|
搭建RAG系统时,使用向量检索的原因主要在于其能够有效解决传统关键字检索的局限性,并提升检索的准确性和效率。 那么关键字检索到底存在什么局限性?向量检索是如何解决的?这篇文章文章带你搞明白这背后的原因。 关键字检索的局限性 传统关键字检索依赖于词频统计,如基于BM25的倒排索引,这种方式无法理解语义信息,因此在处理复杂查询时存在以下问题: 语义理解不足:关键字检索仅匹配字面相同的词语,无法捕捉到语义上的相似性。例如,查询“苹果公司最新产品有哪些?”,关键词检索就可能返回关于水果“苹果”种植技术的文档。 模糊表达和拼写错误:对于模糊描述或拼写错误的查询,关键字检索容易返回不相关的结果。 长尾查询支持不足:当查询包含多个关键词或复杂结构时,关键字检索的召回率较低。 向量检索的优势 而向量检索是通过将文本转换为多维向量表示,并利用向量之间的相似度计算,比如:余弦相似度来匹配查询,从而克服了关键字检索的局限性: 语义理解能力强:向量检索能够捕捉文本的语义信息,即使查询和文档中没有完全相同的词语,或是不同种类的语言,也能找到语义上相关的匹配项。 例如,查询“为什么下雨前蚂蚁会排队搬家?”,即使文档中未明确提到“蚂蚁搬家”,模型仍能通过向量相似度关联到“昆虫感知气压变化”的科普内容。 处理模糊表达和拼写错误:向量检索对模糊表达和拼写错误具有一定的容错能力,能够通过语义相似度匹配到相关内容。 支持复杂查询:向量检索能够更好地处理包含多个关键词或复杂结构的查询,提高召回率和相关性。 向量检索与RAG系统 在RAG系统中,向量检索作为核心组件,负责从大规模数据集中快速找到与查询语义最接近的内容: 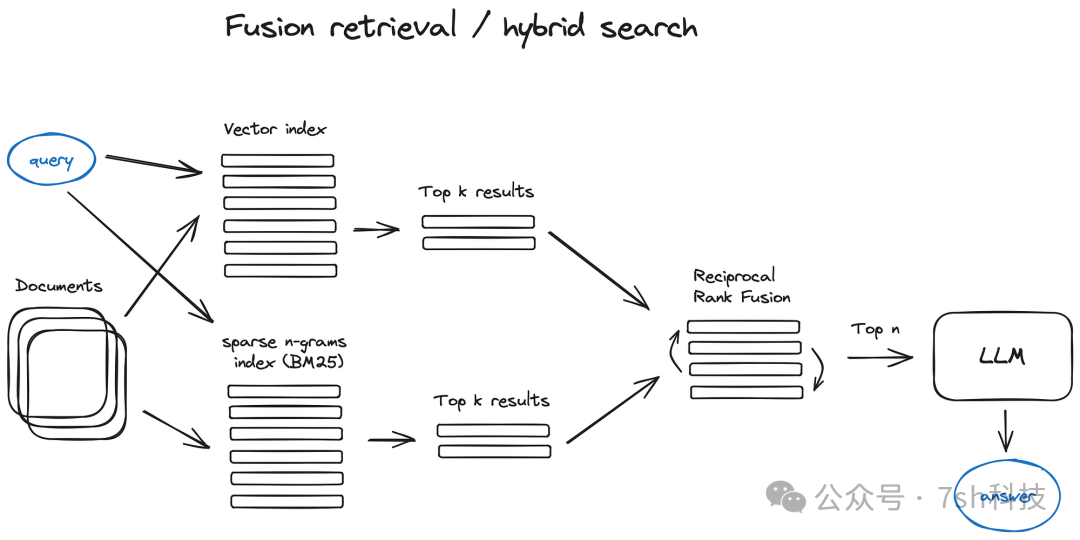
高效性:向量数据库支持高维数据的快速相似性搜索,能够在大规模数据集中快速找到最相似的向量。 灵活性:向量检索可以结合不同的嵌入模型和向量数据库技术,模型比如BGE-M3、text-embedding-3-small,向量数据库如Milvus、Faiss等,灵活应对不同场景的需求。 提升生成质量:通过向量检索获取的相关内容作为输入,再结合大语言模型生成更准确、更丰富的回答。 课代表小结 尽管向量检索在语义理解上具有优势,但在某些情况下,如:专有名词、人名、缩写词搜索,传统关键字检索可能更为有效。 因此,混合搜索方法:结合向量检索和关键字检索被提出,以弥补各自的不足,实现更广泛的文本搜索。 | 









