|
把文档先“让LLM写摘要+打标签”,再用混合向量做检索,比直接扔原文进RAG,Top-10命中率从73%干到92%, latency 还更低。下面一起来具体分析:
痛点直击- 企业知识库动辄上千页,传统语义分块+Embedding常“漏答案”
方案全景 | | |
|---|
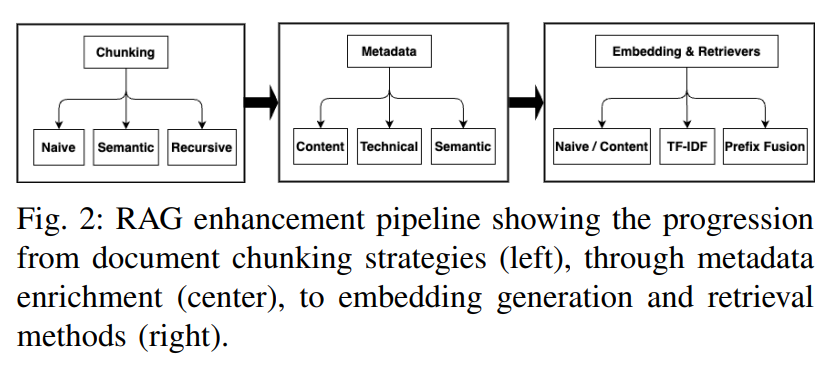
| | 三套并行:Naive / Recursive / Semantic | | | LLM自动生成三类元数据:
①内容类型②技术实体③用户意图&可能提问 | | | 三通道融合:
①纯内容②TF-IDF加权③Prefix-Fusion(标签前缀) | | | Cross-Encoder(BAAI/bge-reranker)生成0-1相关度真值 |
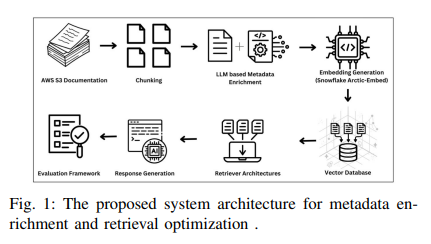
工作原理(3步10秒看懂)- Recursive Chunking
先按段落→句子→token三级拆分,512 token滑窗128重叠,结构不断层 - LLM元数据工厂
用GPT-4o(temp=0.5)批量输出JSON格式标签,单chunk<500 ms - TF-IDF加权向量
原文Embedding × 0.7 + 元数据TF-IDF向量 × 0.3,Snowflake Arctic-Embed-m一次编码,1536维
实验结果(AWS S3 6K页文档) | | | |
|---|
| | | | | Naive+TF-IDF加权 | 0.925 | | | | Recursive+TF-IDF加权 | | 0.825 | 0.807 |
给企业落地的一张 checklist✅先上Recursive+TF-IDF:精度最稳,82%起步
✅Hit率优先场景(如客服QA)改用Naive+Prefix-Fusion,直接冲92%
✅元数据Prompt模板固定输出JSON,方便后续换更小LLM降本
✅Cross-Encoder重排只在离线标注阶段用,线上仍走双Encoder,延迟可控
一句话带走“让LLM先给文档写‘小抄’,再进RAG,企业知识库立刻少幻觉、多命中。” | 









