|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15.4px;font-weight: bold;display: table;margin-right: auto;margin-bottom: 2em;margin-left: auto;padding-right: 0.2em;padding-left: 0.2em;background: rgb(0, 152, 116);color: rgb(255, 255, 255);">Milvus 向量数据库ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">上一篇文章介绍了Milvus向量数据库安装部署,这次我们来介绍一下Milvus的应用实例。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">通过Milvus的相似性搜索的特性,可以应用的场景有很多:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;padding-left: 1em;list-style: circle;color: rgb(63, 63, 63);" class="list-paddingleft-1">•图像相似性搜索:图像可搜索并立即从海量数据库中返回最相似的图像。 •视频相似度搜索:通过将关键帧转换为向量,然后将结果输入 Milvus,可以近乎实时地搜索和推荐数十亿视频。 •音频相似度搜索:快速查询语音、音乐、音效等海量音频数据,表面相似声音。 •推荐系统:根据用户行为和需求推荐信息或产品。 •问答系统:交互式数字 QA 聊天机器人,自动回答用户问题。 •DNA序列分类:通过比较相似的DNA序列,在毫秒内准确梳理出基因的分类。 •文本搜索引擎:通过将关键字与文本数据库进行比较,帮助用户找到他们正在寻找的信息。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">这次我们来介绍一下Milvus与Huggingface 大模型的结合应用——Question-Answering 问答系统。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15.4px;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(0, 152, 116);color: rgb(255, 255, 255);">HuggingfaceingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">Hugging Face是一个面向自然语言处理(NLP)任务的开源平台,提供了丰富的预训练模型(Model)和数据集(Dataset)ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">本次使用到的Model和Dataset:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">Model:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France.
Dataset: https://huggingface.co/datasets/squad 
0. Before you begin环境准备,下载依赖: pipinstalltransformersdatasetspymilvustorch 1. Create Collection首先本地需要启动Milvus: 

在Milvus创建Collection,并创建index: frompymilvusimportconnections,FieldSchema,CollectionSchema,DataType,Collection,utility
DATASET='squad'#HuggingfaceDatasettouse
MODEL='bert-base-uncased'#Transformertouseforembeddings
TOKENIZATION_BATCH_SIZE=1000#Batchsizefortokenizingoperation
INFERENCE_BATCH_SIZE=64#batchsizefortransformer
INSERT_RATIO=.001#Howmanytitlestoembedandinsert
COLLECTION_NAME='huggingface_db'#Collectionname
DIMENSION=768#Embeddingssize
LIMIT=10#Howmanyresultstosearchfor
URI="http://192.168.153.100:19530"
TOKEN="root:Milvus"
connections.connect(uri=URI,token=TOKEN)
ifutility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
fields=[
FieldSchema(name='id',dtype=DataType.INT64,is_primary=True,auto_id=True),
FieldSchema(name='original_question',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='original_question_embedding',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)
]
schema=CollectionSchema(fields=fields)
collection=Collection(name=COLLECTION_NAME,schema=schema)
index_params={
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1536}
}
collection.create_index(field_name="original_question_embedding",index_params=index_params)
print("Createindexdone.")

2. Insert data我们创建了Collection之后,就要开始插入数据了。 1.将Dataset的数据进行分词处理 2.将数据转化为向量 3.将问题、问题的向量以及问题的答案插入到Milvus
frompymilvusimportconnections,FieldSchema,CollectionSchema,DataType,Collection,utility
fromdatasetsimportload_dataset_builder,load_dataset,Dataset
fromtransformersimportAutoTokenizer,AutoModel
fromtorchimportclamp,sum
DATASET='squad'#HuggingfaceDatasettouse
MODEL='bert-base-uncased'#Transformertouseforembeddings
TOKENIZATION_BATCH_SIZE=1000#Batchsizefortokenizingoperation
INFERENCE_BATCH_SIZE=64#batchsizefortransformer
INSERT_RATIO=.001#Howmanytitlestoembedandinsert
COLLECTION_NAME='huggingface_db'#Collectionname
DIMENSION=768#Embeddingssize
LIMIT=10#Howmanyresultstosearchfor
URI="http://192.168.153.100:19530"
TOKEN="root:Milvus"
connections.connect(uri=URI,token=TOKEN)
data_dataset=load_dataset(DATASET,split='all')
data_dataset=data_dataset.train_test_split(test_size=INSERT_RATIO,seed=42)['test']
data_dataset=data_dataset.map(lambdaval:{'answer':val['answers']['text'][0]},remove_columns=['answers'])
tokenizer=AutoTokenizer.from_pretrained(MODEL)
deftokenize_question(batch):
results=tokenizer(batch['question'],add_special_tokens=True,truncation=True,padding="max_length",return_attention_mask=True,return_tensors="pt")
batch['input_ids']=results['input_ids']
batch['token_type_ids']=results['token_type_ids']
batch['attention_mask']=results['attention_mask']
returnbatch
data_dataset=data_dataset.map(tokenize_question,batch_size=TOKENIZATION_BATCH_SIZE,batched=True)
data_dataset.set_format('torch',columns=['input_ids','token_type_ids','attention_mask'],output_all_columns=True)
model=AutoModel.from_pretrained(MODEL)
defembed(batch):
sentence_embs=model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded=batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding']=sum(sentence_embs*input_mask_expanded,1)/clamp(input_mask_expanded.sum(1),min=1e-9)
returnbatch
data_dataset=data_dataset.map(embed,remove_columns=['input_ids','token_type_ids','attention_mask'],batched=True,batch_size=INFERENCE_BATCH_SIZE)
fields=[
FieldSchema(name='id',dtype=DataType.INT64,is_primary=True,auto_id=True),
FieldSchema(name='original_question',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='original_question_embedding',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)
]
schema=CollectionSchema(fields=fields)
collection=Collection(name=COLLECTION_NAME,schema=schema)
collection.load()
definsert_function(batch):
insertable=[
batch['question'],
[x[:995]+'...'iflen(x)>999elsexforxinbatch['answer']],
batch['question_embedding'].tolist()
]
collection.insert(insertable)
data_dataset.map(insert_function,batched=True,batch_size=64)
collection.flush()
print("Insertdatadone.")

3. Ask question所有的数据插入到Milvus向量数据库后,就可以提出问题并查看相似度最高的答案。 frompymilvusimportconnections,FieldSchema,CollectionSchema,DataType,Collection,utility
fromdatasetsimportload_dataset_builder,load_dataset,Dataset
fromtransformersimportAutoTokenizer,AutoModel
fromtorchimportclamp,sum
DATASET='squad'#HuggingfaceDatasettouse
MODEL='bert-base-uncased'#Transformertouseforembeddings
TOKENIZATION_BATCH_SIZE=1000#Batchsizefortokenizingoperation
INFERENCE_BATCH_SIZE=64#batchsizefortransformer
INSERT_RATIO=.001#Howmanytitlestoembedandinsert
COLLECTION_NAME='huggingface_db'#Collectionname
DIMENSION=768#Embeddingssize
LIMIT=10#Howmanyresultstosearchfor
URI="http://192.168.153.100:19530"
TOKEN="root:Milvus"
connections.connect(uri=URI,token=TOKEN)
fields=[
FieldSchema(name='id',dtype=DataType.INT64,is_primary=True,auto_id=True),
FieldSchema(name='original_question',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length=1000),
FieldSchema(name='original_question_embedding',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)
]
schema=CollectionSchema(fields=fields)
collection=Collection(name=COLLECTION_NAME,schema=schema)
collection.load()
tokenizer=AutoTokenizer.from_pretrained(MODEL)
deftokenize_question(batch):
results=tokenizer(batch['question'],add_special_tokens=True,truncation=True,padding="max_length",return_attention_mask=True,return_tensors="pt")
batch['input_ids']=results['input_ids']
batch['token_type_ids']=results['token_type_ids']
batch['attention_mask']=results['attention_mask']
returnbatch
model=AutoModel.from_pretrained(MODEL)
defembed(batch):
sentence_embs=model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded=batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding']=sum(sentence_embs*input_mask_expanded,1)/clamp(input_mask_expanded.sum(1),min=1e-9)
returnbatch
questions={'question':['Whenwaschemistryinvented?','WhenwasEisenhowerborn?']}
question_dataset=Dataset.from_dict(questions)
question_dataset=question_dataset.map(tokenize_question,batched=True,batch_size=TOKENIZATION_BATCH_SIZE)
question_dataset.set_format('torch',columns=['input_ids','token_type_ids','attention_mask'],output_all_columns=True)
question_dataset=question_dataset.map(embed,remove_columns=['input_ids','token_type_ids','attention_mask'],batched=True,batch_size=INFERENCE_BATCH_SIZE)
defsearch(batch):
res=collection.search(batch['question_embedding'].tolist(),anns_field='original_question_embedding',param={},output_fields=['answer','original_question'],limit=LIMIT)
overall_id=[]
overall_distance=[]
overall_answer=[]
overall_original_question=[]
forhitsinres:
ids=[]
distance=[]
answer=[]
original_question=[]
forhitinhits:
ids.append(hit.id)
distance.append(hit.distance)
answer.append(hit.entity.get('answer'))
original_question.append(hit.entity.get('original_question'))
overall_id.append(ids)
overall_distance.append(distance)
overall_answer.append(answer)
overall_original_question.append(original_question)
return{
'id' verall_id, verall_id,
'distance'verall_distance,
'answer'verall_answer,
'original_question'verall_original_question
}
question_dataset=question_dataset.map(search,batched=True,batch_size=1)
forxinquestion_dataset:
print()
print('Question:')
print(x['question'])
print('Answer,Distance,OriginalQuestion')
forxinzip(x['answer'],x['distance'],x['original_question']):
print(x)
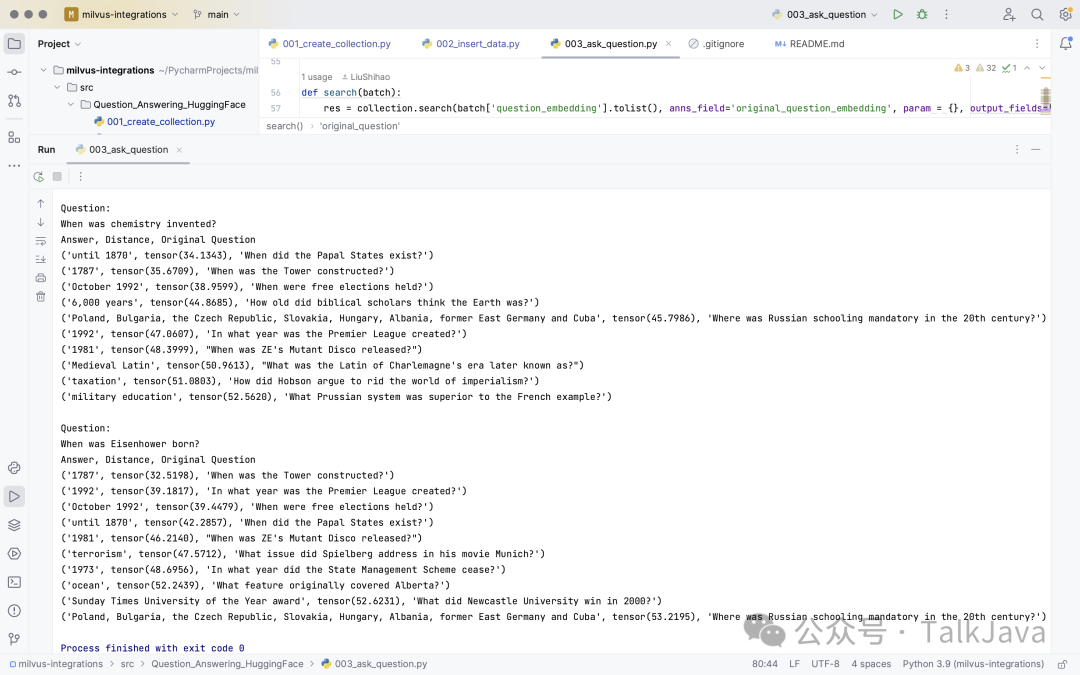
Question:When was chemistry invented?Answer, Distance, Original Question('until 1870', tensor(34.1343), 'When did the Papal States exist?')('1787', tensor(35.6709), 'When was the Tower constructed?')('October 1992', tensor(38.9599), 'When were free elections held?')('6,000 years', tensor(44.8685), 'How old did biblical scholars think the Earth was?')('Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba', tensor(45.7986), 'Where was Russian schooling mandatory in the 20th century?')('1992', tensor(47.0607), 'In what year was the Premier League created?')('1981', tensor(48.3999), "When was ZE's Mutant Disco released?")('Medieval Latin', tensor(50.9613), "What was the Latin of Charlemagne's era later known as?")('taxation', tensor(51.0803), 'How did Hobson argue to rid the world of imperialism?')('military education', tensor(52.5620), 'What Prussian system was superior to the French example?')
Question:When was Eisenhower born?Answer, Distance, Original Question('1787', tensor(32.5198), 'When was the Tower constructed?')('1992', tensor(39.1817), 'In what year was the Premier League created?')('October 1992', tensor(39.4479), 'When were free elections held?')('until 1870', tensor(42.2857), 'When did the Papal States exist?')('1981', tensor(46.2140), "When was ZE's Mutant Disco released?")('terrorism', tensor(47.5712), 'What issue did Spielberg address in his movie Munich?')('1973', tensor(48.6956), 'In what year did the State Management Scheme cease?')('ocean', tensor(52.2439), 'What feature originally covered Alberta?')('Sunday Times University of the Year award', tensor(52.6231), 'What did Newcastle University win in 2000?')('Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba', tensor(53.2195), 'Where was Russian schooling mandatory in the 20th century?')
这样就实现了一个简单的问答系统。
除了与Huggingface的模型整合,你可以与OpenAI的接口整合,以及其他模型从而实现图像搜索、音频搜素等功能。
|










