ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">检索增强型文本生成(Retrieval-Augmented Generation, RAG)在大型语言模型(Large Language Models, LLMs)中的应用。主要内容概要:
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">RAG范式:从检索的角度将RAG研究领域组织成四个主要阶段:预检索、检索、后检索和生成。 预检索:讨论了索引、查询操作和数据修改等任务,这些任务为有效的数据和查询准备奠定了基础。 检索:介绍了搜索和排名的策略,包括传统检索方法和利用预训练语言模型(如BERT)来提高语义理解。 后检索:包括重新排名和过滤,旨在优化初始检索文档的选择,以提高文本生成的质量。 生成:生成阶段的任务是利用检索到的信息提高生成响应的质量,包括增强和定制步骤。 评估方法:介绍了评估RAG系统的方法,包括对检索和生成方面的评估。 ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">通过提供RAG领域的全面框架,旨在促进未来的研究,并从检索的角度阐明了RAG的核心概念,以便于进一步探索和创新。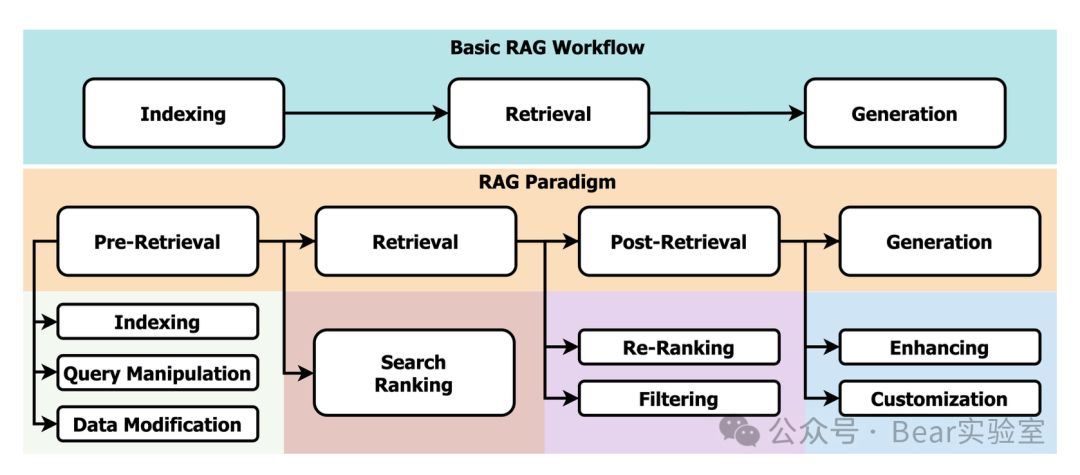
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: center;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">RAG范式ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">RAG(Retrieval-Augmented Generation)是一种结合了信息检索和文本生成的方法,旨在提高大型语言模型(LLMs)的性能和表现,弥补LLMs的不足。RAG通过动态地整合最新的外部信息来解决LLMs的静态知识限制,从而生成更准确、可靠的输出。RAG范式通常包含以下几个主要阶段:
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">预检索(Pre-Retrieval): 这个阶段是检索过程的开始,包括索引的创建、查询的操纵和数据的修改。索引创建涉及将外部信息源组织成可以快速检索的格式。查询操纵旨在改善用户查询以更好地匹配索引数据。数据修改则可能包括去除不相关信息或添加元数据以提高检索效率。 检索(Retrieval): 后检索(Post-Retrieval): 生成(Generation):
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: center;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">预检索(Pre-Retrieval)ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">预检索(Pre-Retrieval)是检索增强型文本生成(RAG)中的一个阶段,它为数据和查询的有效检索做准备。索引(Indexing):创建一个包含外部来源的索引,这为检索相关信息提供了基础。索引过程包括文本规范化(如分词、词干提取和去除停用词),以及将文本段落组织成句子或段落,以便于更精确的搜索。 查询操作(Query Manipulation):对用户查询进行调整以更好地匹配索引数据。这可能包括查询重构(改写查询以更贴近用户意图)、查询扩展(通过同义词或相关术语扩展查询以捕获更多相关结果)以及查询规范化(解决拼写或术语上的差异以实现一致的查询匹配)。 数据修改(Data Modification):增强检索效率的另一个关键步骤,包括预处理技术,如去除不相关或冗余信息以提高结果质量,以及通过添加元数据等额外信息来丰富数据,从而提高检索内容的相关性和多样性。
预检索阶段的目的是为了确保在实际的检索阶段能够高效地访问和检索到相关信息。这个阶段的优化直接影响到检索系统的性能,因此它是RAG工作流程中不可或缺的一部分。通过精心准备数据和查询,预检索阶段有助于提高检索到的信息的相关性和准确性,从而为生成阶段提供更高质量的输入。
检索(Retrieval) 在检索增强型文本生成(RAG)中,检索(Retrieval)阶段是核心环节,它涉及以下关键步骤: 搜索与排名(Search & Ranking):这一步骤使用搜索算法浏览索引数据,寻找与用户查询相匹配的文档。在识别出相关文档后,接下来的过程是对这些文档进行初步排名,根据它们与查询的相关性进行排序。 检索策略:检索阶段可能采用不同的策略,包括利用传统的检索算法(如BM25算法)或使用预训练的语言模型(如BERT)来更好地理解查询的语义信息。这些模型通过考虑词汇的语义相似性来改进搜索的准确性。 语义理解:在检索中,语义理解是至关重要的,它允许系统不仅根据关键词的频率和存在性,而且根据词汇的上下文含义来评估文档的相关性。 向量距离测量:现代检索系统通常会计算文档和查询之间的向量距离,结合传统的检索指标和语义理解来产生既相关又符合用户意图的搜索结果。 多跳检索(Multi-hop Retrieval):一些系统可能采用多跳检索策略,通过多轮检索来迭代地改进检索结果的准确性。
检索阶段的目标是找到与用户查询最相关的文档,并将这些文档作为输入传递到RAG的下一个阶段——后检索(Post-Retrieval)。在后检索阶段,这些文档可能会经过重新排名和过滤,以进一步优化最终用于文本生成的文档集。检索阶段的效率和准确性对整个RAG系统的性能至关重要,因为它们直接影响到生成文本的相关性和质量。
后检索(Post-Retrieval) 后检索(Post-Retrieval)发生在检索阶段之后。后检索阶段的目的是优化初始检索到的文档,以提高文本生成的质量。这个阶段主要包括两个关键步骤: 重新排名(Re-Ranking):
过滤(Filtering): 后检索阶段对于提升RAG系统生成文本的质量至关重要,因为它确保了生成模型使用的是经过精炼和高度相关的信息。完成重新排名和过滤后,选定的文档将用于生成阶段,生成模型将结合这些文档和用户的查询来产生最终的输出文本。 在整个RAG过程中,后检索阶段充当了检索阶段和生成阶段之间的桥梁,通过提升信息的相关性和准确性,为生成阶段提供更高质量的输入。
生成(Generation) 在检索增强型文本生成(RAG)中,生成(Generation)阶段是最后一个环节,涉及将检索到的信息和用户查询结合起来,以产生一个连贯、相关并满足用户需求的文本输出: 增强(Enhancing):
定制(Customization): 生成文本: 质量控制: 后处理: 生成阶段是RAG流程中至关重要的一步,因为它直接关系到最终用户的体验。生成的文本不仅要准确传达检索到的信息,还要以一种对用户有用和可接受的方式呈现。此外,生成阶段还可能涉及到对话生成、摘要、问答等多种形式的文本生成任务。
评估(Evaluation) 评估(Evaluation)检索增强型文本生成(RAG)系统通常涉及多个方面,以确保系统在各个方面都能达到预期的性能。一些评估RAG系统的方法: 检索基础方面(Retrieval-based Aspect):
Accuracy:衡量检索文档在提供正确信息方面的精确度。 Rejection Rate:评估系统在找不到相关信息时拒绝回答的能力。 Error Detection Rate:评价模型识别和忽略检索文档中错误或误导信息的能力。 Context Relevance:评估检索文档与查询的相关性。
生成基础方面(Generation-based Aspect): BLEU:衡量生成文本的流畅性和与人类产生文本的相似度。 ROUGE-L:量化文本与参考摘要的重叠,评估文本捕获主要思想和短语的能力。 Exact Match (EM)和F1 Score:分别确定完全正确答案的百分比和提供精确和召回的平衡评估。
多维度评估框架: RAGAS:评估RAG系统的生成文本质量、检索文档的相关性以及生成内容的忠实度。 ARES:改进RAGAS,增加了置信区间和对排名准确性的评估。 RECALL:评估模型对外部反事实知识的鲁棒性,包括响应质量和错误检测率。 RGB:评估RAG对LLMs的影响,包括噪声鲁棒性和信息整合的准确性。
特定能力评估: 抗误导性评估: 鲁棒性评估: 任务特定评估: 用户反馈和先前评估: 这些评估方法不仅考虑了RAG系统在检索和生成方面的性能,还考虑了系统的鲁棒性、抗误导性以及在特定任务上的表现。通过这些多维度的评估,开发人员可以更好地理解RAG系统的优势和局限性,从而指导未来的研究方向和模型改进。
|










