表4 OneEval评测榜单
在 OneEval 评测中,Grok 3 以 55.82% 的平均得分位列榜首,展现出较强的知识库利用与综合推理能力。值得关注的是,国产模型如 QWQ-32B、Hunyuan Turbo 和 Qwen 2.5-72B 紧随其后,表现稳健,在多类型知识库利用与复杂推理任务中展现出良好的竞争力,凸显了国产大模型在知识增强场景下的持续进步势头。
相比之下,GPT-4o、DeepSeek R1 等主流大模型在该评测中未展现出明显优势,而 Baichuan2-7B、Llama3.1-8B 等中小规模模型得分偏低,进一步说明在复杂知识推理任务中,模型的知识广度与深度仍是影响性能的关键因素。
表5 OneEval-Hard评测榜单
在 OneEval-Hard 子集评测中,各大语言模型整体得分相较原始 OneEval 有所下降,体现了该子集在推理难度与区分度上的显著提升。Grok 3 以 26.57% 的成绩位列第一,仍展现出较强的适应能力。OpenAI o1 和 Hunyuan Turbo 紧随其后,保持稳定表现。QWQ-32B、Qwen2.5-72B 等模型虽有一定回落,但在面对更具迷惑性与歧义性的任务中也展现出可提升的潜力。DeepSeek-R1-671B的表现相比在OneEval全集上的表现提升了一位。GPT-4o 下降了两名,反映其在复杂知识整合与深层推理方面仍有优化空间。多数中小规模模型如 Baichuan2-7B、Llama3.1-8B 得分低于 11%,提示其在高难度推理任务中仍面临挑战。总体来看,OneEval-Hard 为评估大模型在复杂、边缘化知识推理场景下的能力提供了更具挑战性的测试环境。
图3 文本推理实验结果
在OneEval文本推理任务中,Hunyuan-turbo以78.76%的成绩领先,展现对非结构化文本知识库的理解与运用能力。文本推理的评测数据主要来自于中文医学文献和英文生物文献,这可能是Hunyuan-turbo的优势所在。相比之下,GPT-4o和Claude 3.7 Sonnet在该任务中表现中等,显示出在中文文本或特定领域文本推理上的短板。
图4 知识图谱推理实验结果
在 OneEval 的知识图谱推理任务中,Grok 3 以 42.53% 的成绩领先,展现出较强的多跳推理能力和结构化知识校验能力,在该类任务中表现尤为突出。DeepSeek-R1-671B 和 DeepSeek V3 紧随其后,展现出对三元组结构较强的理解能力。GPT-4o、QWQ-32B 和 Qwen 2.5-72B 在该任务中表现稳健,具备一定的结构化知识处理能力。相比之下,Hunyuan-turbo、GLM4-9B 等在文本类推理中表现出色的模型,在知识图谱推理场景中的得分相对较低,反映出不同模型在结构化与非结构化知识处理能力上的差异与特色。整体来看,知识图谱推理对LLM的逻辑链整合、多跳推理与结构化知识理解能力提出了更高要求。
图5 表格推理实验结果
在OneEval的表格推理任务中,Grok 3以76.50%的表现夺得第一,展现出强大的表格数据处理与逻辑推理能力。DeepSeek-R1-671B(74.30%)和QWQ-32B(70.50%)紧随其后,也具备较强的表格理解与计算能力。GPT-4o和DeepSeek V3表现稳定,准确率接近70%,说明这些模型在数值计算、条件筛选和多步聚合等操作上已有较高水准。相比之下,Claude 3.7 Sonnet(28.30%)和Baichuan系列模型(尤其是7B仅为4.80%)在该任务中表现较弱。整体来看,性能优异的模型往往具备更强的“类程序化”推理能力。
图6 代码推理实验结果
在OneEval的代码推理任务中,GPT-4o以66.50%的准确率位居榜首,展现出其在自然语言到程序语言转换、代码逻辑理解及生成方面的强大能力。DeepSeek-R1-671B(65.60%)与Grok 3(64.00%)紧随其后,也表现出优秀的程序化推理与代码检索结合能力。Doubao-pro和GLM4-9B同样取得不俗成绩,说明一些国产模型在代码理解方面已有显著突破。
图7 通用领域表现排名
在通用领域任务中,Grok 3表现最佳,其次是DeepSeek-R1-671B和DeepSeek V3,表现优于GPT-4o。QWEN 2.5-72B和QWQ-32B虽然参数量相差一倍,但是表现基本持平。Llama3.1-70B、Doubao-pro与Claude 3.7 Sonnet得分在23–25%之间,处于中游水平,具备一定的开放领域能力。其余模型如Hunyuan-turbo、Qwen2.5-7B等得分一般(低于20%)。整体来看,模型规模与表现存在一定相关性,但也有部分轻量级模型展现出较优的性价比特征。
图8 医疗领域表现排名
医学任务中,Hunyuan-turbo以84.50%领先,远高于其他模型,显示出其在医疗知识上的深度训练。QWQ-32B和一系列模型如Qwen 2.5-72B、DeepSeek V3、GPT-4o均处于59%左右的中高水平。Qwen 2.5-72B、DeepSeek V3和GPT-4o得分均为59.50%,构成第二梯队,表现稳定,具备良好的医学推理能力。中游模型如Doubao-pro、Grok 3、DeepSeek-R1-671B和GLM4-9B得分接近,具备一定医学知识处理能力。整体来看,医学任务对模型专业知识储备和推理能力要求较高。
图9 政务领域表现排名
政务类任务上,各模型表现相对接近,Qwen2.5-7B、Grok 3、DeepSeek-R1-671B位列前三,说明即使是较小的模型(如7B)在政策类任务中也可能取得不错的效果,这类任务可能更依赖于语言模式识别和规则理解而非专业背景知识。Claude 3.7 Sonnet在该任务上排名最低,并显著低于其他模型,说明其在中文政务场景上的局限性。
图10 编程领域表现排名
在编程领域中,GPT-4o位居榜首,紧随其后的是DeepSeek-R1-671B和Grok 3,显示出这些模型在程序生成与理解方面的强大能力。尾部模型如Claude 3.7 Sonnet、Qwen2.5-7B、Llama3.1-8B及Baichuan2系列整体得分较低,说明在代码处理任务中存在明显短板。编程任务对模型的逻辑推理、上下文理解及语言精度提出较高要求,只有部分模型能在此类任务中维持高水平表现。
图11 科学领域表现排名
在科学领域中,领先模型为Llama3.1-70B和Grok 3,GPT-4o仅得48.75%,未能进入前五,说明科学推理可能依赖于复杂的知识整合能力,部分模型如Hunyuan、Qwen系列以及GLM4-9B表现优异,显示出较强的科学知识理解能力。整体上看,一些小参数量的LLM(如8B和9B)也在该领域上取得不错的结果。
图12 法律领域表现排名
在法律领域评测中,Hunyuan-turbo 以 83.87% 的准确率取得相对领先成绩,在法律专业知识的理解和应用方面表现稳健。Qwen 2.5-72B和 QWQ-32B的表现亦较为突出,体现了其在该领域任务中的良好适应能力。Grok 3、DeepSeek V3和Baichuan2-7B相对表现不足,说明在法律类任务中存在一定的短板。整体来看,该任务对模型的专业知识覆盖、事实准确性和条理性有较高要求,能够有效区分模型在专业垂直领域的实际应用能力。
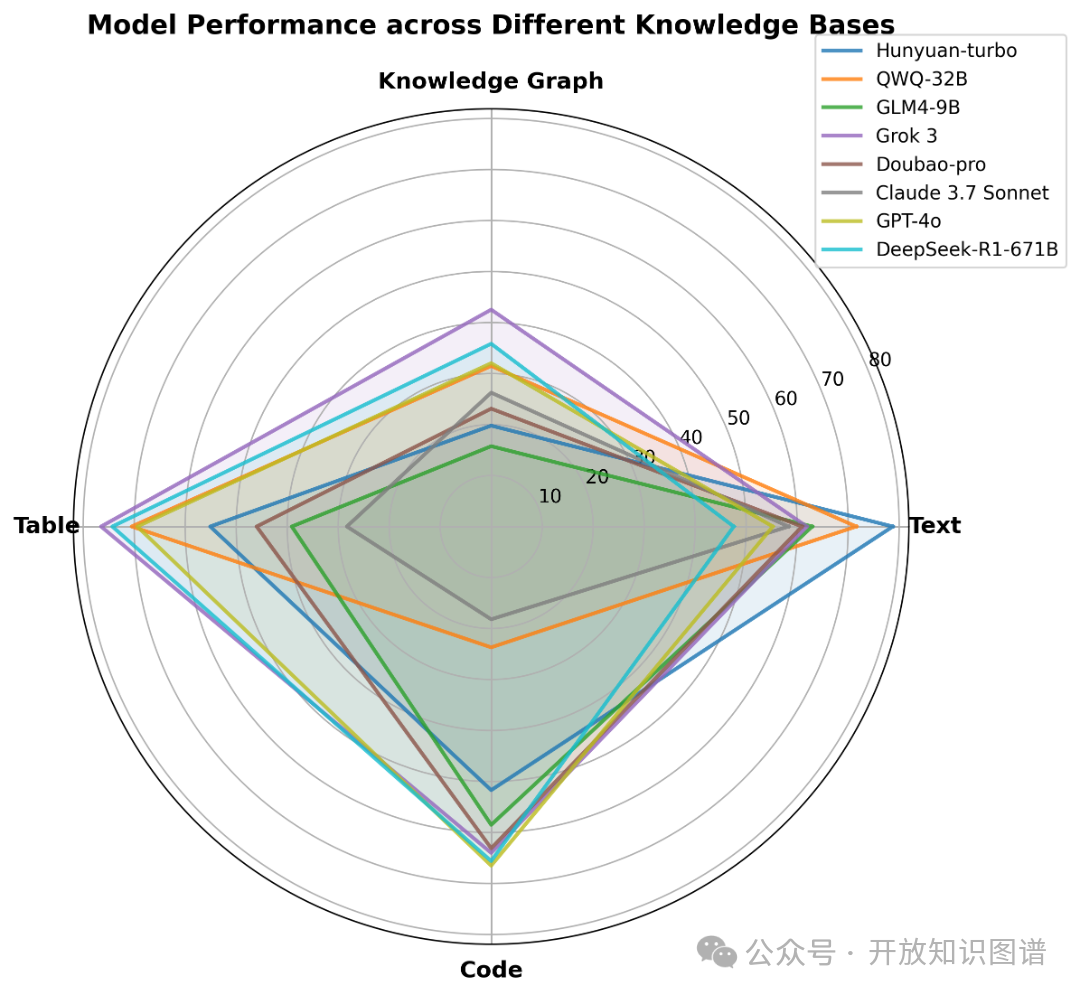
图13 不同知识库类型下的模型表现
图13展示了多个LLM在文本推理、知识图谱推理、表格推理和代码推理四个维度的性能差异。不同模型在推理任务中各有优势:Hunyuan-turbo适合文本理解类任务,Grok 3在知识图谱和表格推理方面表现较好,DeepSeek-R1-671B和GPT-4o则在代码推理任务中具有很强的竞争力。选择模型应根据具体应用场景和任务类型进行权衡。总体而言,这些LLM在理解和运用知识图谱的能力上还具有局限性。
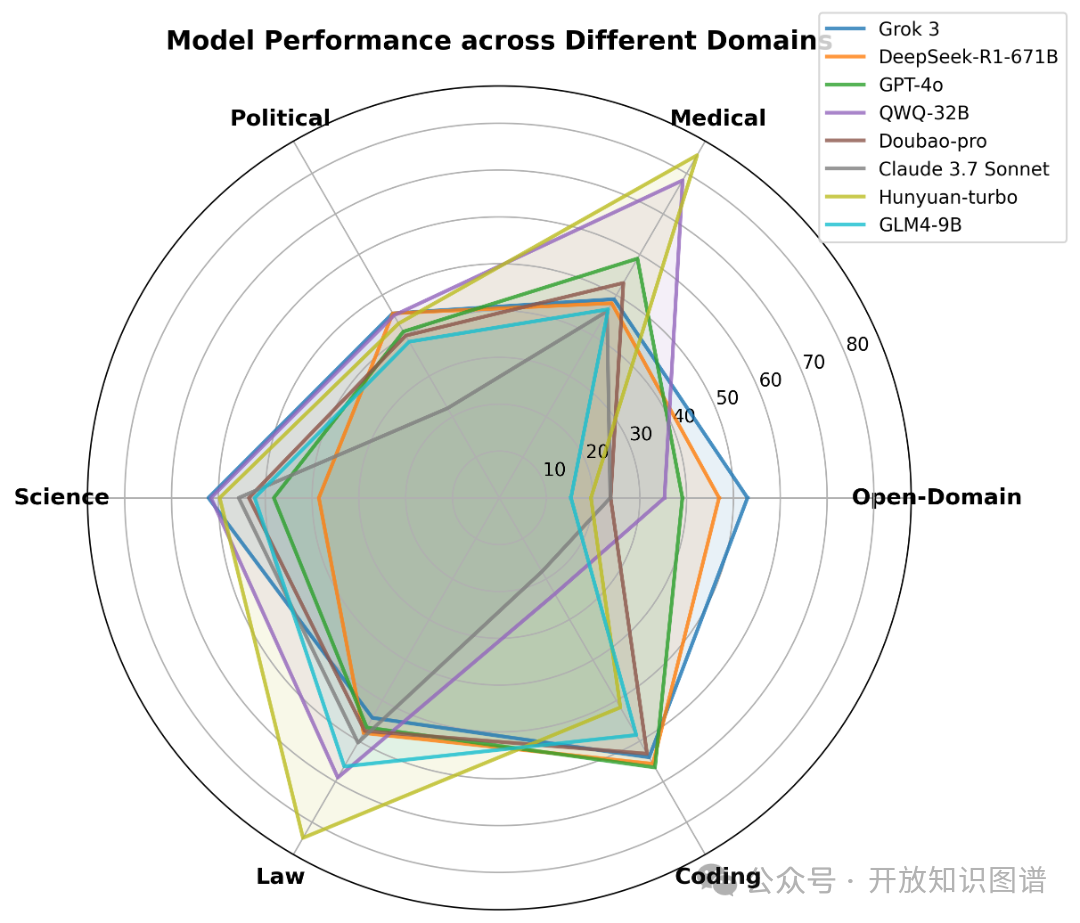
图14 不同领域下的模型表现
图14展示了多个大型语言模型在六个不同领域任务中的表现差异。可以观察到,不同模型在通用知识与专业领域任务之间的表现存在差异。Hunyuan-turbo在医疗与法律领域取得了较好成绩,显示出其在中文专业任务中的适应能力;Grok 3在多个领域的任务中表现稳定,尤其在开放领域问答与代码相关任务中相对突出。同时,多数模型在中文政务类任务中的推理能力仍面临一定挑战,相关场景下的适配性有待进一步提升。










