|
大语言模型的微调主要分为两类:全参数微调和参数高效微调(lora等)。直接对 Instruct 模型进行调优通常仅带来微小的提升,甚至导致性能退化。Base 模型与Instruct 模型权重值高度相似。Base 模型往往是一个良好的学习器,但在后训练前较弱。因此,通过利用对应的Base 模型来调优 Instruct 模型。核心思想是先微调 Base 模型,然后将学成的权重更新 直接赋予 Instruct 模型。正就是Shadow-FT 理念,不引入额外参数,实现简单。  BASE与INSTRUCT模型的权重相似性分析相对差距比**来量化权重相似度,公式为: 其中为元素级求和,为绝对值运算。取值范围为0-1,代表两个模型权重完全一致,代表权重差异极大。 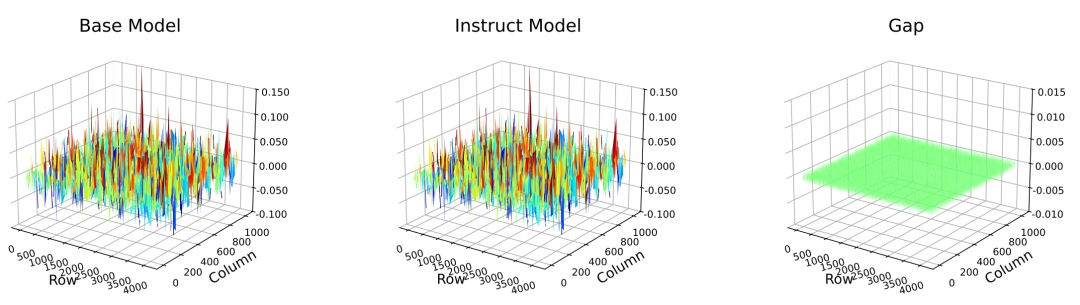 如上图,配对的BASE和INSTRUCT模型权重相似度极高,说明BASE和INSTRUCT模型的权重结构高度重合,因此得出结论,通过BASE模型辅助INSTRUCT模型微调可行。 方法Shadow-FT的核心逻辑是:利用BASE和INSTRUCT模型的权重相似性,先对BASE模型进行微调以获取优质的参数更新量,再将该更新量直接迁移到INSTRUCT模型上,从而避免直接微调INSTRUCT模型带来的性能退化问题。流程如下,比较简单: - 微调BASE模型:首先采用任意微调方法(全参数或LoRA)对BASE模型进行训练,得到更新后的BASE模型权重,公式为:
其中代表微调操作,为BASE模型原始权重。 - 迁移参数更新量到INSTRUCT模型:计算BASE模型的参数更新量,并将其直接叠加到INSTRUCT模型的原始权重上,得到最终的INSTRUCT模型权重,公式为:
传统INSTRUCT模型微调的公式为: 对比可知,Shadow-FT与传统微调的训练成本完全一致,唯一区别在于:传统方法从INSTRUCT模型自身学习参数更新量,而Shadow-FT从BASE模型学习更新量再迁移。 实验性能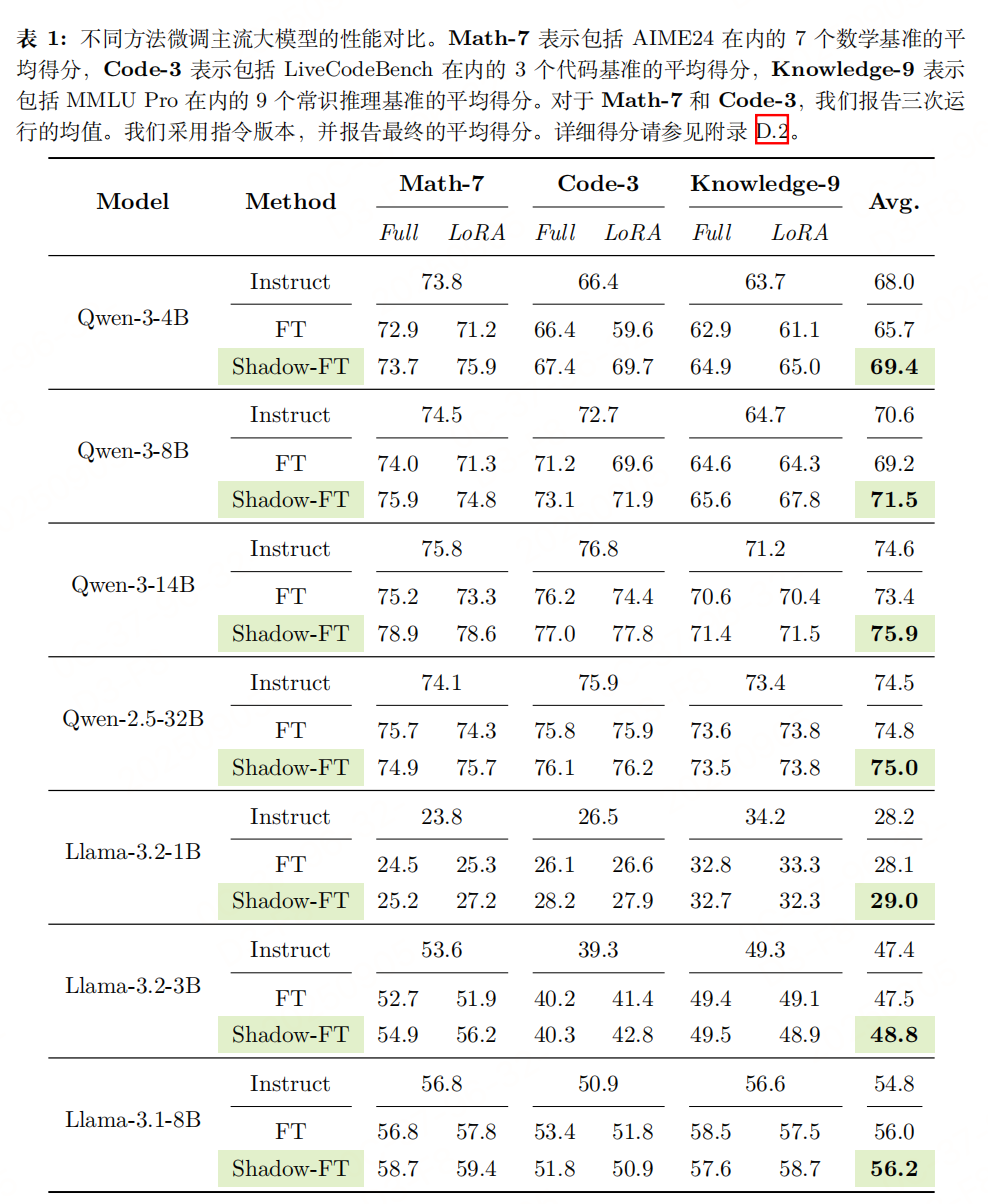 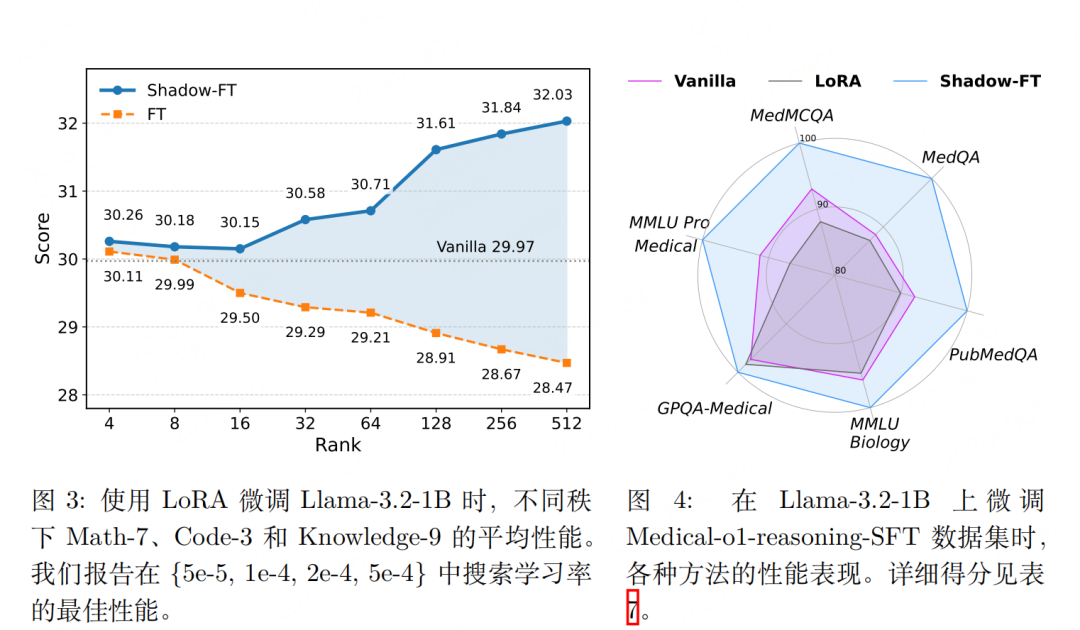 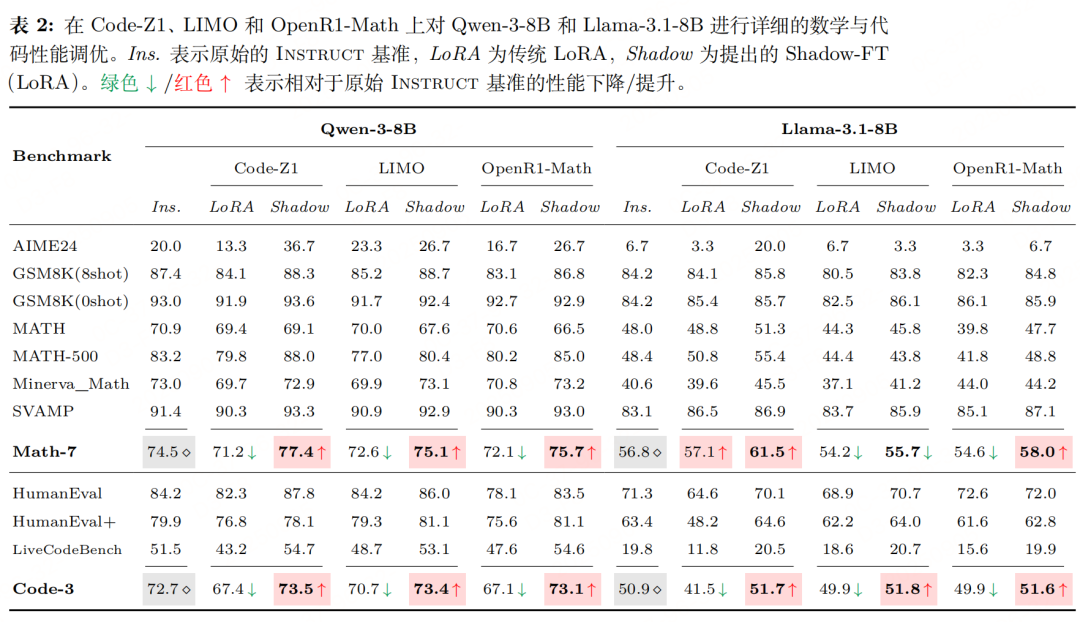 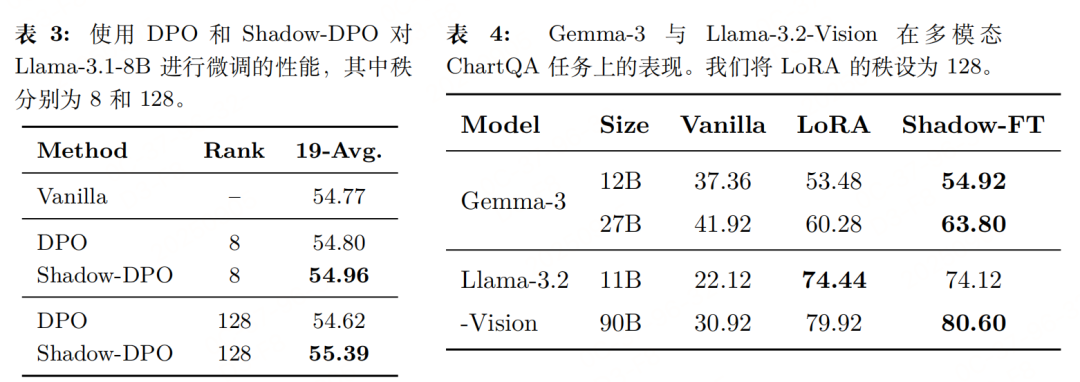 | 









