|
目前公司的智能问答平台利用RAG技术构建,现给大家分享下通RAG技术构建智能问平台的具体流程和原理。 一、什么是RAG RAG是检索增强生成技术(Retrieval-Augmented Generation),目前是构建智能问答的重要技术。RAG相比传统的检索可以可以减少幻觉;支持知识动态更新等优点,是现在企业和个人打造知识库的重要架构和技术。核心包括以下2点: 1、数据准备阶段 包括:数据收集及清洗——>文本解析及分割——>文本转化成向量——>数据入库
2、应用阶段 包括:用户提问——>问题解析——>数据检索(召回和重排)——>注入Prompt——>LLM生成答案
二、RAG构建智能问答系统详解 以下是RAG技术构建智能问答平台业务流程图:
一)数据准备阶段
1、数据收集及清洗 企业需要建立自己的知识库,根据企业业务进行分类,建议设置版主进行运营,毕竟没有更新的知识是没用的。同时也可以去收集各个业务系统的数据,包括钉钉的发文、项目管理系统等知识。下图是根据业务构建知识库架构和流程: 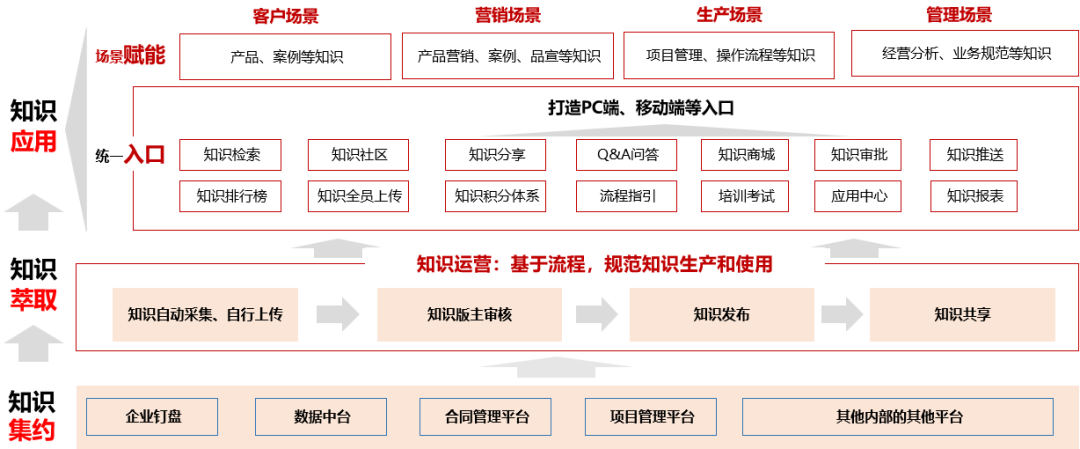
知识包括非结构化(各类文档,如:Word、PDF、Excel等)和结构化的知识(Excel、数据库知识等)。 收集了知识后,对部分数据进行清洗,去除冗余和噪音。包括去除重复文档、去除过时的旧文档等。特别同一份知识,经常存在新旧版本,要记得把旧版本删除。 2、文本解析及分割 1)文件解析 文件解析是将原始文件(如 PDF、Word、Markdown、表格 等)转换为转换为纯文本或结构化文本。文件解析技术包括:基于空间布局的技术(MinerU)、多模态技术。 2)文件分割 大模型的输入长度有限,且长文本不利于精准检索,因此需要将原始文本分割为较小的 “块”(Chunks)。
分割策略包括按固定大小分割和按语义分割。最初我们是按固定大小分割,发现效果不太好,后续按语义单元进行分割,效果好很多。在分割时由于会丢失上一级标题,影响检索效果,建议把上一级标题自动加上。 3、把文本转化成向量 RAG 的 “检索” 环节依赖向量数据库,需将文本块转换为向量(Embedding)并存储,以便快速匹配相似内容。 选择开源模型,把文本转成向量,目前有conan-embedding-v1、bge-m3 等模型。经过对比和测试发现bge-m3模型比较好。 4、数据入库 转成向量后,存储到向量数据库。根据不同内容建了DOC库和QA库。所有文档放到DOC库,如果有问答对,放到QA库。QA库是简短的一问一答知识列表,优先级会比DOC库优先。
二)应用阶段 1、用户提问 在所有需要问答的页面,我们都可以设计智能问答入口,引导用户提问。目前交互基本都是千篇一律。如下是豆包交互。
2、问题解析 由于存在上下文,需要对用户多轮会话进行改写,得出用户真正要问的问题。如果智能问答平台不只是问答,要能实现问生产系统的内容,那还要去对问题进行意图识别,语法分析、实体识别等步骤。 3、数据检索 包括知识检索、知识召回、知识重排与生成、注入Prompt 1)知识检索 将用户问题通过 Embedding 模型转为向量,在向量数据库中搜索与该向量相似度最高的 Top N 个 Chunk(如 Top 5)。为了解决向量模型对专业术语不敏感的问题,还会引入关键词检索。即向量检索+关键词检索 2)知识召回 从检索到的文档中,提取出相关的句子或段落,作为候选答案。 3)知识重排与生成 使用算法,把所有检索的结果进行排序。这里涉及到答案评分,使用模型对答案进行评分,评分高的排前面,获得重排的答案。
4)注入Prompt 我们提前准备了一段通用的Prompt,基于提供的知识回答问题,不编造信息,让他按我们的要求输出答案,例如我们构建如下Prompt: 5)LLM生成答案 通过模型,和注入Prompt,让模型对候知识进行总结。国内可以选择DeepSeek V3、Deepseek R1、Qwen等模型进行总结。建议试用DeepSeek V3。 以上就用RAG 技术构建智能问答平台的基本流程,为了提升用户体验,我们也可以引入定量指标和定性反馈评估系统性能(包括检索精度、生成准确性、用户满意度、响应速度等指标),并持续优化。 | 









