|
视觉强化微调(Visual-RFT)正式开源! DeepSeek-R1 继文本、数学推理、代码等领域大放异彩后,其基于规则奖励的强化学习方法首次成功迁移到多模态领域,并以 Visual-RFT(Visual Reinforcement Fine-Tuning)的形式全面开源。 其中视觉微调技术首次成功应用到多模态视觉领域。这会不会在多模态视觉领域也开启新的一轮冲击呢?  这一突破性技术使得视觉语言大模型具备更强的泛化能力,能以极少的样本完成高质量微调,在目标检测、分类、推理定位等任务中取得显著提升,甚至超越传统指令微调(SFT)方法。 论文地址: https://arxiv.org/abs/2503.01785 开源代码: https://github.com/Liuziyu77/Visual-RFT 什么是 Visual-RFT?Visual-RFT (Visual Reinforcement Fine-Tuning) 是一种在视觉感知任务中采用强化学习方法的模型微调技术,并借鉴 DeepSeek-R1 的强化学习策略(GPRO),为多模态任务引入可验证奖励(Verifiable Rewards) 机制,以增强大视觉语言模型(LVLMs, Large Vision-Language Models) 在不同任务上的推理能力。 主要创新点:强化学习迁移至视觉领域:突破传统认知,首次在多模态视觉大模型中验证基于规则奖励的有效性。 极少样本高效微调:相比传统 SFT 方法,Visual-RFT 仅需少量数据(10~1000 条样本)即可实现显著提升。 任务广泛:适用于 目标检测、开放目标检测、少样本分类和推理定位等任务。 推理能力增强:能够分析问题,进行 “think” 推理,从而实现更精准的视觉理解。
核心奖励函数- 目标检测:采用IoU 奖励(Intersection-over-Union, IoU Reward),通过计算预测边界框与真实边界框的重叠程度,确保模型不仅能识别目标,还能精准定位,提高检测的准确性和稳定性。
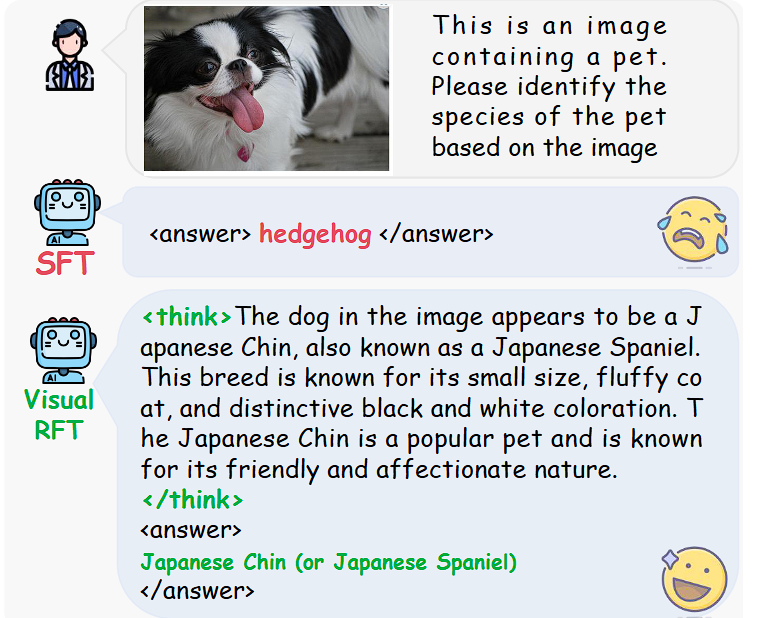
 - 图像分类:采用分类准确性奖励(Classification Accuracy Reward, CLS Reward),通过对比模型预测类别与真实类别是否一致进行奖励,引导模型在有限数据下仍能精准区分细粒度类别,提升分类泛化能力。
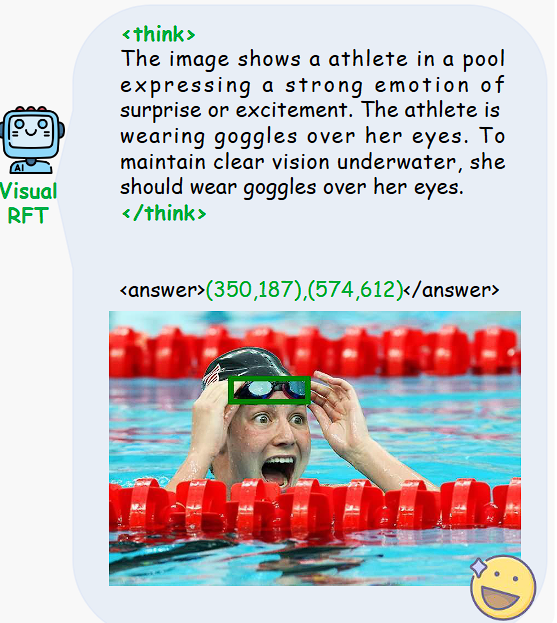
 - 推理定位:采用推理一致性奖励(Reasoning Consistency Reward),分析模型的推理逻辑是否符合指令,并结合 IoU 计算目标定位的准确性,确保模型不仅能回答问题,还能给出合理的思考过程,提高视觉推理能力。
 评测结果:Visual-RFT 远超 SFT我们先来看一个例子: 用户问这是一张关于花的图片,根据图片请找出花的品种。
模型先思考:这张图片显示了一朵黄色的毛茛花,它有绿色的茎,背景中有绿色的叶子。毛茛花是一种属于毛茛科的开花植物,以其明亮的黄色花朵闻名,通常生长在草地和牧场中。然后回答:毛茛花
 Visual-RFT VS 传统 SFT: | 方法 | 数据需求 | 泛化能力 | 推理能力 |
|---|
| SFT(监督微调) | 需要大量数据 | 泛化能力有限 | 仅依赖已有数据 | | Visual-RFT | 仅需 10~1000 条数据 | 泛化能力强 | 能推理 & 解释 |
论文的实验基于Qwen2-VL-2B/7B视觉语言模型,Visual-RFT 在以下任务中均大幅超越传统 SFT 方法:
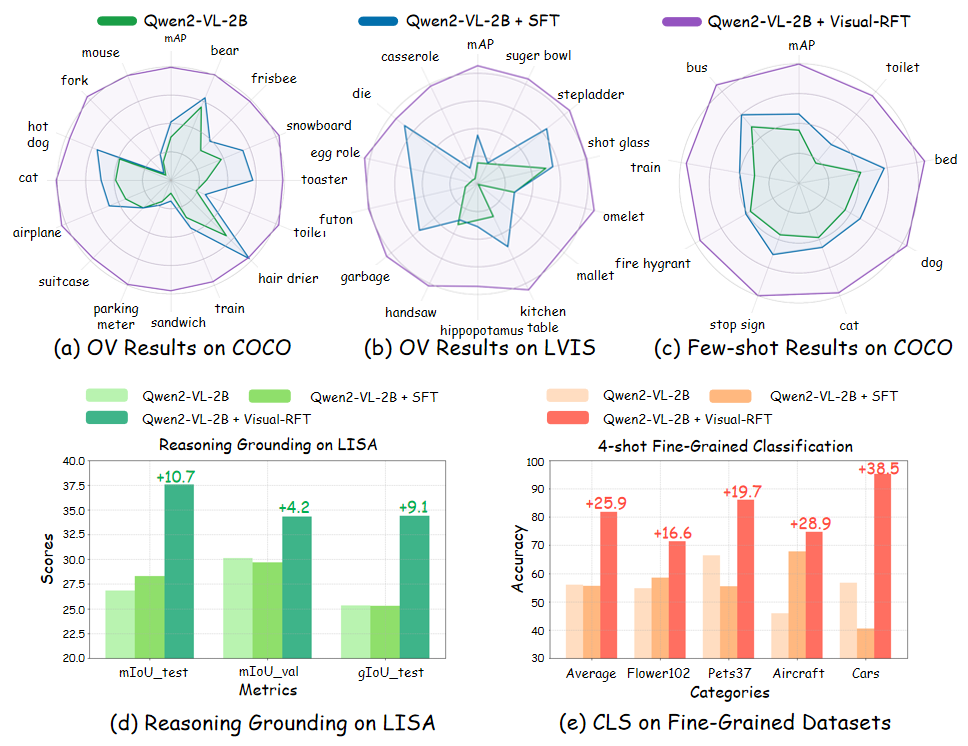 - 开放目标检测:模型仅用 65 类 COCO 数据即可泛化至新类别
Visual-RFT 开启视觉强化学习新时代Visual-RFT 是首个基于DeepSeek-R1强化微调方法的多模态迁移,填补了视觉语言大模型强化学习的空白。 它不仅提升了视觉推理能力,还极大降低了视觉任务微调的成本,对于CV & AI 社区都是一个重要突破。 异想天开一下,此方法是否也可以促进机器人的AI大脑的视觉模块的进步? 你认为强化学习是否会成为未来多模态大模型训练的主流方式················· | 









