|
在文本处理的过程中,图片和扫描件是无法绕开的数据类型,也是业界的处理难点,也是热点的优化方向。本篇文章将介绍一款相关的开源项目,该项目在github上拥有24.9k star,涨星飞快。它是一个OCR技术的集合体,能高效解决问题: 
项目特点 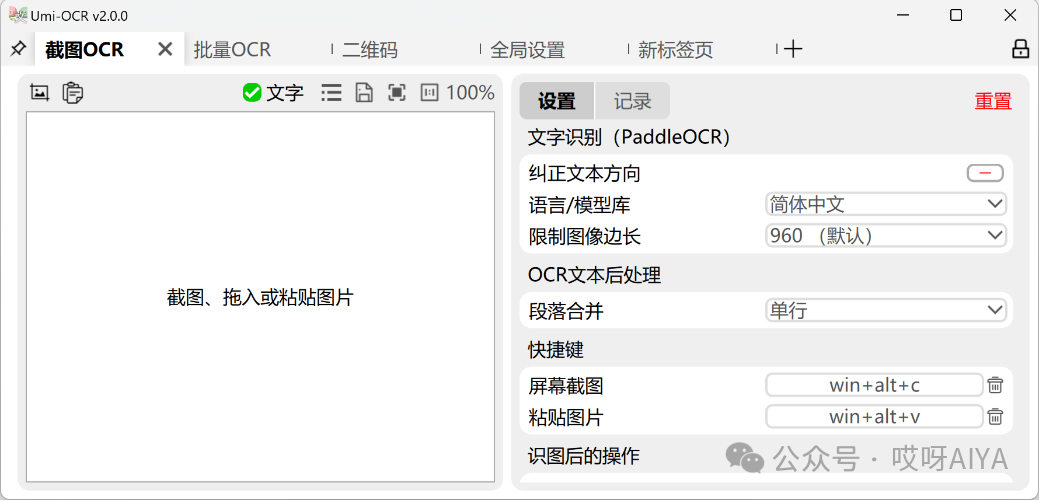
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: 4px solid rgb(248, 57, 41);">安装使用软件发布包下载为 .7z 压缩包或 .7z.exe 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件。本软件无需安装。解压后,点击 Umi-OCR.exe 即可启动程序。#下载地址https://hiroi-sora.lanzoul.com/s/umi-ocr(国内推荐,免注册/无限速)https://github.com/hiroi-sora/Umi-OCR/releases/latest ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: 4px solid rgb(248, 57, 41);">模块举例文档识别
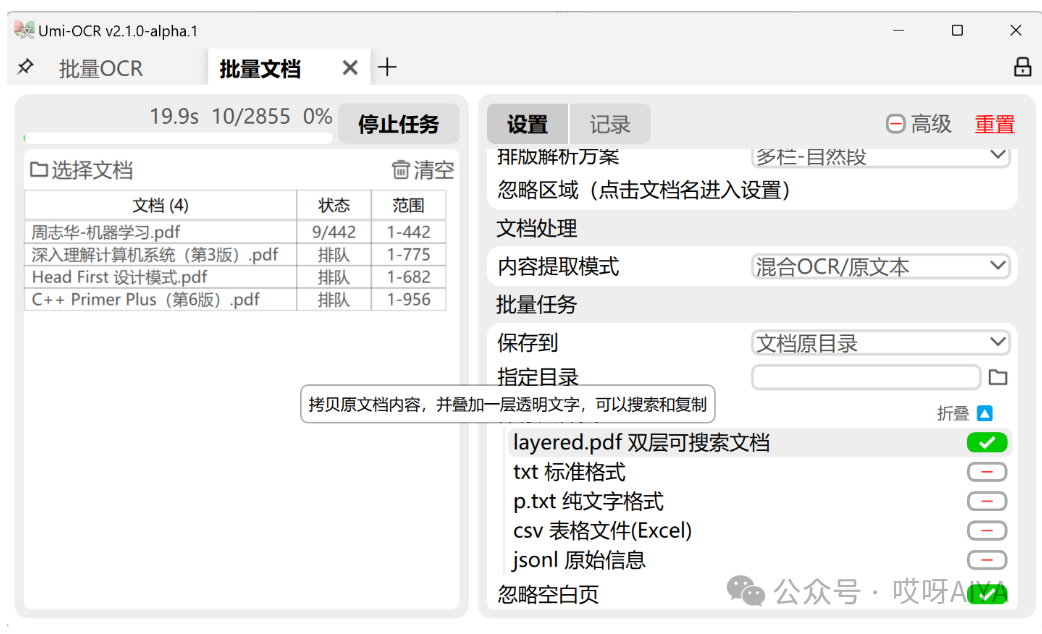
文档识别: 支持格式:pdf, xps, epub, mobi, fb2, cbz。 对扫描件进行OCR,或提取原有文本。可输出为双层可搜索PDF。 支持设定忽略区域,可用于排除页眉页脚的文字。 可设置任务完成后自动关机/休眠。
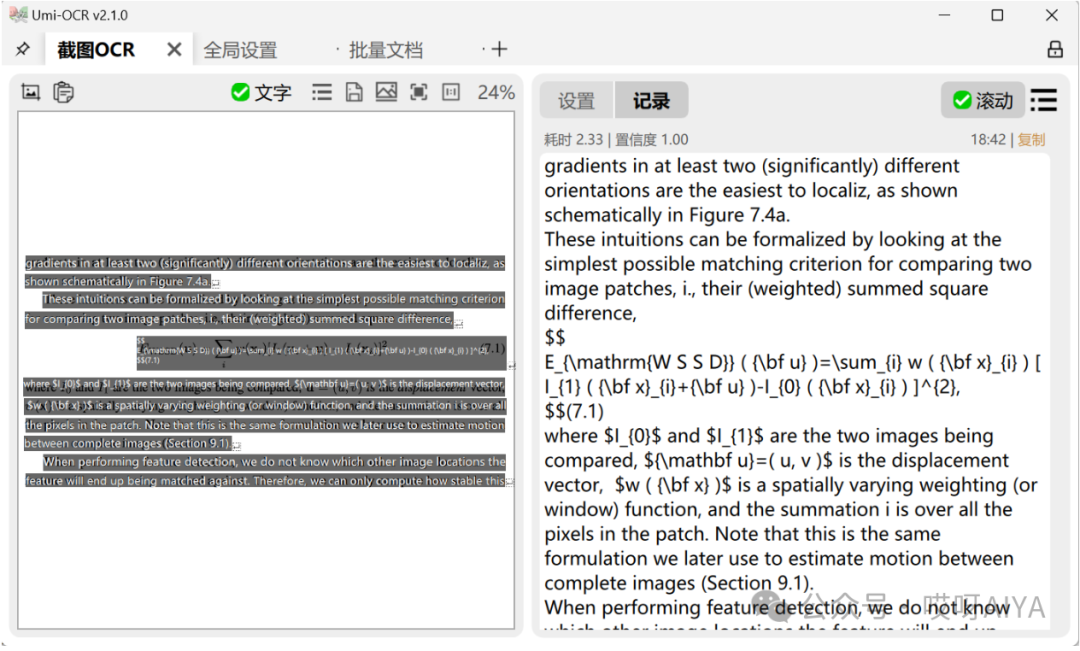
Umi-OCR的公司识别能力是基于Pix2Text实现的。Pix2Text 是一个开源OCR项目,能够识别既包含文字又包含数学公式的混合图片。 截图OCR 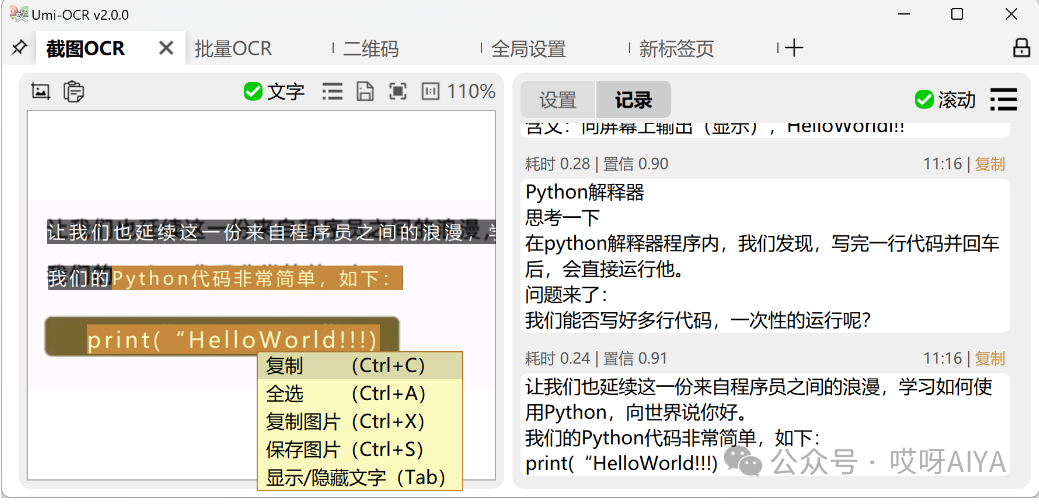
截图OCR:打开这一页后,就可以用快捷键唤起截图,识别图中的文字。  ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/>
关于OCR文本后处理 - 排版解析方案:可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案: 多栏-按自然段换行:适合大部分情景,自动识别多栏布局,按自然段规则进行换行。
多栏-总是换行:每段语句都进行换行。
多栏-无换行:强制将所有语句合并到同一行。
单栏-按自然段换行/总是换行/无换行:与上述类似,不过 不区分多栏布局。
单栏-保留缩进:适用于解析代码截图,保留行首缩进和行中空格。
不做处理:OCR引擎的原始输出,默认每段语句都进行换行。
上述方案,均能自动处理横排和竖排(从右到左)的排版。
未完待续,项目仍在持续迭代和优化中,进一步的使用可参见: https://github.com/hiroi-sora/Umi-OCR | 









