|
Ollama是一个用于构建大语言模型应用的工具,它提供了一些简单易用的CLI和服务器,能够让用户轻松下载、运行和管理各种开源LLM。
一. 如何使用? 本文以 windows 环境为例,但实际体验来看,同等硬件环境下 linux 系统体验会更流畅些。 1.1 安装ollama https://ollama.com/download/OllamaSetup.exe 特别记录下Docker版本的安装: CPU版本 dockerrun-d-vollama:/root/.ollama-p11434:11434--nameollamaollama/ollama GPU版本 同时还需要先安装 Nvidacontainertoolkit, 下载链接如下 https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#installation dockerrun-d--gpus=all-vollama:/root/.ollama-p11434:11434--nameollamaollama/ollama Ollama常用命令
启动ollama 查看已有模型列表 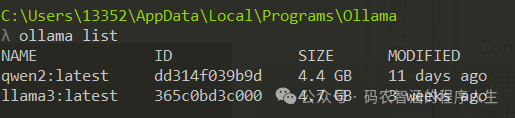
下载模型-以千问72b为例
运行模型
docker容器运行模型
dockerexec-itollamaollamarunqwen2:72b 
AI提效-本地代码补全助手+AI助手 我们通过结合代码生成模型+Ollama+IDE插件来打造一个强大的、模块化的、自娱自乐的代码补全助手。例如使用 Codeqwen 7B模型+vscode的continue插件,即可实现高效便捷的代码补全功能。 
推荐的模型组合:Codeqwen 7b+Qwen2 7B模型
ollamaruncodeqwenollamarunqwen2:7b 这两个模型中,codeqwen 7b是一个专门用于代码补全的模型,qwen2 7b又是个通用的聊天模型,并且两者都不是重量级模型,在本地运行也不会那么费劲。这两个模型结合起来就能很好地实现代码补全+AI助手的聊天功能。 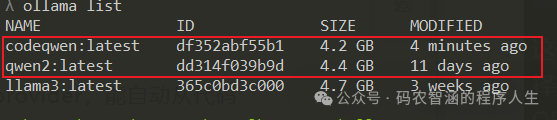
下载并运行好上述两个模型后,再去到vscode 进行配置,编辑 continue插件的config.json : 
{"models":[{"title":"Codeqwen7B","provider":"ollama","model":"codeqwen","apiBase":"http://127.0.0.1:11434"}],"tabAutocompleteModel":{"title":"Qwen27B","provider":"ollama","model":"qwen2:7b","apiBase":"http://127.0.0.1:11434"}}
再加上RAG向量检索优化聊天 首先,continue插件内置了 @codebase 上下文provider,能自动从代码库检索到最相关的代码片段。假如我们用自己的本地的聊天模型,那么借助 Ollama与LanceDB向量化技术,可以去更高效的进行代码检索和聊天体验。 ollamapullnomic-embed-textollamarunnomic-embed-text 继续配置 config.json 
都折腾完了之后跑下试试 代码补全效果及对话功能验证 
其他有价值的点还包括代码自动注释等功能可自行拓展。

至此,一个乞丐版 cursor 基本搭建完成了。 | 









