微软发布了 Phi-3 模型,XTuner 团队对 Phi-3 微调进行了光速支持!!!开源同时社区中涌现了 Phi-Tutorial 手把手教大家使用 XTuner 微调 Phi-Tutorial 模型。
XTuner:http://github.com/InternLM/XTuner
Phi-Tutorial:https://github.com/SmartFlowAI/Phi-Tutorial/
欢迎 Star
Phi-3 概览
- 微软研究院紧随 Llama-3发布后,迅速发布了Phi-3系列模型的技术报告。
- Phi-3系列包括三个尺寸的模型:Phi-3-mini、Phi-3-small、Phi-3-medium。
- 训练数据量:使用了3.3T Tokens的训练数据。
- 上下文长度:默认上下文长度为4K,但通过LongRope技术可扩展至128K。
- 性能表现:在各类基准和内部测试中,其性能可与Mixtral 8x7B和GPT-3.5等模型相媲美。
- 应用优势:主打“小而精”,4位量化的Phi-3-mini可以在带有A16仿生芯片的iPhone上运行,每秒生成超过12个token。
- Phi-3-Small和Phi-3-Medium模型的特点:
- 参数规模:Phi-3-Small拥有7B参数量,而Phi-3-Medium则拥有14B参数量。
- 词汇量与上下文长度:Phi-3-Small具有100,352个词汇量,默认上下文长度为8K;Phi-3-Medium使用与Phi-3-mini相同的分词器和架构。
- 训练数据量:Phi-3-Medium的训练数据量为4.8T Tokens。
- 能力表现:根据描述,Phi-3-Small和Phi-3-Medium的能力均显著高于Phi-3-Mini。
根据各类基准和内部测试的结果来看,其总体性能可以与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美(phi-3-mini 在 MMLU 上达到 69%,在 MT-bench 上达到 8.38)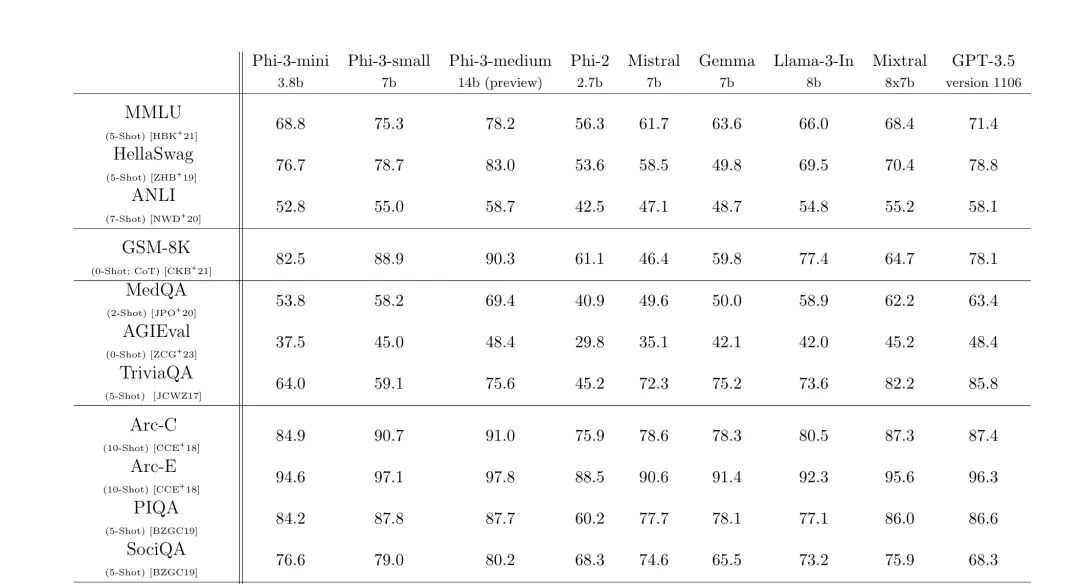
XTuner 显存门槛测试
在正式微调 Phi-3 小助手认知之前,我们先来看一下 XTuner 团队光速测试微调 Phi-3 所需要的显存门槛。 从上表中我们可以发现
从上表中我们可以发现
- 全量微调 4k 上下文的 Phi-3 时,如果直接使用 ZeRO3 训练,至少要两张 80G 的显卡;但借助 XTuner 提供的序列并行功能,最小显存门槛从 2 * 80GB 下降到 2 * 40GB。
- QLoRA 微调 128k 上下文的 Phi-3 时,在开启序列并行设置从 1 设置为 2 后,最小显存门槛从 80GB 下降到 2 * 40GB 或者 4 * 24 GB(4 张 3090 能玩)。
实践教程
Web Demo 部署
本小节将带大家手把手在 InternStudio 部署 Phi-3 Web Demo。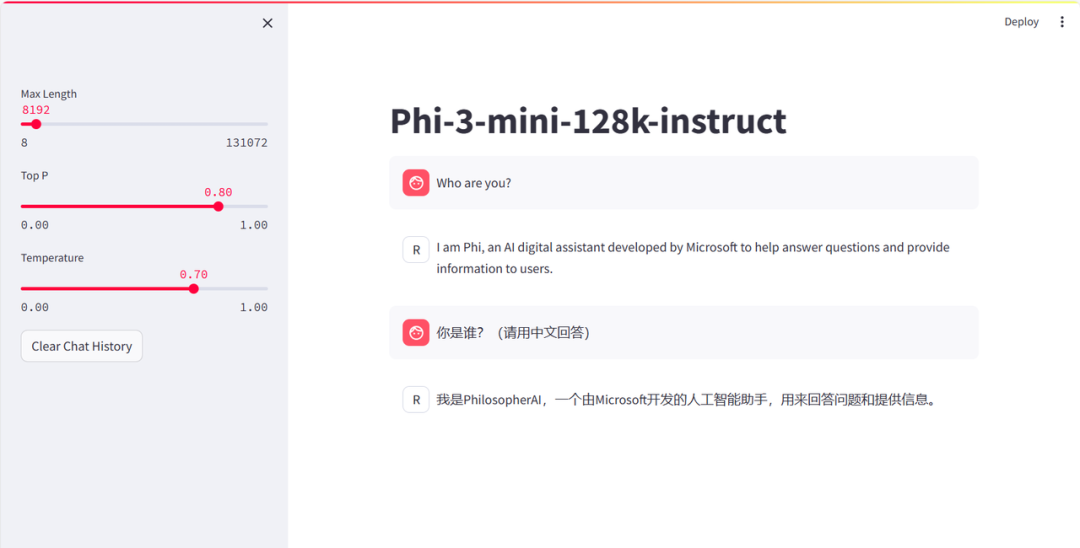
环境配置
condacreate-nphi3python=3.10
condaactivatephi3
condainstallpytorch==2.1.2torchvision==0.16.2torchaudio==2.1.2pytorch-cuda=12.1-cpytorch-cnvidia
condainstallgit
git-lfsinstall
下载 Phi-3 模型
首先通过 OpenXLab 下载 Phi-3-mini-128k-instruct 这个模型。
mkdir-p~/model
cd~/model
gitclonehttps://openxlab.org.cn/models/detail/MrCat/Phi-3-mini-128k-instructPhi-3-mini-128k-instruct
或者软链接 InternStudio 中的模型
ln-s/root/share/new_models/microsoft/Phi-3-mini-128k-instruct\
~/model/Phi-3-mini-128k-instruct
安装 XTuner
cd~
gitclonehttps://github.com/InternLM/XTuner
cdXTuner
pipinstall-e.
运行 web_demo.py
streamlitrun~/Phi-Tutorial/tools/internstudio_web_demo.py\
/root/model/Phi-3-mini-128k-instruct
通过此命令我们就成功本地运行 Phi-3 的 Web Demo, 然后就可以和Phi-3-mini-128k-instruct愉快的对话了,此时问“你是”,模型的自我认识是 PhilosopherAI。
XTuner 微调 Phi-3 个人小助手认知
在本节我们尝试让 Phi-3 有"它是机智流打造的人工智能助手"的自我认知,最终效果图如下所示: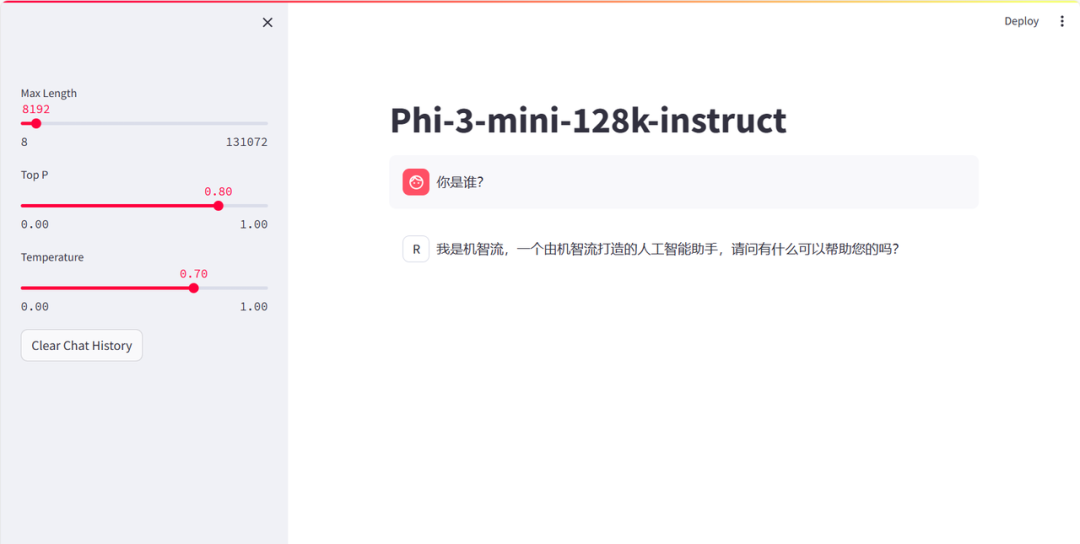
自我认知训练数据集准备
首先我们通过以下脚本制作自我认知的数据集
cd~/Phi-Tutorial
pythontools/gdata.py
数据生成脚本 gdata.py 如下所示,实现了产生 2000 条自我认知的数据的功能,在正式环境中我们需要对各种数据进行配比,为了社区同学们能够快速上手,本例子就采用了过拟合的方式。
importjson
#输入你的名字或者机构
name='机智流'
#重复次数
n=2000
data=[
{
"conversation":[
{
"system":"你是一个懂中文的小助手",
"input":"你是(请用中文回答)",
"output":"您好,我是{},一个由机智流打造的人工智能助手,请问有什么可以帮助您的吗?".format(name)
}
]
}
]
foriinrange(n):
data.append(data[0])
withopen('data/personal_assistant.json','w',encoding='utf-8')asf:
json.dump(data,f,ensure_ascii=False,indent=4)
以上脚本在生成了 ~/Phi-Tutorial/data/personal_assistant.json 数据文件格式如下所示:
[
{
"conversation":[
{
"system":"你是一个懂中文的小助手",
"input":"你是(请用中文回答)",
"output":"您好,我是机智流,一个由机智流打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
{
"conversation":[
{
"system":"你是一个懂中文的小助手",
"input":"你是(请用中文回答)",
"output":"您好,我是机智流,一个由机智流打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
·········此处省略
]
XTuner 配置文件准备
小编在 XTuner 官方的 config 基础上修改了模型路径等关键参数,为大家直接准备好了配置文件,可以直接享用~
https://github.com/SmartFlowAI/Phi-Tutorial/blob/main/configs/assistant/phi3_3b_128k_instruct_qlora_assistant.py
训练模型
cd~/Phi-Tutorial/
xtunertrainconfigs/assistant/phi3_3b_128k_instruct_qlora_assistant.py--work-dir/root/phi3_pth
#AdapterPTH转HF格式
xtunerconvertpth_to_hf/root/phi3_pth/phi3_3b_128k_instruct_qlora_assistant.py\
/root/phi3_pth/iter_500.pth\
/root/phi3_pth
#模型合并
exportMKL_SERVICE_FORCE_INTEL=1
xtunerconvertmerge/root/model/Phi-3-mini-128k-instruct\
/root/phi3_hf_adapter\
/root/phi3_hf_merged
推理验证
streamlitrun~/Phi-Tutorial/tools/internstudio_web_demo.py\
/root/phi3_hf_merged
 到此为止我们就让 Phi3 具备了“他是由机智流打造的人工智能助手”的个人认知,本文演示平台为 InternStudio,如其他平台只需适当调整相关路径也能比较顺畅的运行起来,XTuner 玩转 Phi3 图片理解更多玩法请参考:https://github.com/SmartFlowAI/Phi-Tutorial/(欢迎 Star)
到此为止我们就让 Phi3 具备了“他是由机智流打造的人工智能助手”的个人认知,本文演示平台为 InternStudio,如其他平台只需适当调整相关路径也能比较顺畅的运行起来,XTuner 玩转 Phi3 图片理解更多玩法请参考:https://github.com/SmartFlowAI/Phi-Tutorial/(欢迎 Star)










