3. 功能试玩
a. 音色更换
下面提供多个效果对比:
- Audio seed: 2; Text seed: 42; input text: 每个孩子是生下来就自带大模型的,他们天然有超强的数据处理能力。家庭教育是让孩子的大模型“本地化”。我们对孩子的教育,就是一种大模型的微调,最多起到 10%的作用。我们要做的是顺势而为,让孩子的先天大模型发挥最好的作用。
被 refine 后的文本变成了:
每个孩子是生下来就自带大模型的[uv_break],就他们天然有超强的数据处理能力[uv_break]。家庭教育是让孩子的大模型[uv_break]本地化[uv_break]。我们对孩子的教育,其实就是一种大模型的微调[uv_break],最多起到百分之十的作用[uv_break]。我们要做的是顺势而为[uv_break],让孩子的先天大模型发挥最好的作用。
音频预览:
- Audio seed: 2; Text seed: 884952 ; input text: 每个孩子是生下来就自带大模型的,他们天然有超强的数据处理能力。家庭教育是让孩子的大模型“本地化”。我们对孩子的教育,就是一种大模型的微调,最多起到 10%的作用。我们要做的是顺势而为,让孩子的先天大模型发挥最好的作用。
被 refine 后的文本变成了:
每个孩子是生下来就自带大模型的[uv_break],他们天然有超强的数据处理能力。家庭教育是让孩子的大模型本地化[uv_break]。我们对孩子的教育,就是一种大模型的微调,最多起到百分之十的作用[uv_break]。我们要做的是[uv_break]顺势而为[uv_break],让孩子的先天大模型发挥就是这个[uv_break]最好的作用。
音频预览:
可以看到上面的 text 都被修改过, 加过一些[uv_break]之类的标记之外, 仔细看会发现里面会加入一些口头禅之类的词, 让文本看起来更顺。实际上 TTS 里都会涉及这样的设计。
- 我们也可以让它不 refine 文本, 直接读,
Audio seed:2, 不 refine 文本。语气停顿效果会差一些, 同时真实性也会差一些。
音频预览:
- 更换一个音色:
Audio seed: 1;Text seed: 42; input text: 每个孩子是生下来就自带大模型的,他们天然有超强的数据处理能力。家庭教育是让孩子的大模型“本地化”。我们对孩子的教育,就是一种大模型的微调,最多起到 10%的作用。我们要做的是顺势而为,让孩子的先天大模型发挥最好的作用。
音频预览:
b. 语气停顿更换
这是 chatTTS 中最有价值的功能。目前开源项目提供了三个提示词, 玩法类似 Suno 里的提示词, 这些词不会被直接念出来, 但是会结合上下文来调整原有语音。从官方说法, 他们将逐渐支持更多这类嵌入的提示词 (见下图)。

- 笑:[laugh]
我遇到四川小吃真的特别开心。哎,[laugh],。比如甜水面[uv_break]、赖汤圆[uv_break]、蛋烘糕、叶粑等,这些小吃口味温和,超喜欢的。[uv_break],[laugh],
音频预览:
PS: 这里得配合一些真的开心的语句, 不然貌似生成时要么笑声诡异, 要么直接念单词... 还没找到规律怎么能用的特别好。
- 短停顿:
[uv_break] 效果比标点符号的停顿好, 对比长停顿:[lbreak]
我遇到四川小吃真的特别开心。哎,[laugh],。比如甜水面[lbreak]、赖汤圆[lbreak]、蛋烘糕、叶粑等,这些小吃口味温和,超喜欢的。[uv_break],[laugh],
音频预览:
PS: 这一段和上面一段的 audio seed 都是 2, text seed 没使用, 但是音色就是不同的。这里进一步证明了它不同的停顿效果, 音色会变。不可控。
c. 念数字:
来念一段带数字的, 不用 refine text 的情况下, 依旧能正确的念成“五十九万八千一百二十三”
我有一件帽衫,是我用598123块钱买的。可以和你换那个0.1个比特币吗?
音频预览:
但是如果比如用不同的后缀就不一定能读, 会直接读数字。
我有一件帽衫,是我用598123越南盾买的。可以和你换那个0.1个比特币吗?
音频预览:
d. 中英文混搭
很有意思, 带口音的英语。估计日本人的英语训练出来口音更重。
测试了 400 个音色, 发现里面还有东北口音的, 北京腔的, 不只是英语, 中文也带口音。
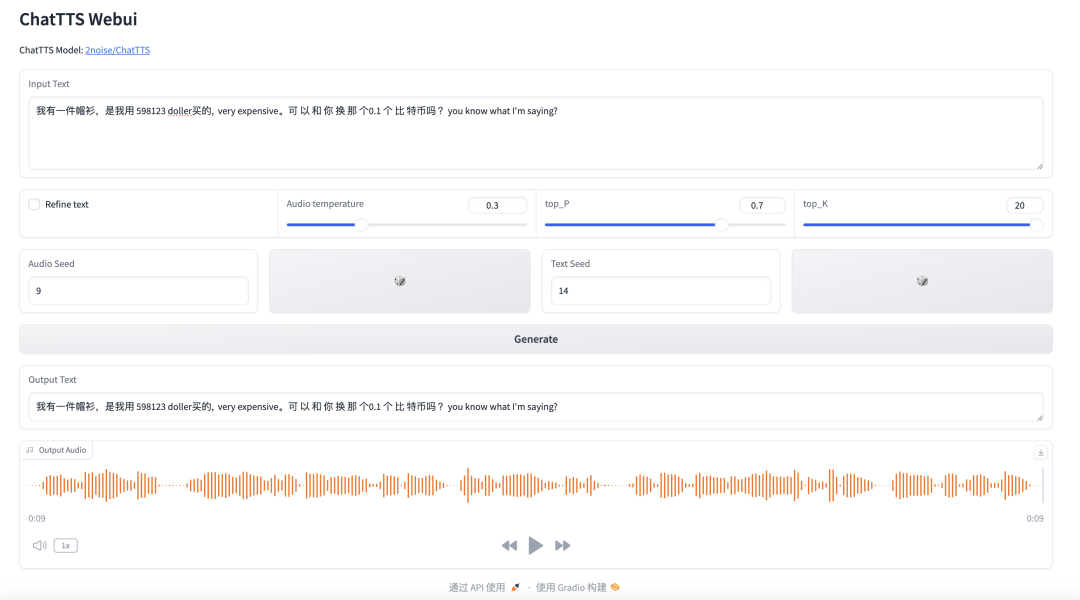
我有一件帽衫,是我用598123doller买的,veryexpensive。可以和你换那个0.1个比特币吗?youknowwhatI'msaying?
音频预览:
对比总结
相比 GPT-SoVITS 它的优势:
在不改变输入的文字, 不改变 Audio Seed 和 Text Seed 的情况下, chatTTS 生成的声音效果包括语气, 音色, 语气停顿都稳定。
[uv_break]之类的提示词的使用, 让 TTS 产生更接近人的情感, 语气和语速。
相比之下它的中英文混搭效果更自然, 念数字也会考虑“个十百千万”, 而不是单调的念数字。
02
安装部署
在 linux 上部署很简单, 比 GPT-SoVITS 更容易, 不需要自己下载模型放模型。当然本地部署的前提, 依旧是你有一张 GPU 显卡, 4G 以上显存。
简单步骤如下:
下载代码仓库
gitclonehttps://github.com/2noise/ChatTTS.git
2. 安装依赖 (⚠ 这里有两个依赖它没有放在 requirements.txt 里)
cdChatTTSpipinstall-rrequirements.txtpipinstallgradiopipinstallWeTextProcessing
3. 启动 webui 的 demo 程序, 然后用浏览器登录这个服务器的 ip:8080 就能试玩了
python./webui.sh--server_port8080
这个 demo 本身提供了 3 个参数:
--server_name: 服务器的 ip 地址, 默认 0.0.0.0
--servic_port: 即将开启的端口号
--local_path: 模型存储的本地路径
4. 第一次启动后生成语音时, 需要看下控制台输出, 它会下载一些模型文件, 因此比较慢, 而且可能因为网络的问题有各种失败。但是第一次加载成功了, 后面就顺利了。
5. 基于这个基础已经可以开始拓展了, 比如把它集成到 agent 的工具中去, 比如结合 chatgpt 来做更拟人化的实时沟通。
6. webui 上可以设置的几个参数说明:(参考下图)
- text:指的是需要转换成语音的文字内容。
- Refine text:选择是否自动对输入的文本进行优化处理。
- Audio Seed: 语音种子, 这是一个数字参数,用于选择声音的类型, 默认值为 2,是一个很知性的女孩子的声音。
- Text Seed: 文本种子, 这是一个正整数参数,用于 refine 文本的停顿。实测文本的停顿设置会影响音色, 音调。
- 额外提示词 (可以写在 input Text 里):用于添加笑声、停顿等效果。例如,可以设置为[oral_2][laugh_0][break_6]。
03
目前存在的问题
1. 语音生成基本功能
支持的语音时长不超过 30s, 超过 30 秒的需要特别修复。
某些 audio seed 在念某些语句时会丢失一些语句。
Refine 过程中有些字会被丢失, 比如“儿童节”在大概率会被 refine 成“童节”, 丢失一个“儿”字。
解决方法:跳过自动 refine, 以手动修改文本的方式来控制停顿。
即使同一个 audio seed, 如果使用不同的语句分段方式, 或者不同的 text seed, 生成的音色也不是很稳定, 会给人感觉不是同一个人的声音。
2. 代码 Bug:
uv_break 等提示词可能会在 refine 之后缺少[], 甚至有时候在有中括号的情况下也会被念出来, 听多了, 容易被洗脑, 不自觉的自己说话也念出 uv break 作为口头禅。(多听几遍, 很有那种 m3?的洗脑上头效果?)
音频预览:
3. 没提供微调 SFT 的接口
当然在底模已经提供的情况下, 我们自己调用模型来做微调是可以的, 但是项目本身没有提供相关的代码, 对于大多数人来说, 微调, 或者说声音克隆就成了一个门槛。
4. 本模型特别申明:不支持商用, 仅用于学术研究。
⚠ 在生成的语音内, 作者加了听不见的噪音水印, 可以很容易的被检测出来是他的模型生成的语音。
ChatTTS 还没放出训练代码无法自己克隆声音。
该作者还只放出了4w小时训练的版本,确保这个模型的声音能被ai检测出来。作者还留着一个10w小时训练数据的版本。










