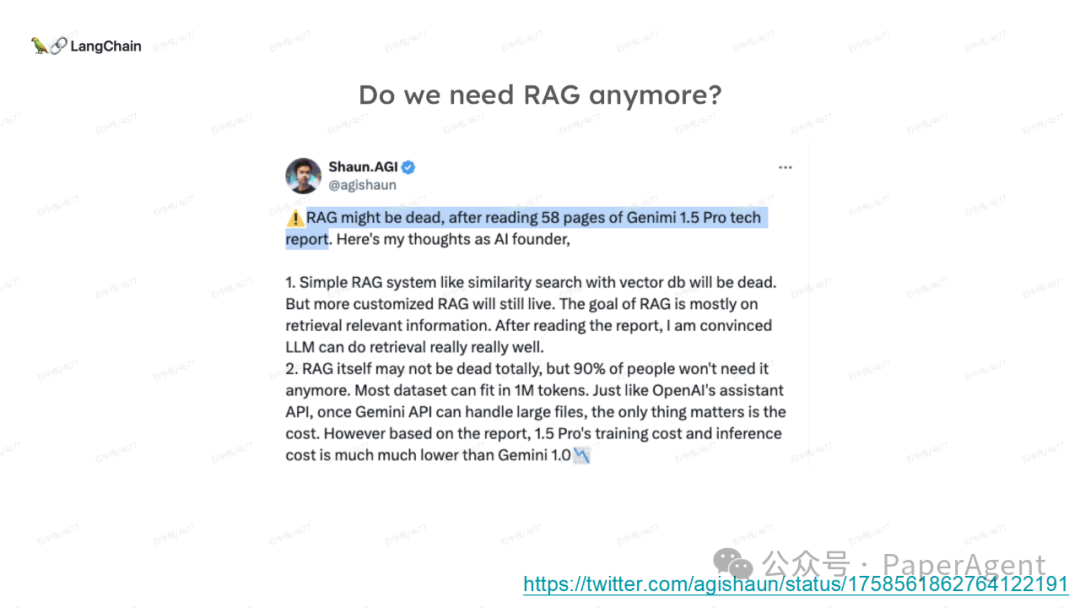
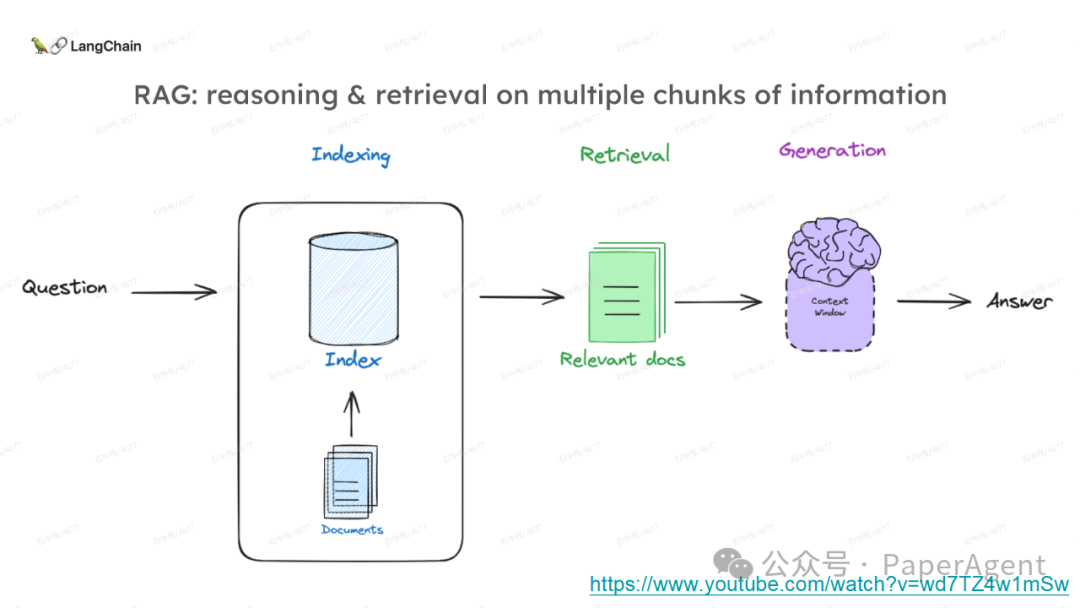
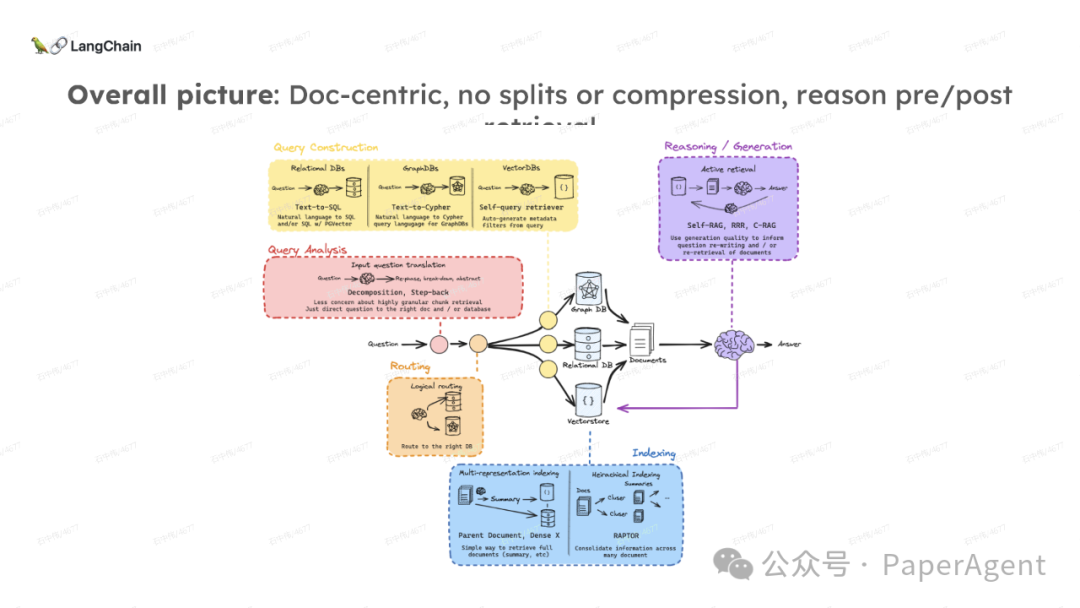
LangChain团队(Lance Martin 软件工程师)结合几个最新研究项目成果来探讨、分析这个问题。通过多针“大海捞针”方法,深入分析了长上下文大模型在事实推理和检索(reasoning & retrieval in long context LLMs)方面的局限性,接着分析了长上下文给RAG带来的新变化,如以文档为中心的索引技术(RAPTOR+Long embeddings)和RAG的流程变化(Self-RAG、CRAG)。 
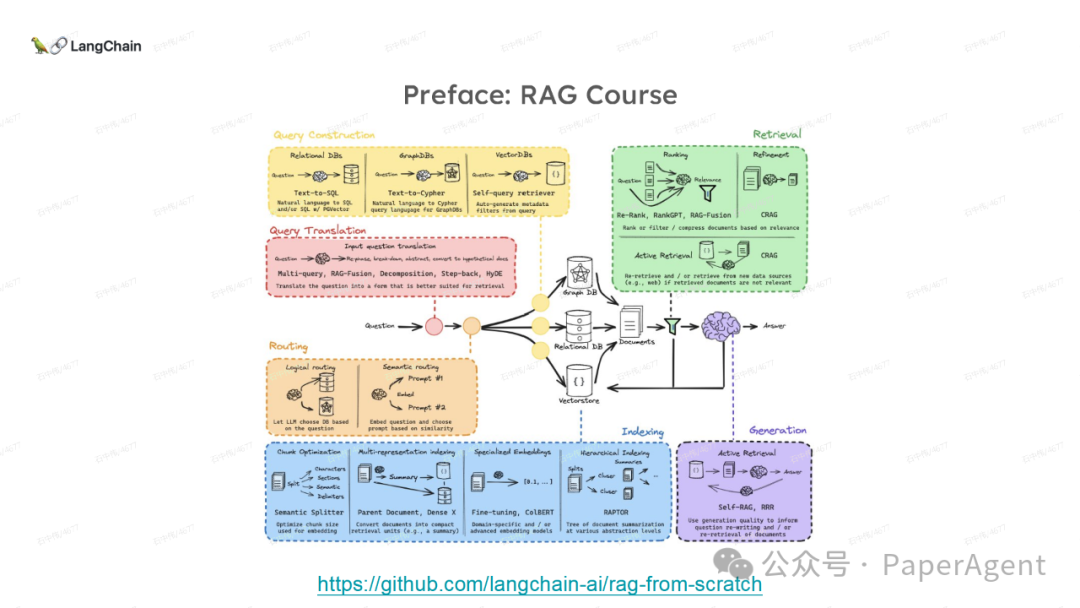
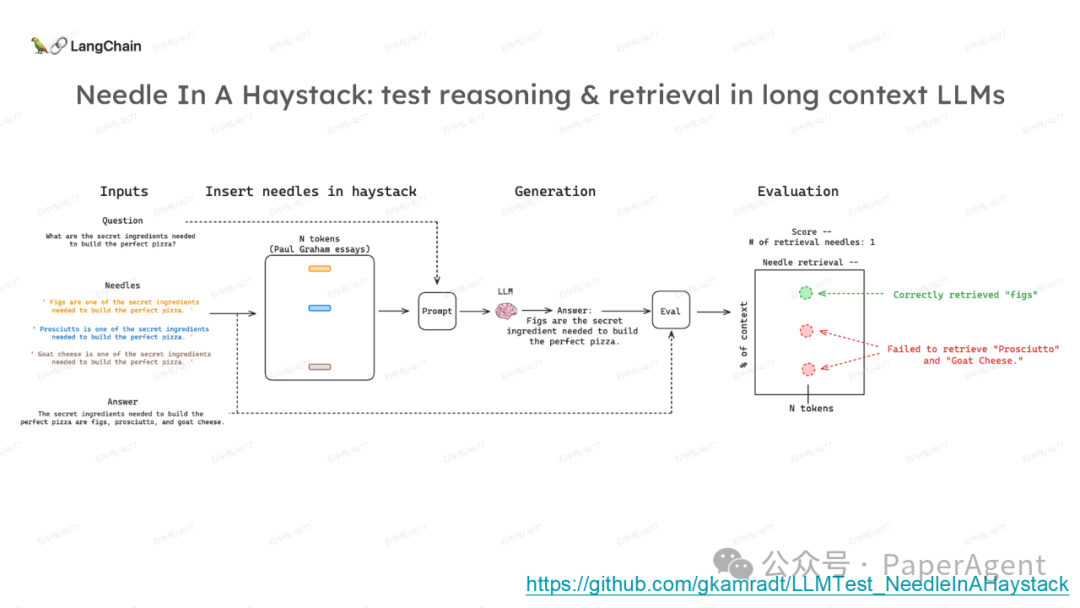
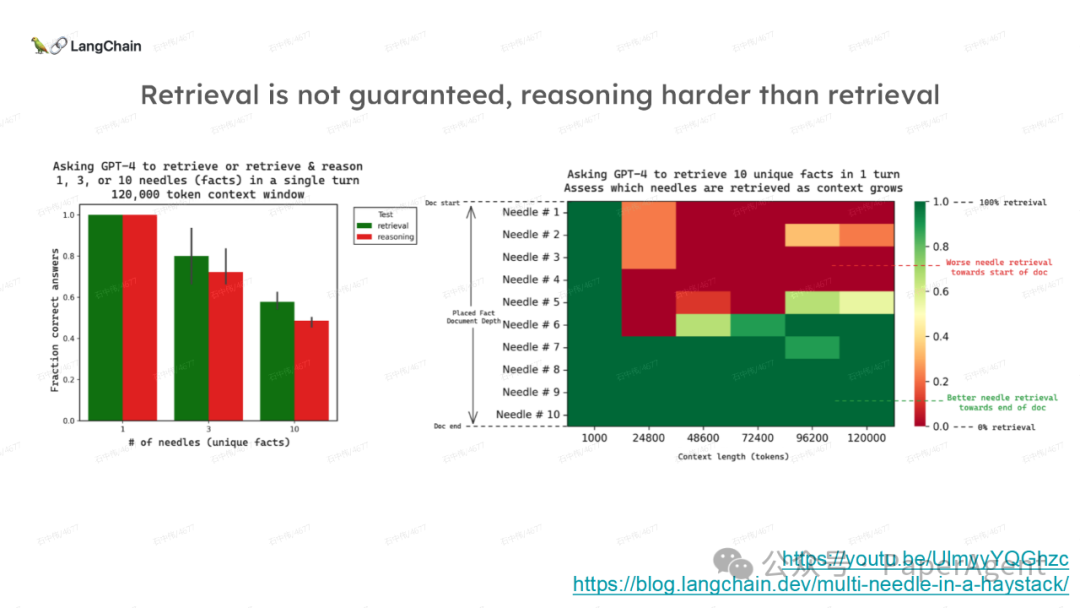

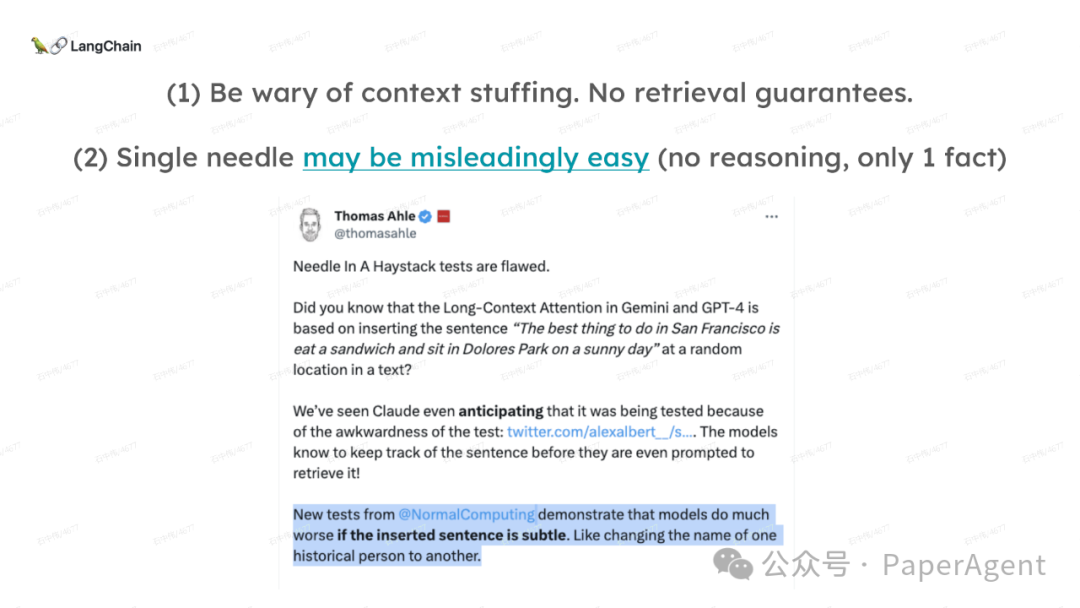

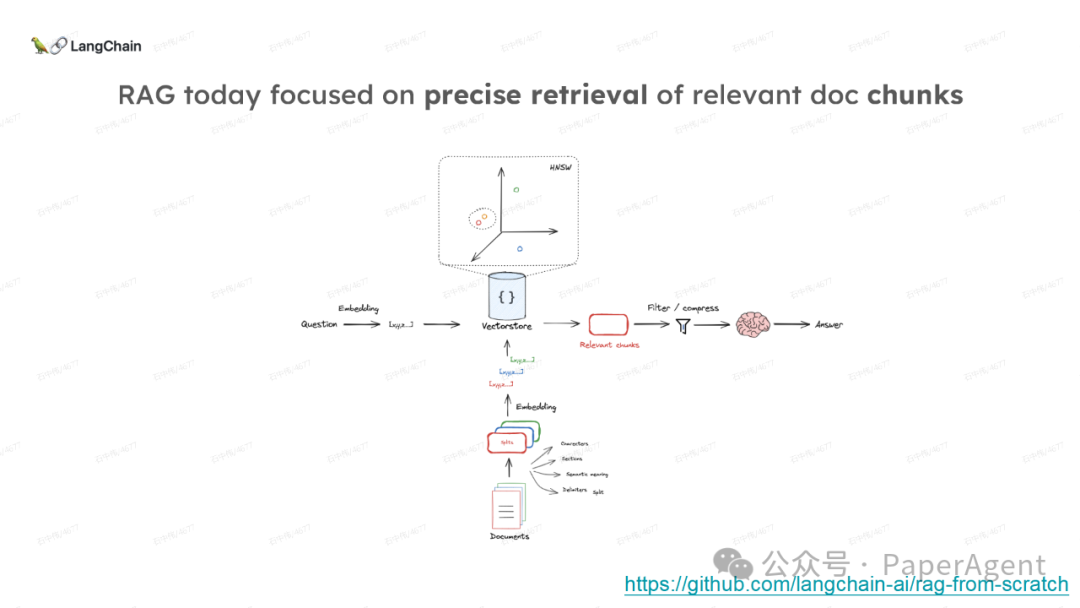
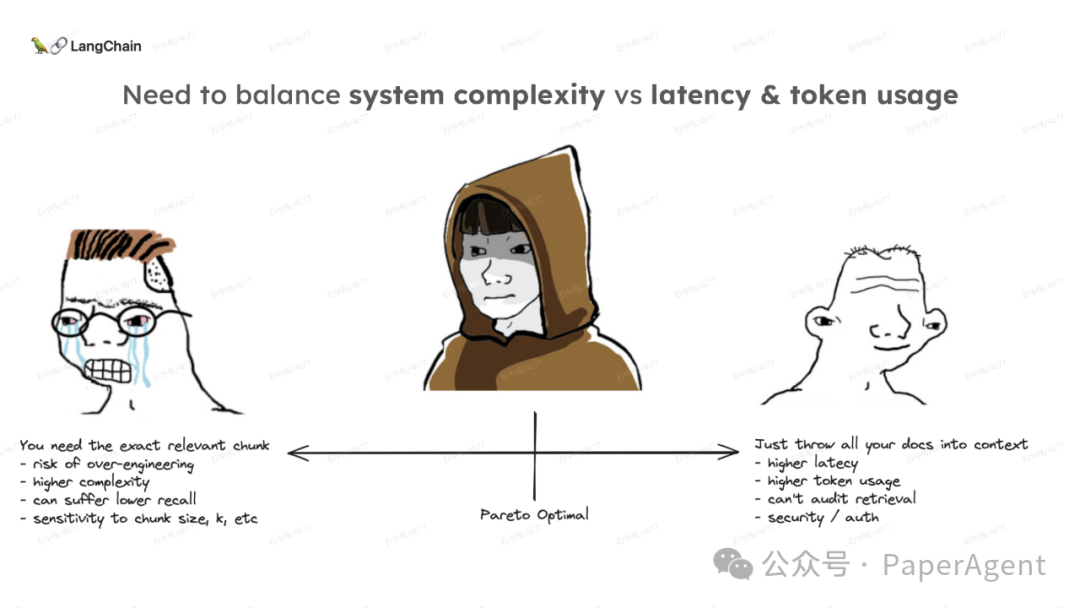
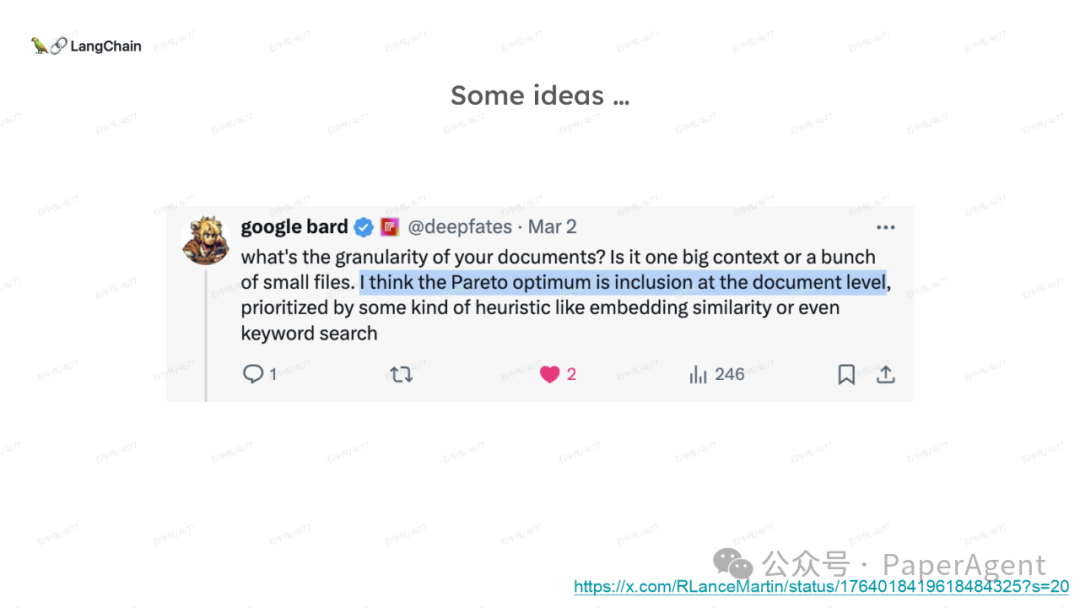
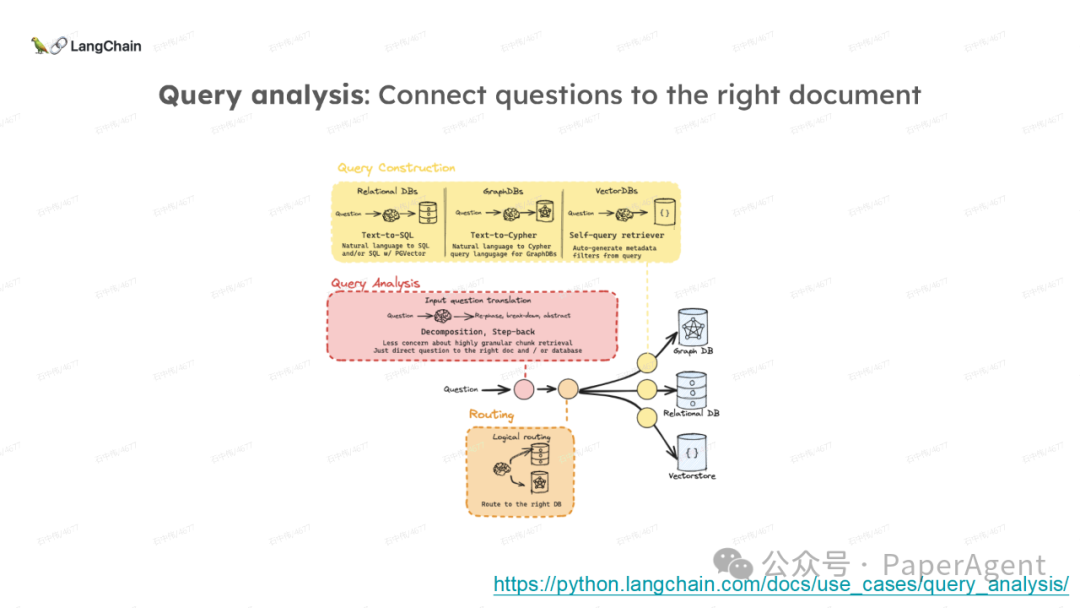
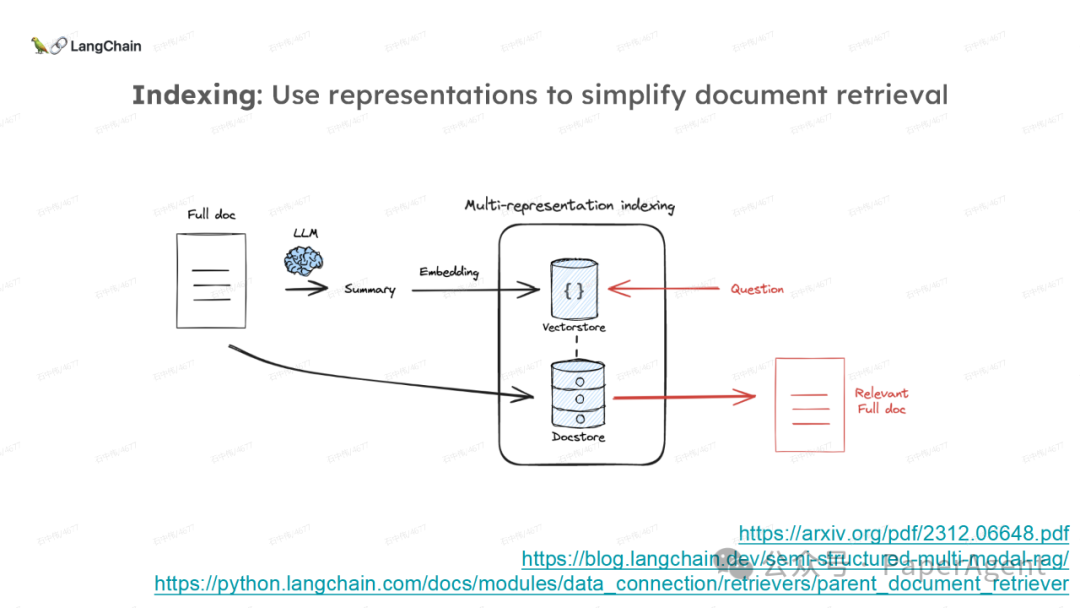
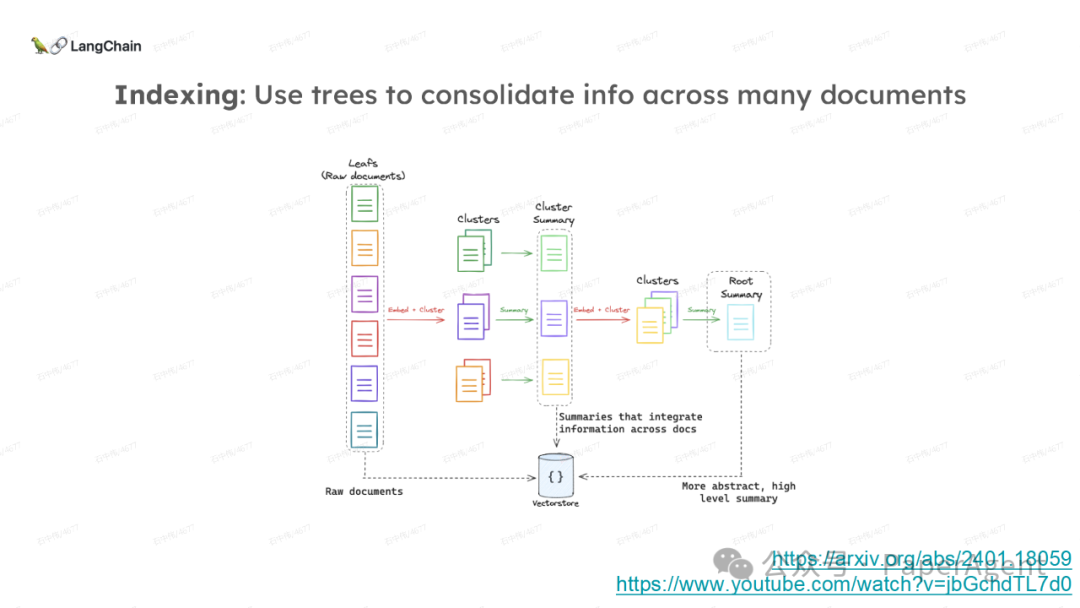
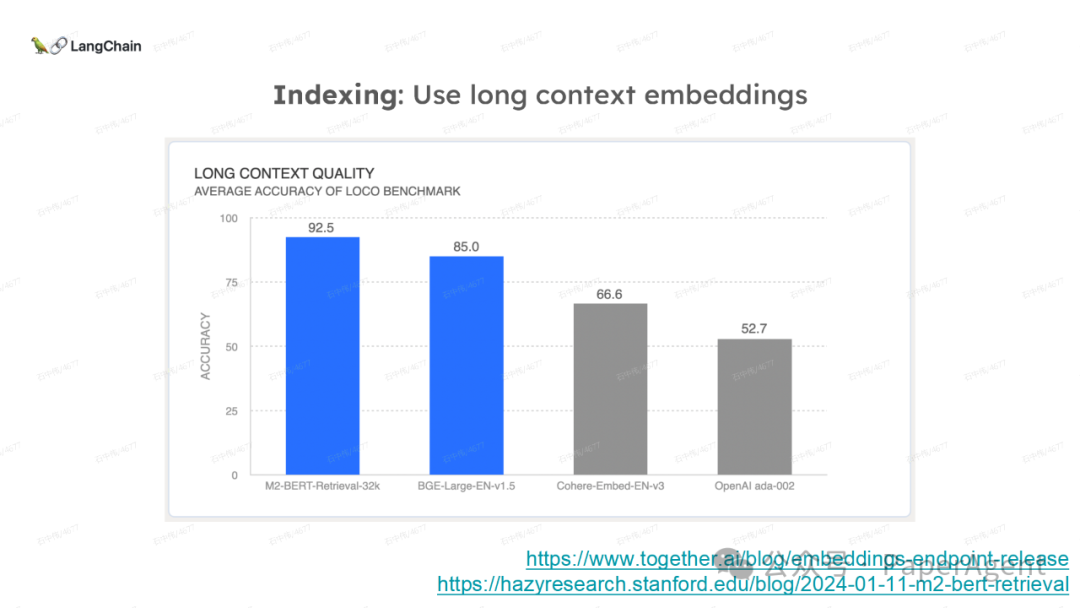
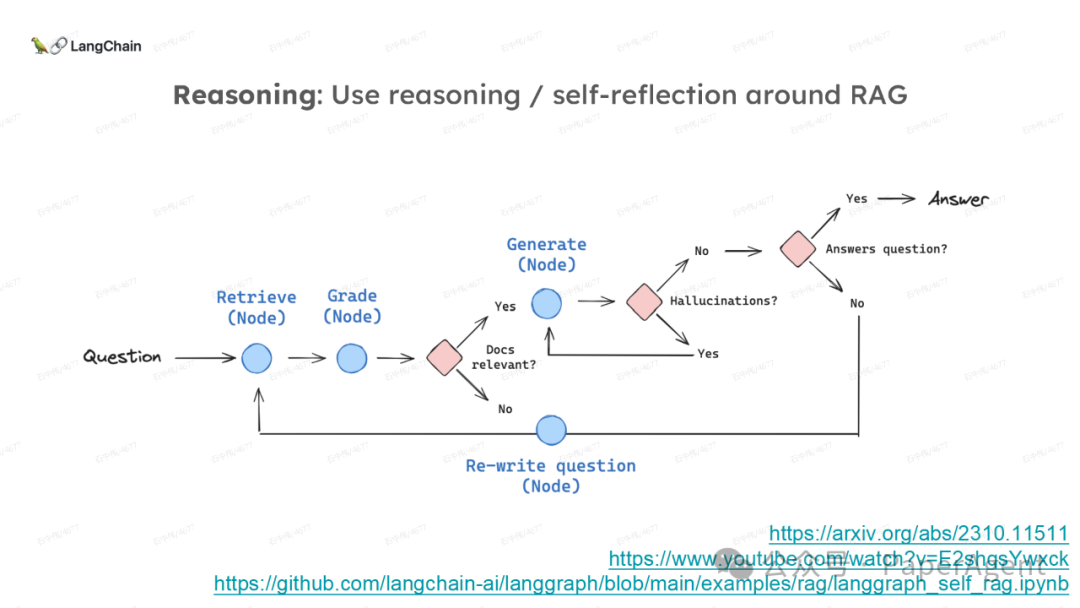
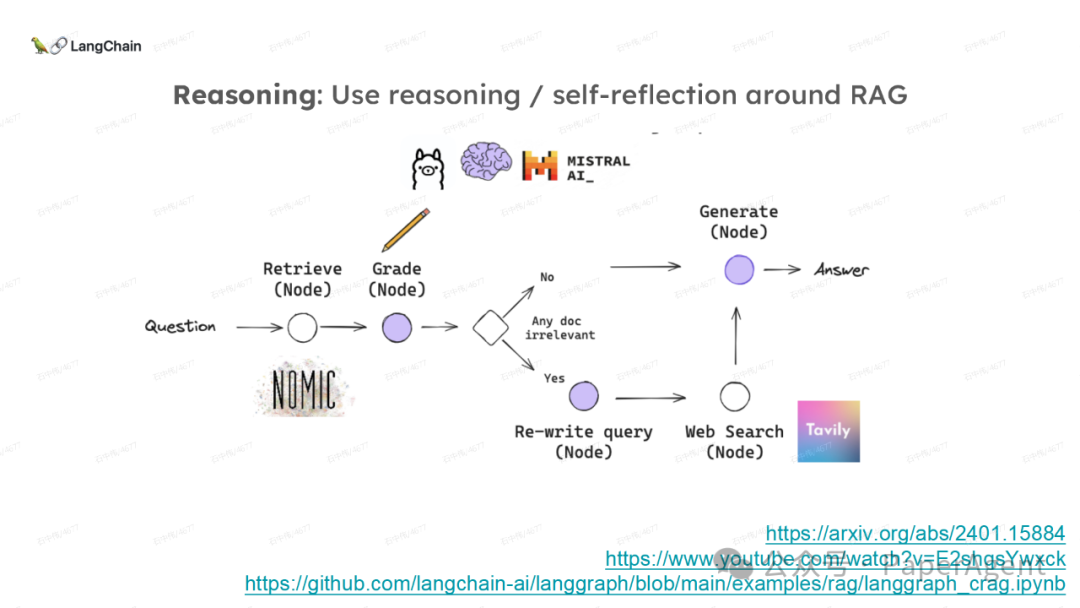
多针“大海捞针”:https://blog.langchain.dev/multi-needle-in-a-haystackChallengemayberecencybiasinLLMs:https://arxiv.org/pdf/2310.01427.pdfRAGfromscratch:https://github.com/langchain-ai/rag-from-scratchRAG新突破RAPTOR:https://github.com/parthsarthi03/raptorDenseXRetrieval:https://arxiv.org/pdf/2312.06648.pdfTogetherEmbeddings:https://www.together.ai/blog/embeddings-endpoint-releaseSelf-RAG:https://arxiv.org/abs/2310.11511CRAG:CorrectiveRetrievalAugmentedGenerationhttps://arxiv.org/abs/2401.15884
| 









