ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">概述ingFang SC", "Microsoft YaHei", sans-serif;font-size: 18px;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">随着生成式 AI 的迅速发展,大语言模型(LLM)的推理性能和成本已成为其大规模应用的关键障碍。LLM 推理是指利用仅解码器的 Transformer 模型生成词元(token),其中大多数挑战及其解决方案都源于这一特定架构和用例。ingFang SC", "Microsoft YaHei", sans-serif;font-size: 18px;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">本文将深入探讨 LLM 推理过程的两个阶段:预填充阶段(Prefilling)和解码阶段(Decoding),并详细介绍如何通过算法创新和系统优化来提升 LLM 的推理效率。具体内容包括:
ingFang SC", "Microsoft YaHei", sans-serif;font-size: 18px;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">LLM 推理基础知识:介绍 Transformer 架构及其关键组件,如自注意力机制、多头注意力机制和前馈网络。同时,详细说明从输入词元到生成输出词元的预填充阶段和解码阶段的推理过程。 LLM 推理优化方向:探讨通过算法创新和系统优化来提升 LLM 推理效率的方法,包括优化解码算法、优化架构设计和模型压缩等。 LLM 推理性能指标:介绍衡量 LLM 推理性能的关键指标,如每秒请求数(RPS)、首字输出时间(TTFT)和字符间延迟(ITL)等。 ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">术语解释ingFang SC", "Microsoft YaHei", sans-serif;font-size: 18px;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-2">词元(Token):在自然语言处理中,词元是文本数据的最小单位。它可以是一个词、一部分词、一个字符,或者是一个子词。词元化是将文本拆分成这些最小单位的过程,以便于计算机处理和分析。 预填充阶段(Prefilling):在 LLM 推理过程中,预填充阶段是指模型在收到输入序列后,生成第一个输出词元之前的计算过程。 解码阶段(Decoding):解码阶段是指在预填充阶段生成第一个词元后,模型通过迭代生成后续词元的过程,直到生成结束标志或达到最大序列长度。 自注意力机制(Self-Attention Mechanism):Transformer 模型中的一种机制,通过计算输入序列中不同部分的重要性,使模型能够在生成过程中聚焦于输入序列的不同部分。 前馈网络(Feed-Forward Network, FFN):Transformer 模型中的组件,包含两个线性变换和一个非线性激活函数,能够增加模型的非线性表达能力。 多头注意力机制(Multi-Head Attention):Transformer 模型中的一种机制,通过在不同的表示空间中同时关注输入序列的不同部分,提高模型的表现力。 位置编码(Position Encoding):在 Transformer 模型中,位置编码为序列中的每个词元添加位置信息,使模型能够识别输入序列中的相对位置关系。 量化(Quantization):通过减少表示模型权重和激活值的比特位数来降低计算成本和内存占用的一种技术。 模型并行(Model Parallelism):一种将模型的不同部分分配到多个设备上并行计算的方法,用于加速推理过程。 数据并行(Data Parallelism):一种将不同的数据样本分配到多个设备上并行处理的方法,用于提高处理速度。 网络剪枝(Network Pruning):通过移除模型中不重要的参数来减少模型大小和计算需求的一种技术。 ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">LLM 推理基础知识ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;margin-top: 20px;margin-bottom: 15px;font-size: 1.375em;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">Transformer 介绍ingFang SC", "Microsoft YaHei", sans-serif;font-size: 18px;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">当前主流的 LLM 比如 OpenAI 的 GPT 系列、Meta 的 Llama 系列还有如 OPT、BLOOM、Mistral 等等,其核心是基于自注意力机制的 Transformer 架构,该机制允许模型在做出预测时对输入数据的不同部分的重要性进行权重计算。 ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;margin-top: 20px;margin-bottom: 15px;font-size: 1.25em;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">自注意力机制 ingFang SC", "Microsoft YaHei", sans-serif;font-weight: bold;line-height: 1.5;margin-top: 20px;margin-bottom: 15px;font-size: 1.25em;padding-top: 10px;color: rgb(85, 85, 85);letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">自注意力机制在 Transformer 模型中,自注意力机制通过线性变换计算输入序列 X 的查询 Q、键 K 和值 V。自注意力分数计算公式如下: 其中 dk 是键的维度。该机制使模型能够对输出的每个元素聚焦于输入序列的不同部分,从而捕捉输入序列中不同位置之间的复杂依赖关系。 其中 dk 是键的维度。该机制使模型能够对输出的每个元素聚焦于输入序列的不同部分,从而捕捉输入序列中不同位置之间的复杂依赖关系。 前馈网络(FFN)Transformer 的每一层中都包含前馈网络(FFN),显著增加了计算强度。FFN 通常由两个线性变换和一个非线性激活函数(通常是 ReLU)组成,公式如下: 其中 W1, W2, b1, b2 是可学习参数。FFN 引入了必要的非线性,使模型能够学习更复杂的模式。每个 Transformer 层在多头注意力(MHA)聚合输入的不同部分的信息后,FFN 会独立地处理这些聚合信息。 其中 W1, W2, b1, b2 是可学习参数。FFN 引入了必要的非线性,使模型能够学习更复杂的模式。每个 Transformer 层在多头注意力(MHA)聚合输入的不同部分的信息后,FFN 会独立地处理这些聚合信息。 Transformer 其他组件Transformer 模型还包括其他关键组件,如位置编码(position encoding),它为序列中的每个标记添加位置信息;多头注意力机制(multi-head attention),允许模型在不同的表示空间中关注序列的不同部分。这些组件共同作用,使得 Transformer 模型能够捕捉广泛的语言上下文和细微差别,在各种 NLP 任务中设立了新的基准。 LLM 推理过程:预填充 + 解码在介绍完 Transformer 结构之后,我们来看下 Decoder-Only 的模型如何进行模型推理。为简单起见,我们假设一次只处理一个序列(即批处理大小为 1)。在下图中,我描述了一个简单的基于 Transformer 的解码器的主要层,用于从一系列输入词元中生成输出词元。 需要注意的是,解码器本身并不会输出词元,而是输出 logit(其数量与词汇表大小相同)。输出 logit 的最后一层通常被称为语言模型头(Language Model Head)或 LM 头。将 logit 转换为词元是通过一种启发式算法来完成的,这种算法通常被称为解码策略(decoding strategy),也叫做词元搜索策略(token search strategy)或生成策略(generation strategy)。解码策略的目的是在保持文本连贯性和合理性的同时,提高生成结果的质量和多样性。 需要注意的是,解码器本身并不会输出词元,而是输出 logit(其数量与词汇表大小相同)。输出 logit 的最后一层通常被称为语言模型头(Language Model Head)或 LM 头。将 logit 转换为词元是通过一种启发式算法来完成的,这种算法通常被称为解码策略(decoding strategy),也叫做词元搜索策略(token search strategy)或生成策略(generation strategy)。解码策略的目的是在保持文本连贯性和合理性的同时,提高生成结果的质量和多样性。 简单起见,我们假设解码策略是模型的一部分,这些接受词元序列作为输入,并返回相应输出词元的实体通常被称为执行引擎或推理引擎。 如果要生成多个词元呢?使用基于 Transformer 的解码器,从一个输入文本序列(称为 prompt)中生成文本(称为 completion)通常包含以下步骤: 将模型权重加载到 GPU。 在 CPU 上对输入文本进行分词,并将文本序列词元传输到 GPU。 利用模型运行输入词元,输出第一个词元(预填充阶段)。 将生成的词元添加到输入的词元序列中,然后作为新的输入,生成下一个词元,直到生成停止词元(比如 EOS)或者到达预先配置的最大序列长度(解码阶段)。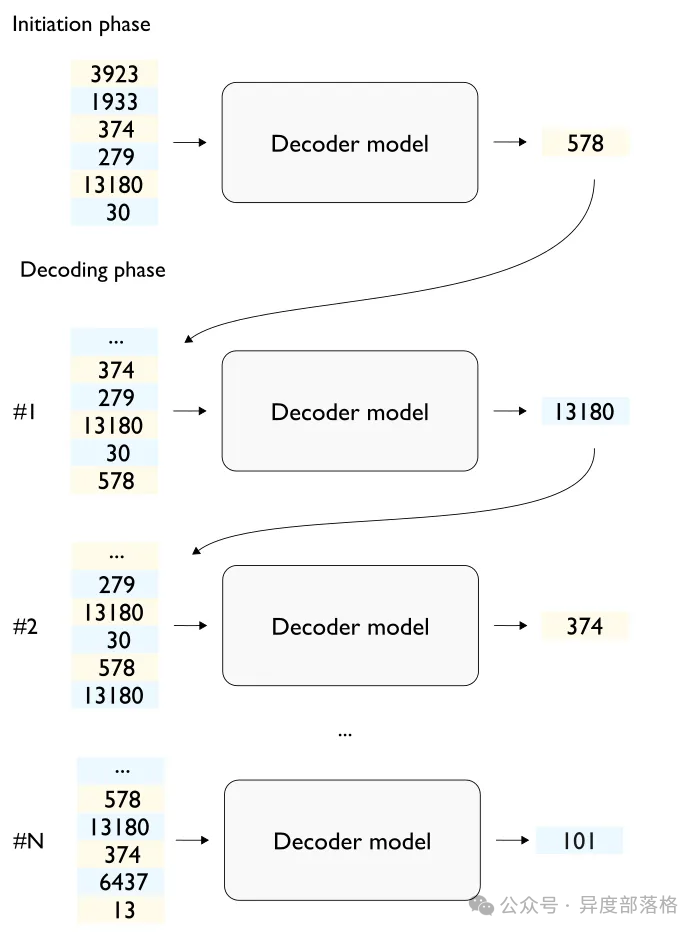 将生成的词元传输到 CPU,并进行逆词元化(de-tokenization)获得生成的文本。 上述介绍了最基础的 LLM 推理过程,目前也有一些更为先进的技术,流程上可能会有所不同。 上述介绍了最基础的 LLM 推理过程,目前也有一些更为先进的技术,流程上可能会有所不同。
LLM 推理优化方向在《Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems》论文中,将现有的 LLM 推理优化的方向分成两类: 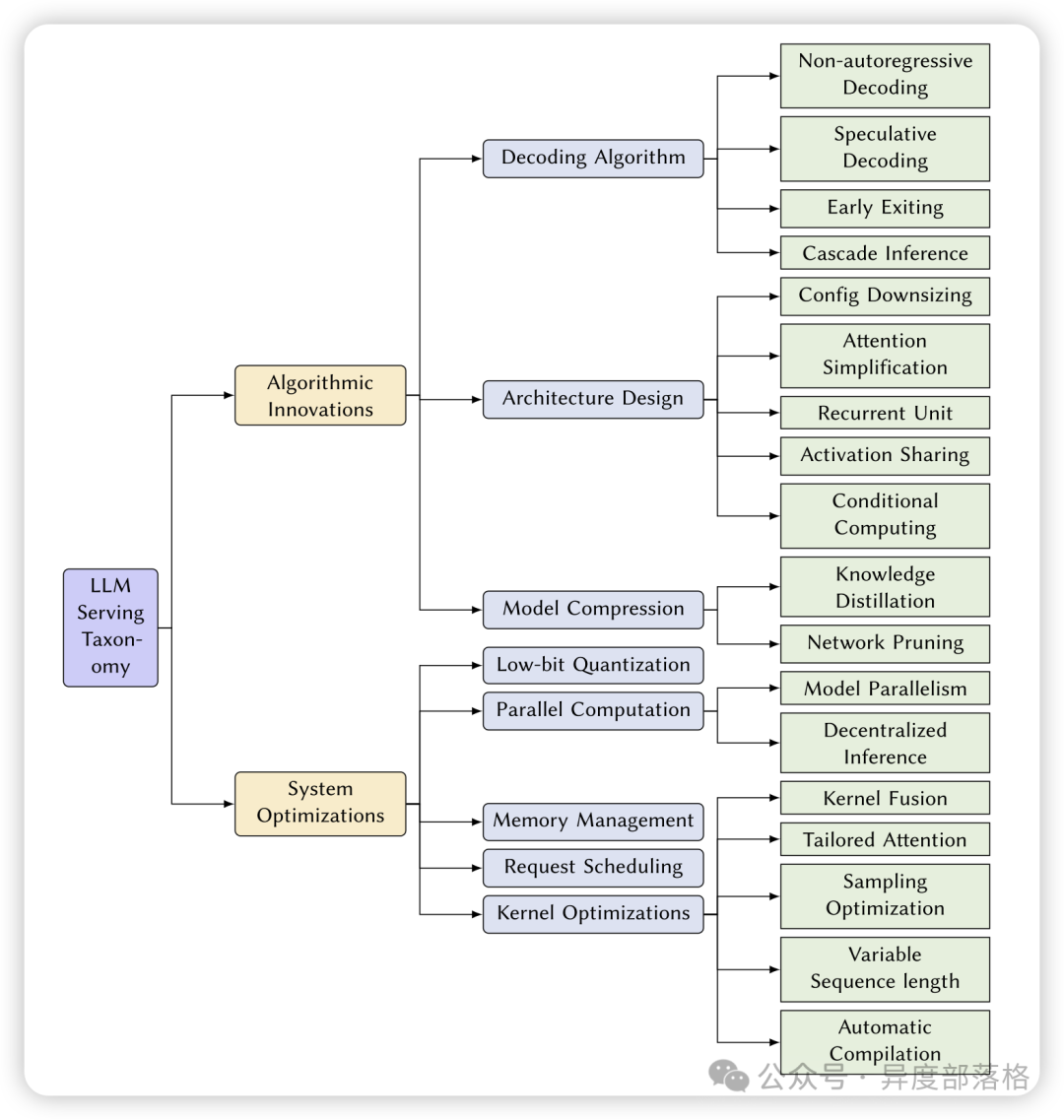
算法创新这些创新旨在优化大型语言模型(LLM)的推理过程,以提高效率、减少计算复杂度,并在不显著降低性能的情况下减小模型的计算资源需求。 优化解码算法(Decoding Algorithm)1. 非自回归解码(Non-autoregressive Decoding)慢。非自回归解码试图并行生成多个输出标记,从而提高解码速度。 2. 推测性解码(Speculative Decoding)3. 提前退出(Early Exiting)4. 级联推理(Cascade Inference)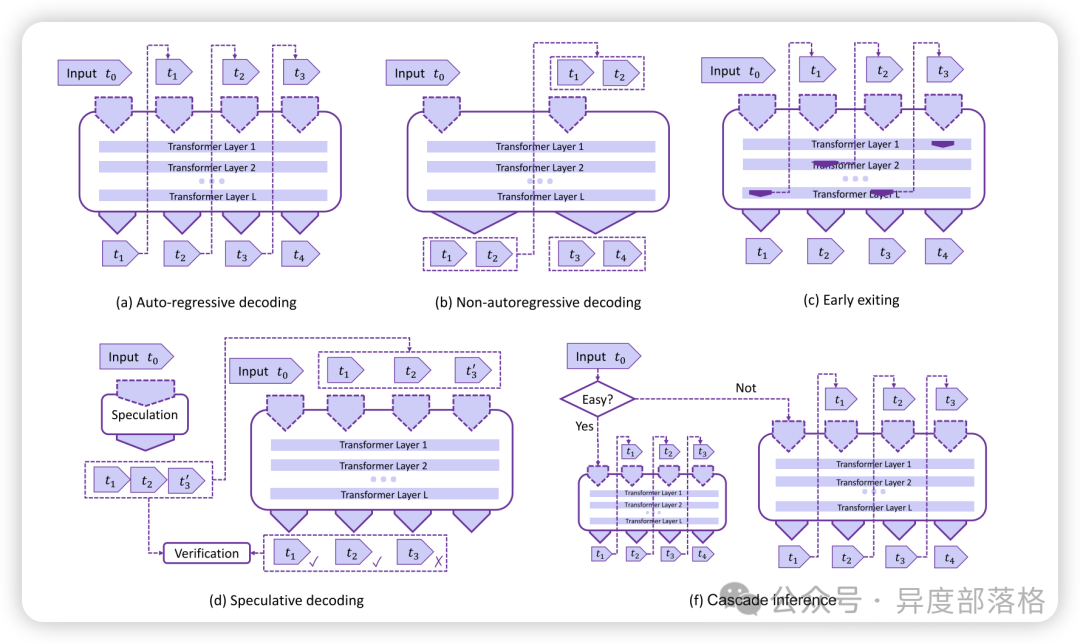
优化架构设计(Architecture Design)1. 配置缩减(Configuration Downsizing)2. 注意力机制简化(Attention Simplification)3. 激活共享(Activation Sharing)4. 条件计算(Conditional Computing)5. 循环单元(Recurrent Unit)基本概念:循环神经网络(RNN)及其变体(如 LSTM 和 GRU)在处理序列数据时具有显著优势,尤其是在捕捉长距离依赖关系方面。然而,传统的 RNN 在处理长序列时可能会遇到梯度消失或爆炸的问题。尽管 Transformer 模型在很大程度上解决了这些问题,但一些研究仍然尝试使用循环单元来替代 Transformer 模块,以在推理过程中实现线性计算和内存复杂度。 实现方法:RWKV 模型结合了 RNN 和 Transformer 的优点,利用线性递归单元(LRU)在推理过程中实现线性复杂度。RWKV 通过引入递归机制,使模型在每个时间步只需要线性计算,从而大幅减少计算量和内存占用。
模型压缩(Model Compression)1. 知识蒸馏(Knowledge Distillation)2. 网络剪枝(Network Pruning)这些算法创新方法,通过优化模型结构和推理过程,可以显著提高大型语言模型的推理效率,使其更适用于实际应用中的各种场景。 系统优化(System Optimizations)系统优化主要集中在硬件和系统层面,通过改进底层实现和资源管理,提高大型语言模型(LLM)推理的效率。以下是几种主要的系统优化方法: 低位量化(Low-bit Quantization)并行计算(Parallel Computation)内存管理(Memory Management)请求调度(Request Scheduling)内核优化(Kernel Optimization)减少填充和优化批处理,提高对变长序列的处理效率,如 Packing technique 和 Ragged tensor。-自动编译(Automatic Compilation):使用自动化编译工具优化模型在不同硬件平台上的执行效率,如 TVM、MLIR、JAX、OpenAI Triton。 这些系统优化方法通过改进底层硬件利用和资源管理,显著提高了大型语言模型的推理效率,使其在实际应用中更加高效和可靠。 LLM 推理性能指标下面是 Anyscale 公司,在 llmperf 工具中采用的一些推理性能测试指标: 每分钟完成请求数(RPS,Requests Per Second):衡量模型在一定时间内能处理的请求数量,反映了并发处理能力。 首字输出时间(TTFT,Time to First Token):从接收到请求到输出第一个字符的时间,表示初始响应速度。 字符间延迟(ITL,Inter-Token Latency):连续生成字符之间的平均时间,影响生成文本的流畅性和速度。 端到端延迟(End-to-End Latency):从请求发出到完成整个响应的时间,总体响应速度的体现。 每次典型请求的成本(Cost per Typical Request):综合考虑性能指标的成本效率。
| 









