|
写这篇文章的契机,是 Qoder 前几天上线了我个人很喜欢的一个新功能——「提示词增强」。之前就因为这功能特别喜欢 Augment(最早只有Augment 有)。 先给大家看看Qoder「提示词增强」的效果。 下面这段提示词,是我根据“技能五子棋”网页测试结果给 Qoder 的反馈(口语化,没什么结构,甚至还偷懒省略了部分描述,整个就很粗糙): 技能逻辑和技能之间的关系你没做好,比如一个回合只能使用一个技能,另外,技能之间有约束关系,比如对方使用【静如止水】功能,那么只能冻结对手下棋和部分技能,但无法冻结【水滴石穿】技能,因为这个技能是可以对抗【静如止水】的,其它也存在类似的逻辑,你检查下。另外玩家轮流将棋子放在棋盘的交叉点上 当我点击 Qoder 的「提示词增强」按钮后,它就给我返回下面这段提示词。 不仅结构化,适合 AI 阅读,而且是结合上下文进行优化的。比如其中关于【两极反转】、【力拔山兮】和【东山再起】技能的制约关系,就是Qoder 根据代码库、聊天历史和当前会话进行补充的。 请仔细检查并修复技能系统中的逻辑问题,确保以下几点得到正确实现:1.技能使用限制: -每个技能在单局游戏中只能使用一次 -每个回合只能发动一个技能(无论是玩家还是AI)
2.技能间的关系和约束需要正确实现: -当一方使用【静如止水】时,只能冻结对手的下棋行为和部分技能,但不能冻结【水滴石穿】技能,因为【水滴石穿】可以对抗【静如止水】 -【两极反转】可以克制【力拔山兮】,当【力拔山兮】被使用时,如果对方有【两极反转】则应触发反制逻辑 -【东山再起】只能在【力拔山兮】使用导致败局时才能使用 -类似的技能间制约关系需要仔细检查并正确实现
3.游戏基本规则确认: -玩家和电脑应该轮流在棋盘的交叉点上放置棋子 -轮到某方时,该方可以正常下棋或选择使用技能(但一回合只能做一件事)
请全面检查技能逻辑实现,修复所有技能间关系和使用约束的问题。
这种上下文补充对我就特别有用。因为我并不太会写提示词,还经常会偷懒。
不同于可以复用的元提示词(这种我还有耐心“雕花”),Vibe Coding 每次对话要给到的提示词都不一样,我一般只在最开始下需求的时候会规规矩矩地写,但随着迭代的对话次数越多,就会越偷懒,然后就会给出前面那种很粗糙的提示词。但,「提示词增强」功能也不是万能的,一个是它本身就有字数限制(比如 Qoder 的「提示词增强」目前的上限是250字);另外也不是所有场景都适合使用「提示词增强」功能的。如果任务本身非常简单、具体(如“将变量名从x改为y”),提示词增强可能显得多余,因为手动输入已经足够清晰。还有那种高度个性化的需求,自动增强可能干扰思路甚至直接跑偏。比如我想给“技能五子棋”这个网页游戏增加个游戏介绍页面,并且规定了大标题和描述: 生成一个游戏介绍页面,大标题是“技能五子棋”,描述是“传统的五子棋,就是把五个子连成一条线,好无趣,好无聊。而技能五子棋,就是在传统的五子棋,加入技能,好好玩……” 但经过「提示词增强」后,反而和我最初想要的不一样。 创建一个游戏介绍页面,要求如下:-大标题为"技能五子棋"-副标题或描述文案需体现与传统五子棋的区别,突出技能系统的创新性-文案内容应包含:传统五子棋仅靠连珠获胜过于单调,而技能五子棋在此基础上加入了8种独特技能,大大增加了游戏的策略性和趣味性-页面应包含游戏核心特色介绍,如技能种类、玩法亮点等-设计风格应与现有像素风UI保持一致-提供开始游戏按钮或其他CTA入口 那什么时候适合使用「提示词增强」呢? 这里提供两种场景(当然不止这两种)。 一种是那种需要快速将模糊想法转化为精确 AI 指令的场景,比起从 0 到 1 去写,基于具体的提示词去改效率反而更高,因为比起要什么,我们更清楚自己不要什么。 另一种是需要深入仓库上下文或涉及多模块协作,比如当我们想要基于某个开源项目新增功能,如果不熟悉项目可能很难手动构建高质量的提示词,这时候使用「提示词增强」反而能提高效率,因为它能自动提取上下文(如代码结构、依赖关系),生成强相关的结构化指令。
现在开发者社区基本形成一个共识,就是SDD(Spec Driven Developement,规范驱动开发)是一种有效的上下文工程实践。它是先定义“做什么”(规范),再考虑“怎么做”(实现),将规范文档作为开发的核心驱动力,而非代码本身。 它主要解决两类问题:一类是在传统开发中,文档与代码脱节;另一类是在 Vibe Coding(凭感觉编程)中,缺乏前期规划,导致项目后期结构混乱、难以维护。 AWS Kiro 应该是最早把 Spec 这种理念带到 Vibe Coding 中的,它将 Spec 理念工程化为可操作的三阶段工作流(需求、设计、任务)。 再后来,不同团队根据自己对 Spec 的理解,推出了BMAD-METHOD、Spec-kit、OpenSpec、Qoder Quest Mode等项目和工具。 这些项目和工具的核心理念都是 Spec,区别只在于将项目分为几个阶段,以及分为哪些阶段。 比如Qoder 的Quest Mode 是分为三个阶段,分别是技术设计、任务执行和任务总结。 在技术设计阶段,AI 会审阅你项目的 memory 和 context,分析代码库的结构,生成一份完整的 Spec 文档。这份文档不是写死的,你可以在审阅后自行编辑,确保你和 AI 对任务的理解达成一致。 达成一致后,就可以点击右上角的「开始任务」,AI 就会进入第二阶段——任务执行。 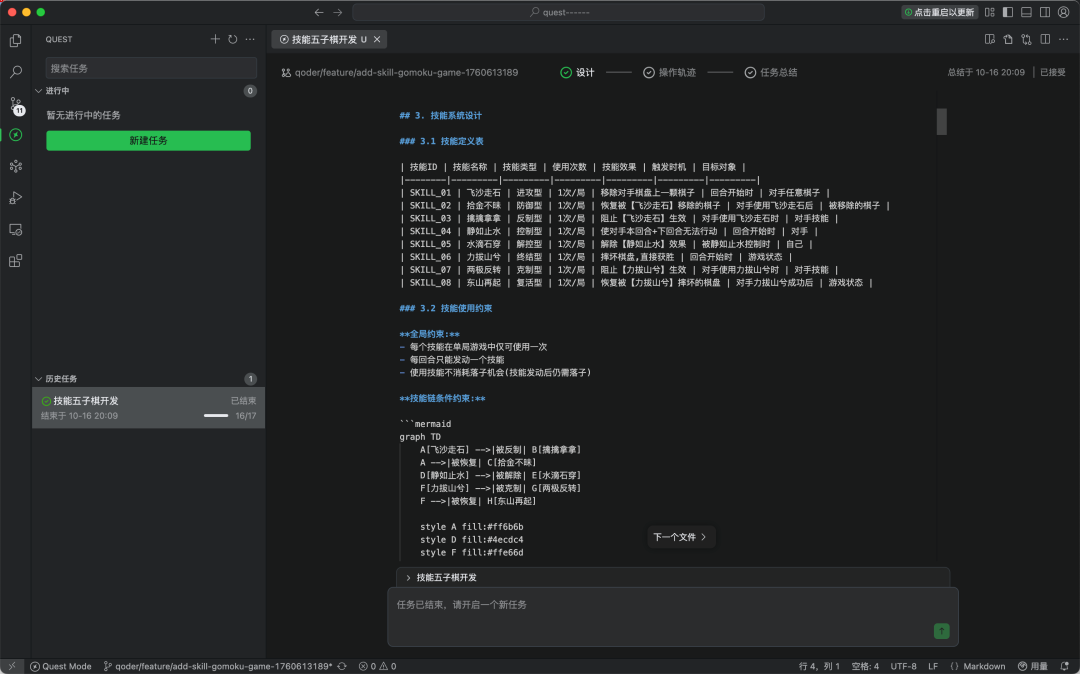
任务执行阶段,就是大家在各种 IDE 中经常看到的执行界面,它会展示 AI 的待办计划、实时输出,进度状态以及任何阻塞项。只不过在 Quest Mode 中叫做「轨迹追踪」。 在这个过程中,你可以随时添加新需求——即使任务正在运行——只需要在聊天框中发送消息,AI 会相应调整计划并继续工作。 其实在进入第一阶段之前,Quest Mode 会让你选择本地模式还是远程模式,前者比较好理解,后者则类似 Cursor 的Background Agent。 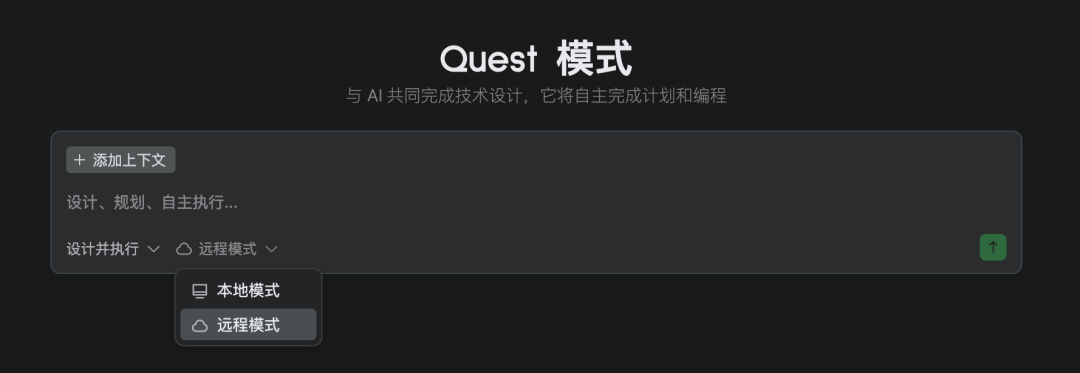
如果你选择远程模式,Qoder 在第二阶段就在云上启动一个沙箱(如下图所示),一个安全的运行环境,Agent 可以在这个隔离环境中自主运行,不影响本地环境。 当本地环境释放出来了,AI 可以工作的时空间就不再受开发者的时间空限制,即使开发者在睡觉,在旅游,在出差,AI 照样可以在理论上算力无限的云上执行任务。 当任务完成后,系统就会进入第三阶段——任务总结。 AI 会自动生成任务报告,包括已完成的代码修改的总结、测试结果与验证结论,以及已更改文件的详细列表。你可以通过查看这些文件以快速评估 AI 生成的代码的质量和完整性。 如果需要继续处理,可以返回第二阶段「轨迹追踪」发送新消息,AI 将从上次停留处继续。 Quest Mode 就有点像“外包项目”,我们把一个功能模块的开发任务写成需求文档,然后交给 Qoder 这位承包商去完成。我们只需在开始前澄清需求,最后验收成果即可,中间可以解放时间去处理其他事情。 那什么项目适合“外包”给 Quest Mode 呢? 两个判断标准。 第一,这个任务目标是否明确?如果目标不明确,那很难生成清晰准确的需求规格说明(Spec),那么 Quest 效果就会大打折扣。 第二,这个任务实施起来是否非常耗时耗力?如果是,那就应该考虑Quest Mode。因为Quest Mode 设计之初就是用来处理这种复杂、长周期开发任务的。 以下这三个栗子,都满足这两个判断标准: 开发一个完整的新功能:例如“开发一个带权限管理的用户中心模块” 大型代码迁移/重构:如“将整个项目从 JavaScript 迁移到 TypeScript” 批量任务:如“为项目中的所有核心函数添加单元测试”
至于其它任务,比如在阅读开源项目或接手遗留代码时,对某个文件或函数的作用感到困惑,直接使用 Ask Mode 提问是最快的,就像身边有一位随时待命的专家。 如果是那种目标明确但任务相对小型的,比如修复一个具体的 Bug,添加一个小功能,或者对某个模块进行优化或重写,Agent Mode 会是更好的选择。而且你能全程参与,保持控制感。
上下文压缩 我们在选择 AI 编程工具时,大概率考虑两个点,性能和成本。 性能就是谁更好用,能更好地解决真实的软件开发问题。成本就是 token 的消耗,大部分人都是希望花小钱也能把事办好,所以目前很多 AI 编程工具都推出了「上下文压缩」功能,并且大都默认开启「Auto Compact(自动压缩)」。 这本身是件好事,可以帮助用户自动优化上下文,减少手动干预的风险。只不过有些工具的「Auto Compact」完全是黑箱,有些则是「Auto Compact」 buffer(缓冲区)在整个 context usage 的占比特别高,我之前在知识星球也分享过这个点。 Qoder 的「上下文压缩」功能应该就是瞄准这两个点去解决的:
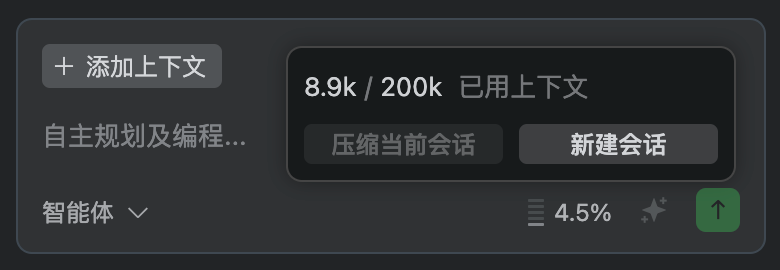
你可以根据上下文使用情况自主判断是否「压缩当前会话」还是「新建会话」,如果如果你没来得及手动压缩就超过上下文窗口,也不用担心,因为在超过上下文窗口时,Qoder 就会帮我们自动压缩。
Repo Wiki Repo Wiki 是 Qoder 的独创功能,它会为你的项目自动生成结构化文档,并且当系统检测到代码更新导致文档滞后时,会提醒你更新,从而保障文档与代码同步。 看这描述大家可能会觉得Repo Wiki平平无奇,但其实它特别懂开发同学的痛点。 在实际工作中,开发同学经常会遇到一个问题,就是代码蹭蹭蹭写完了,但他不想写相关的文档,或者他不擅长写这类文档,又或者他陷入“知识的诅咒”就是没法在文档中有效传递信息……不管哪种,久而久之,文档就会出现缺失、过时或质量低下。 注:“知识的诅咒”是一种认知偏差现象,指当一个人掌握了某种知识后,难以想象缺乏该知识时的状态,导致在沟通或教学中无法有效传递信息。之前在线下和B站UP主@程序员晚枫 吃饭的时候也聊过这个话题,他表示自己确实没法站在小白的角度去介绍一些开发概念,因为这些概念在他看来,应该是不用介绍的呀。 这种文档,既不利于团队的知识传承,也不方便用户快速上手项目(我之前就遇到一些文档写得一般的开源项目,就是你跟着它的 README 文档去操作是跑不通的,结果才发现它文档相对代码是滞后的)。 Repo Wiki 通过将知识文档化,很好地解决了这个痛点。下面展示的这两张图,就是借助Repo Wiki,将开发的项目一键生成结构化的 Wiki 文档,有快速上手说明,有,技术栈和依赖说明,还有 mermaid 图表进行架构展示。 先回答第一个问题。有重叠,但不多,更多是互补。 从范围与颗粒度去看,Quest Mode 是任务导向(细粒度、临时),聚焦单一开发周期(如一个 feature 的 Spec)。输出更像“项目日志”,强调执行可验证性。 而 Repo Wiki 是仓库导向(粗粒度、持久),覆盖整个代码库的全局视图(如依赖图、模块交互)。输出更像“系统手册”,强调架构洞察。 之所以说它俩互补,是因为 Repo Wiki 可以作为 Quest Mode 的“知识库”输入,提供跨文件上下文;Quest Mode 的输出又会触发 Repo Wiki 的更新,形成闭环。 再回答第二个问题。 从产出结果看,Repo Wiki 和 DeepWiki 确实很像,都可以将复杂的代码库转化为人类和机器都能轻松理解的结构化知识,解决“代码难读懂”的痛点。 但从服务场景看,Repo Wiki 是和开发场景强结合的,生成的 Wiki 与代码仓库共存,支持共享、编辑,还可以跟踪代码变更并自动提醒更新,还可以为平台内的 Quest Mode 等开发功能提供上下文。它更强调的是强调知识的沉淀、共享和持续同步,Wiki本身是团队可协作的工程资产。 而DeepWiki(这里不包括 deepwiki-MCP)和开发场景弱结合,主要功能是理解和问答,更像一个强大的“项目顾问”,但不直接参与编码和提交。 虽然这篇文章是在介绍 Qoder 的上下文工程实践,但很多实践并非 Qoder 独有。 过去半年,我观察到一个有趣的现象:各家 AI 编程工具的基础功能正在快速趋同,产品的价格和权益也变得大差不差。 这种同质化背后,说明行业开始进入新的阶段。接下来,AI 编程工具的竞争在模型和成本外,还要加上一条:谁更懂开发者真实的软件构建困境。 未来的胜出者,未必是技术最强的,但一定是最懂开发者如何在真实项目中挣扎、思考和决策的。 这场竞争才刚刚开始,而你我都是见证者。
| 









