|
检索增强生成系统(RAG)正从早期“检索+生成”的简单拼接,走向融合自适应知识组织、多轮推理、动态检索的复杂知识系统(典型代表如 DeepResearch、Search-o1)。但这种复杂度的提升,使开发者在方法复现、快速迭代新想法时,面临着高昂的工程实现成本。 基于 Model Context Protocol (MCP) 架构设计的 RAG 框架。这一设计让科研人员只需编写YAML文件,就可以直接声明串行、循环、条件分支等复杂逻辑,从而以极低的代码量快速实现多阶段推理系统。 其核心思路是: - 组件化封装:将 RAG 的核心组件封装为标准化的独立 MCP Server;
- 灵活调用与扩展:提供函数级 Tool 接口,支持功能的灵活调用与扩展;
- 轻量流程编排:借助MCP Client,建立自上而下的简洁化链路搭建;
与传统框架相比,UltraRAG 2.0 显著降低了复杂 RAG 系统的技术门槛与学习成本,让研究者能够将更多精力投入到实验设计与算法创新上,而不是陷入冗长的工程实现。 UltraRAG传统的RAG,如:IRCoT,依赖基于模型生成的 CoT 进行多轮检索直至产出最终答案,整体流程相当复杂。 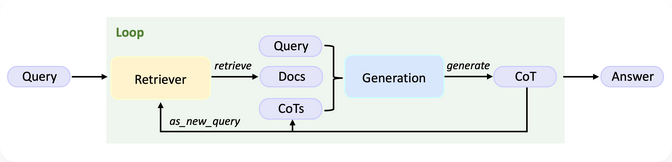 仅Pipeline 部分就需要近 900 行手写逻辑;即便使用标杆级 RAG 框架(如 FlashRAG),也仍需超过 110 行代码。相比之下,UltraRAG 2.0 只需约 50 行代码即可完成同等功能。更值得强调的是,其中约一半还是用于编排的 Yaml 伪代码,这大幅降低了开发门槛与实现成本。 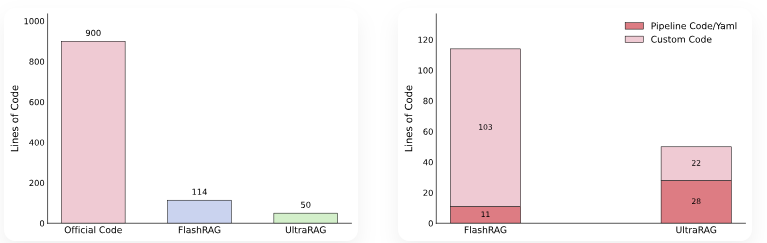 可以看到,FlashRAG 的实现仍然需要较长的控制逻辑,涉及显式的循环、条件判断与状态更新。而在 UltraRAG 2.0 中,这些逻辑仅需几行 Pipeline YAML 配置即可表达,分支与循环均以简洁的声明方式完成,避免了繁琐的手动编码。 UltraRAG实现高性能RAG可以将Retriever、Generation、Router等模块通过 YAML 串联,构建了一个同时具备循环与条件分支的推理流程,实现了Plan 生成 → 知识整理 → 子问题生成等关键步骤,而这一切仅需不到 100 行代码。 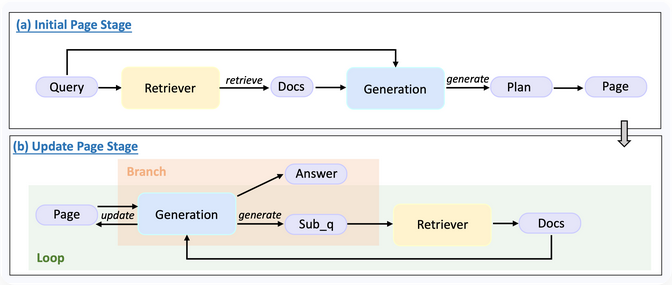 在性能上,该系统在复杂多跳问题上,相较 Vanilla RAG **性能提升约 12%**,充分验证了 UltraRAG 2.0 在快速构建复杂推理系统方面的潜力。 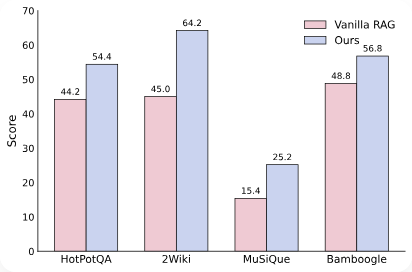 MCP成就高性能UltraRAG在不同的 RAG 系统中,检索、生成等核心能力在功能上具有高度相似性,但由于开发者实现策略各异,模块之间往往缺乏统一接口,难以跨项目复用。Model Context Protocol (MCP) 作为一种开放协议,规范了为大型语言模型(LLMs)提供上下文的标准方式,并采用Client–Server 架构,使得遵循该协议开发的 Server 组件可以在不同系统间无缝复用。 UltraRAG 基于MCP 架构,将 RAG 系统中的检索、生成、评测等核心功能抽象并封装为相互独立的MCP Server,并通过标准化的函数级 Tool 接口实现调用。这一设计既保证了模块功能扩展的灵活性,又允许新模块以“热插拔”的方式接入,无需对全局代码进行侵入式修改。 在科研场景中,这种架构让研究者能够以极低的代码量快速适配新的模型或算法,同时保持整体系统的稳定性与一致性。  UltraRAG之所以能够在低代码条件下支持复杂系统的构建,核心在于其底层对多结构Pipeline 流程控制的原生支持。无论是串行、循环还是条件分支,所有控制逻辑均可在YAML 层完成定义与调度,覆盖复杂推理任务所需的多种流程表达方式。 在实际运行中,推理流程的调度由内置Client执行,其逻辑完全由用户编写的外部Pipeline YAML 脚本描述,从而完成与底层实现的解耦。开发者可以像使用编程语言关键字一样调用 loop、step 等指令,以声明式方式快速构建多阶段推理流程。 https://github.c
| 









