|
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。 
RAGFlow 的核心优势在于其深度文档理解能力,它能够从各类复杂格式的非结构化数据中提取真知灼见,并支持无限上下文场景。通过基于模板的文本切片机制,RAGFlow 保证了结果的可控性和可解释性,并最大程度降低了幻觉的风险。此外,RAGFlow 兼容各类异构数据源,并提供自动化 RAG 工作流,方便用户集成到自己的系统中。
RAGFlow 的核心优势 深度文档理解:"Quality in, quality out",RAGFlow基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。真正在无限上下文(token)的场景下快速完成大海捞针测试。 可控可解释的文本切片:RAGFlow 提供多种文本模板,用户可以根据需求选择合适的模板,确保结果的可控性和可解释性。 降低幻觉:RAGFlow 的文本切片过程可视化,支持手动调整,答案提供关键引用的快照并支持追根溯源,从而降低幻觉的风险。 兼容各类异构数据源:RAGFlow 支持 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据, 网页等。对于无序文本数据,RAGFlow 可以自动提取其中的关键信息并转化为结构化表示;而对于结构化数据,它则能灵活切入,挖掘内在的语义联系。最终将这两种不同来源的数据统一进行索引和检索,为用户提供一站式的数据处理和问答体验。 自动化 RAG 工作流:RAGFlow 支持全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统;大语言模型 LLM 以及向量模型均支持配置,用户可以根据实际需求自主选择。;基于多路召回、融合重排序,能够权衡上下文语义和关键词匹配两个维度,实现高效的相关性计算;提供易用的 API,可以轻松集成到各类企业系统,无论是对个人用户还是企业开发者,都极大方便了二次开发和系统集成工作。
DeepDoc:深度文档理解的基石 DeepDoc 是 RAGFlow 的核心组件,它利用视觉信息和解析技术,对文档进行深度理解,提取文本、表格和图像等信息。DeepDoc 的功能模块包括:
系统架构 系统由以下组件组成: 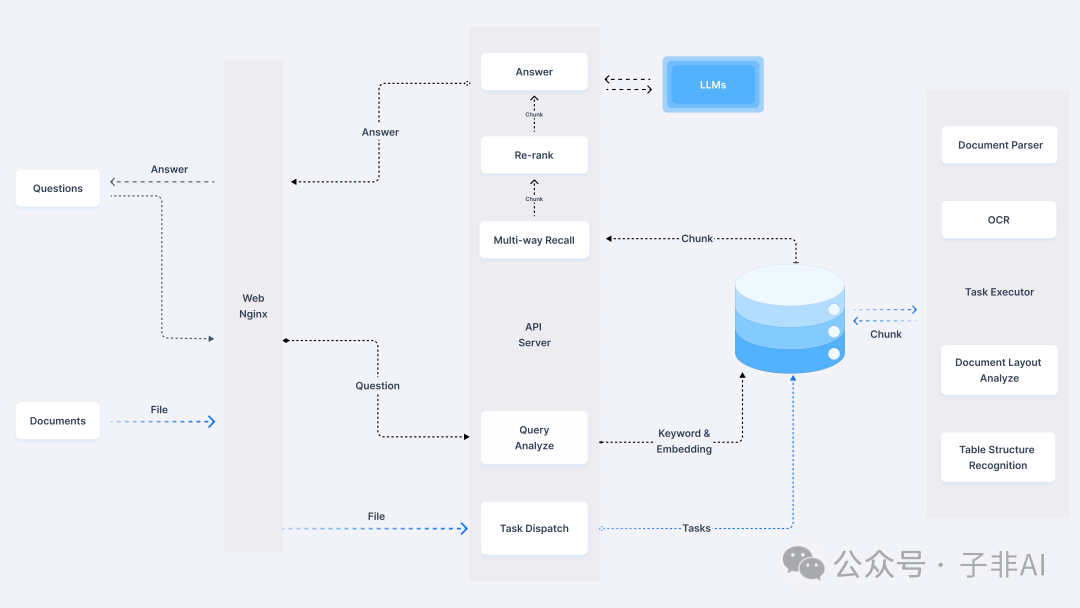
RAG系统架构的工作流程如下: 用户输入查询。 查询分析器分析查询并提取关键信息。 检索模块使用关键信息从文档中检索相关的信息。 重排模块对检索到的信息进行排序和过滤。 LLM使用排序后的信息生成最终答案或输出。
核心代码实现 OCR识别:ocr.py 代码导读和解析: ocr.py代码定义了一个OCR 的类 OCR 以及相关的辅助类和函数。它利用 ONNX Runtime 进行推理,并使用 PaddleOCR 模型进行文本检测和识别。
主要组件:TextRecognizer 类: 负责文本识别。使用 ONNX Runtime 加载识别模型 (rec.onnx)。对图像进行预处理,包括缩放、归一化和填充。使用 CTCLabelDecode 进行后处理,将模型输出转换为文本。TextDetector 类: 负责文本检测。使用 ONNX Runtime 加载检测模型 (det.onnx)。对图像进行预处理,包括缩放、归一化和通道转换。使用 DBPostProcess 进行后处理,提取文本框坐标。对文本框进行过滤和排序。OCR 类: 整合检测和识别功能。初始化 TextDetector 和 TextRecognizer 实例。定义 detect 方法,用于检测图像中的文本框。定义 recognize 方法,用于识别单个文本框中的文本。定义 __call__ 方法,用于对图像进行端到端 OCR 处理,包括检测和识别。
辅助函数:transform(data, ops=None): 对数据进行一系列操作。create_operators(op_param_list, global_config=None): 根据配置创建操作列表。load_model(model_dir, nm): 加载 ONNX 模型。
代码流程:1.创建 OCR 实例。2.调用 __call__ 方法,传入图像数据。3.__call__ 方法首先使用 TextDetector 进行文本检测,获取文本框坐标。4.对每个文本框,使用 get_rotate_crop_image 方法进行旋转和裁剪。5.使用 TextRecognizer 对裁剪后的图像进行文本识别。6.过滤掉置信度低于阈值的识别结果。7.返回最终的文本框坐标和识别结果。
代码特点:使用 ONNX Runtime 进行推理,可以实现跨平台部署。支持多种预处理和后处理操作,可以灵活调整模型的行为。代码结构清晰,易于理解和扩展。
文档板式分析实现(recognizer.py)
RAGFlow提供了一个用于文档板式分析的解决方案,可以识别文档图像中的不同区域类型,例如表格、标题、段落等。它可以用于文档理解、信息提取等任务。 代码定义了一个名为Recognizer的类,用于对文档图像进行板式分析,识别不同类型的区域,例如表格、标题、段落等。它使用ONNX Runtime进行推理。
主要组件:Recognizer 类: 负责板式分析的核心功能。使用ONNX Runtime加载模型 (task_name.onnx)。定义多种排序方法,例如按Y坐标、X坐标、类别置信度等排序。定义计算重叠区域的方法。定义布局清理方法,用于消除冗余或重叠的布局区域。定义创建模型输入的方法。定义后处理方法,将模型输出转换为布局信息。定义 __call__ 方法,用于对图像进行板式分析。
辅助函数:排序方法: sort_Y_firstly, sort_X_firstly, sort_C_firstly, sort_R_firstlyoverlapped_area(a, b, ratio=True): 计算两个矩形区域的重叠面积或重叠比例。layouts_cleanup(boxes, layouts, far=2, thr=0.7): 清理布局信息,消除冗余或重叠的区域。查找重叠区域的方法: find_overlapped, find_horizontally_tightest_fit, find_overlapped_with_threashold
代码流程:1.创建 Recognizer 实例,指定类别列表和任务名称。2.调用 __call__ 方法,传入图像列表和置信度阈值。3.__call__ 方法首先将图像列表转换为模型输入格式。4.使用ONNX Runtime进行推理,获取模型输出。5.对模型输出进行后处理,提取布局信息,包括区域类型、坐标和置信度。6.返回最终的布局信息列表。
代码特点:使用ONNX Runtime进行推理,可以实现跨平台部署。支持批量推理,提高处理效率。提供多种排序和重叠区域查找方法,方便布局分析和后处理。代码结构清晰,易于理解和扩展。
可能的改进:支持GPU加速,提高推理速度。支持更复杂的布局分析,例如表格结构识别、文字方向检测等。集成OCR功能,可以识别布局区域内的文本内容。
RAGFlow 的应用场景 RAGFlow 可以应用于各种场景,例如: 智能客服:帮助客服人员快速找到相关信息,并生成更准确、更专业的回复,提升客户满意度。 知识库构建:帮助企业构建知识库,并提供智能问答服务,方便员工快速获取所需信息。 文档摘要:自动生成文档摘要,帮助用户快速了解文档内容,节省时间和精力。 信息检索:帮助用户从海量数据中检索相关信息,提高信息检索效率和准确率。 人才招聘:DeepDoc 的简历解析功能可以帮助 HR 快速筛选简历,提高招聘效率。
代码及Demo 代码库:https://github.com/infiniflow/ragflow 在线Demo:https://demo.ragflow.io/
RAGFlow:开启文档智能的新时代 RAGFlow 作为新一代开源 RAG 引擎,在文档理解能力、可控可解释性、防幻觉性、异构数据支持、工作流灵活性等多个维度均展现出了卓越的表现。相信通过 RAGFlow 的加持,个人和企业在面对纷繁复杂的文档数据时,将不再像摸象认形那般被蒙在鼓里,而是拥有了高效获取真知灼见的力量。 
对于正在寻求突破文档数据利用瓶颈的企业来说,RAGFlow 绝对是一款值得拥抱的利器。 我们有理由期待,在不久的将来,以 RAGFlow 为代表的新型文档智能基础设施,将为知识型经济带来前所未有的推动力。 | 









