|
您是否正在遭遇以下困扰?有一个重要资料是纯图片格式,有一个文档是扫描版的PDF,想上传到dify的知识库做解析,可Dify根本读取不到。为了解决这个问题,我们可以使用MinerU来完美解决,让你的Dify知识库拥有解析图片的能力。本文将详细介绍一个工作流,使你的Dify知识库也拥有OCR的能力。 (本文Dify版本为1.3.1) 前期准备部署MinerU-API参考本公众号前两篇文章《在Dify中使用MinerU提取PDF》《MinerU-API | 支持多格式解析,进一步提升Dify文档能力》,获取MinerU-API代码,再用docker部署。本文就不再多赘述。 docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
创建Dify知识库创建一个Dify知识库,设定好基础的Embedding模型和Rerank模型  打开知识库,在地址栏里找到该知识库的ID,并记住它。  在知识库->API界面,生成一个API密钥,用于接口调用。  搭建MinerU知识库工作流工作流概述 整个工作流有三个代码块,分别用于处理接口参数、MinerU解析文档、创建Dify知识库文档 Process Parameters:用于处理接口参数,这边主要处理/datasets/{dataset_id}/document/create-by-text接口的参数。 MinerU提取:将PDF、图片转成Markdown格式的文本。 知识库-文档创建:调用Dify/datasets/{dataset_id}/document/create-by-text,在知识库中创建文档。Python代码如下: importrequests
defmain(api_key,file_name,content, api_params, dataset_id):
headers = {
'Authorization':f'Bearer{api_key}',
'Content-Type':'application/json',
}
api_params.update({
"name": file_name,
"text": content,
})
response = requests.post(
f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text',
headers=headers,
json=api_params,
)
return{"result":response.text}
效果测试以一份网页打印出的PDF文档为例,对比直传知识库,和使用MinerU工作流的效果。 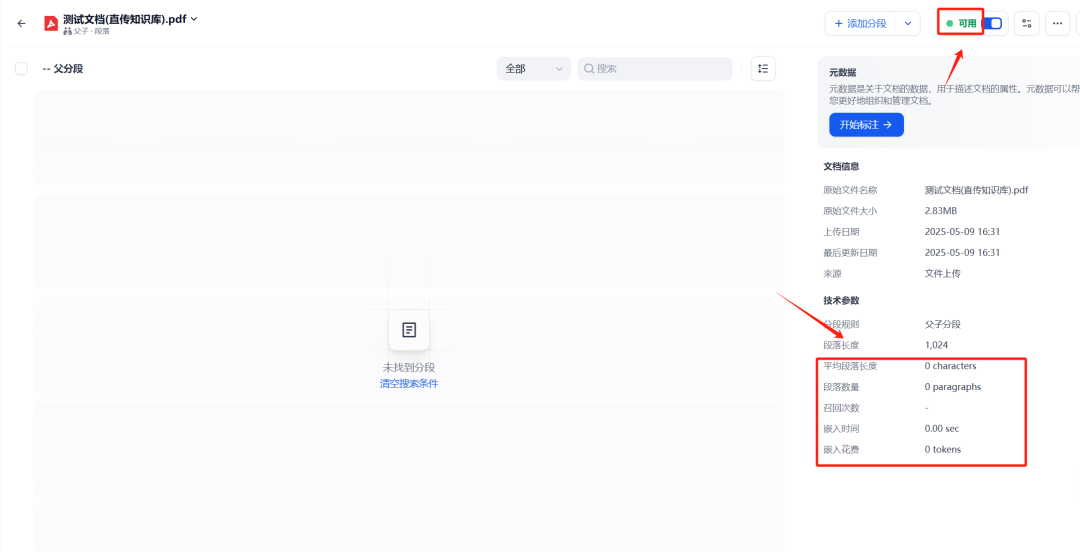 很显然,通过直传知识库,虽然文档能上传成功,可是里面的内容用Dify原生的知识库能力,完全无法解析。  通过MinerU工作流创建文档,显然工作流成功执行,并且返回了接口调用结果。在知识库里查看一下。  文档创建以后,Dify会自动对文档进行索引。待文档索引完成后,进行召回测试。  | 









