MCP的关键两步:模型如何智能选择工具和工具执行与结果反馈机制。在选择工具时,模型是通过 prompt 来确定当前有哪些工具。我们通过将工具的具体使用描述以文本的形式传递给模型,供模型了解有哪些工具以及结合实时情况进行选择,这一步会消耗大量token,所以我们选择了本地部署的小尺寸的Qwen3-0.6b,不仅节约了token,还加速了工具选择。承接上一步,我们把 system prompt(指令与工具调用描述)和用户消息一起发送给模型,然后接收模型的回复。当模型分析用户请求后,它会决定是否需要调用工具:无需工具时:模型直接生成自然语言回复;需要工具时:模型输出结构化 JSON 格式的工具调用请求。在这一步,为了输出效果的稳定性,我们选择了Qwen3-235b-a22b,并且经过测试,Qwen3-235b-a22b提供了与DeepSeek-R1相同的能力。Qwen3-0.6b+Qwen3-235b-a22b的使用,不仅保证了结果的稳定性,加速了tool选择,同时在有大量描述的tool的场景下大大节省了token数,真正做到了“多快好省”。
MCP 由三个核心组件构成:Host、Client 和 Server。 MCP Hosts:如 Claude Desktop、IDE 或 AI 工具,希望通过 MCP 访问数据的程序 MCP Clients:维护与服务器一对一连接的协议客户端 MCP Servers:轻量级程序,通过标准的 Model Context Protocol 提供特定能力 本地数据源:MCP 服务器可安全访问的计算机文件、数据库和服务 远程服务:MCP 服务器可连接的互联网上的外部系统(如通过 APIs)
让我们通过一个实际场景来理解这些组件如何协同工作。假设你正在使用 Claude Desktop (Host) 询问:“我桌面上有哪些文档?” MCP Hosts:Claude Desktop 作为 Host,负责接收你的提问并与 Claude 模型交互。 MCP Clients:当 Claude 模型决定需要访问你的文件系统时,Host 中内置的 MCP Client 会被激活。这个 Client 负责与适当的 MCP Server 建立连接。 MCP Servers:在这个例子中,文件系统 MCP Server 会被调用。它负责执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
完整流程如下:你的问题 → Claude Desktop(Host) → Claude 模型 → 需要文件信息 → MCP Client 连接 → 文件系统 MCP Server → 执行操作 → 返回结果 → Claude 生成回答 → 显示在 Claude Desktop 上。 这种架构设计使得 Claude 可以在不同场景下灵活调用各种工具和数据源,而开发者只需专注于开发对应的 MCP Server,无需关心 Host 和 Client 的实现细节。 1.2.1 模型如何智能选择工具?关于在什么时候确定使用哪些工具的这个问题,Anthropic 为我们提供了详细的解释[1]。 当用户提出一个问题时: 客户端(Claude Desktop / Cursor)将你的问题发送给 Claude。 Claude 分析可用的工具,并决定使用哪一个(或多个)。 客户端通过 MCP Server 执行所选的工具。 工具的执行结果被送回给 Claude。 Claude 结合执行结果构造最终的 prompt 并生成自然语言的回应。 回应最终展示给用户。
这个调用过程可以分为两个步骤: 下图是一个简单可视化: 
这里以 MCPclient example[2]为例,可以发现模型是通过 prompt 来确定当前有哪些工具。我们通过将工具的具体使用描述以文本的形式传递给模型,供模型了解有哪些工具以及结合实时情况进行选择。参考代码中的注释: ...# 省略了无关的代码asyncdefstart(self): # 初始化所有的 mcp server forserverinself.servers: awaitserver.initialize()
# 获取所有的 tools 命名为 all_tools all_tools = [] forserverinself.servers: tools =awaitserver.list_tools() all_tools.extend(tools)
# 将所有的 tools 的功能描述格式化成字符串供 LLM 使用 # tool.format_for_llm() 我放到了这段代码最后,方便阅读。 tools_description ="\n".join( [tool.format_for_llm()fortoolinall_tools] )
# 这里就不简化了,以供参考,实际上就是基于 prompt 和当前所有工具的信息 # 询问 LLM(Claude) 应该使用哪些工具。 system_message = ( "You are a helpful assistant with access to these tools:\n\n" f"{tools_description}\n" "Choose the appropriate tool based on the user's question. " "If no tool is needed, reply directly.\n\n" "IMPORTANT: When you need to use a tool, you must ONLY respond with " "the exact JSON object format below, nothing else:\n" "{\n" ' "tool": "tool-name",\n' ' "arguments": {\n' ' "argument-name": "value"\n' " }\n" "}\n\n" "After receiving a tool's response:\n" "1. Transform the raw data into a natural, conversational response\n" "2. Keep responses concise but informative\n" "3. Focus on the most relevant information\n" "4. Use appropriate context from the user's question\n" "5. Avoid simply repeating the raw data\n\n" " lease use only the tools that are explicitly defined above." lease use only the tools that are explicitly defined above." ) messages = [{"role":"system","content": system_message}]
whileTrue: # Final... 假设这里已经处理了用户消息输入. messages.append({"role":"user","content": user_input})
# 将 system_message 和用户消息输入一起发送给 LLM llm_response = self.llm_client.get_response(messages)
...# 后面和确定使用哪些工具无关
classTool: """Represents a tool with its properties and formatting."""
def__init__( self, name:str, description:str, input_schema:dict[str,Any] ) ->None: self.name:str= name self.description:str= description self.input_schema:dict[str,Any] = input_schema
# 把工具的名字 / 工具的用途(description)和工具所需要的参数(args_desc)转化为文本 defformat_for_llm(self) ->str: """Format tool information for LLM.
Returns: A formatted string describing the tool. """ args_desc = [] if"properties"inself.input_schema: forparam_name, param_infoinself.input_schema["properties"].items(): arg_desc = ( f"-{param_name}:{param_info.get('description','No description')}" ) ifparam_nameinself.input_schema.get("required", []): arg_desc +=" (required)" args_desc.append(arg_desc)
returnf"""Tool:{self.name}Description:{self.description}Arguments:{chr(10).join(args_desc)}"""
那 tool 的描述和代码中的input_schema是从哪里来的呢?通过进一步分析 MCP 的 Python SDK 源代码可以发现:大部分情况下,当使用装饰器@mcp.tool()来装饰函数时,对应的name和description等其实直接源自用户定义函数的函数名以及函数的docstring等。 @classmethoddeffrom_function( cls, fn:Callable, name:str|None=None, description:str|None=None, context_kwarg:str|None=None,) ->"Tool": """Create a Tool from a function.""" func_name = nameorfn.__name__# 获取函数名
iffunc_name =="<lambda>": raiseValueError("You must provide a name for lambda functions")
func_doc = descriptionorfn.__doc__ or""# 获取函数 docstring is_async = inspect.iscoroutinefunction(fn)
模型是通过prompt engineering,即提供所有工具的结构化描述和few-shot 的example来确定该使用哪些工具。 1.2.2 工具执行与结果反馈机制承接上一步,我们把 system prompt(指令与工具调用描述)和用户消息一起发送给模型,然后接收模型的回复。当模型分析用户请求后,它会决定是否需要调用工具: 如果回复中包含结构化 JSON 格式的工具调用请求,则客户端会根据这个 json 代码执行对应的工具。具体的实现逻辑都在process_llm_response中。 asyncdefstart(self): ...# 上面已经介绍过了,模型如何选择工具
whileTrue: # 假设这里已经处理了用户消息输入. messages.append({"role":"user","content": user_input})
# 获取 LLM 的输出 llm_response = self.llm_client.get_response(messages)
# 处理 LLM 的输出(如果有 tool call 则执行对应的工具) result =awaitself.process_llm_response(llm_response)
# 如果 result 与 llm_response 不同,说明执行了 tool call (有额外信息了) # 则将 tool call 的结果重新发送给 LLM 进行处理。 ifresult != llm_response: messages.append({"role":"assistant","content": llm_response}) messages.append({"role":"system","content": result})
final_response = self.llm_client.get_response(messages) logging.info("\nFinal response: %s", final_response) messages.append( {"role":"assistant","content": final_response} ) # 否则代表没有执行 tool call,则直接将 LLM 的输出返回给用户。 else: messages.append({"role":"assistant","content": llm_response})
如果模型执行了 tool call,则工具执行的结果 result 会和 system prompt 和用户消息一起重新发送给模型,请求模型生成最终回复。如果 tool call 的 json 代码存在问题或者模型产生了幻觉,我们会跳过掉无效的调用请求。 所以,工具文档至关重要,模型通过工具描述文本来理解和选择工具,因此精心编写工具的名称、docstring 和参数说明至关重要。由于 MCP 的选择是基于 prompt 的,所以任何模型其实都适配 MCP,只要你能提供对应的工具描述。 对于用户来说,我们并不关心 MCP 是如何实现的,通常我们只考虑如何更简单的使用。 具体的使用方式参考官方文档:For Claude Desktop Users[3]。这里不再赘述,配置成功后可以在 Claude 中测试:Can you write a poem and save it to my desktop?Claude 会请求你的权限后在本地新建一个文件。 并且官方也提供了非常多现成的 MCP Servers,你只需要选择你希望接入的工具,然后接入即可。 Awesome MCP Servers[4] MCP Servers Website[5] Official MCP Servers[6]
比如官方介绍的filesystem工具,它允许 Claude 读取和写入文件,就像在本地文件系统中一样。 MCP (Model Context Protocol) 代表了 AI 与外部工具和数据交互的标准建立。通过本文,我们可以了解到: MCP 的本质:它是一个统一的协议标准,使 AI 模型能够以一致的方式连接各种数据源和工具,类似于 AI 世界的“USB-C”接口。 MCP 的价值:它解决了传统 function call 的平台依赖问题,提供了更统一、开放、安全、灵活的工具调用机制,让用户和开发者都能从中受益。 使用与开发:对于普通用户,MCP 提供了丰富的现成工具,用户可以在不了解任何技术细节的情况下使用;对于开发者,MCP 提供了清晰的架构和 SDK,使工具开发变得相对简单。
4 月 29 日凌晨,在一众预告和期待中,阿里巴巴终于发布并开源了新一代通义千问模型 Qwen3。 Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。其中参数量仅为 DeepSeek-R1 的 1/3,成本大幅下降,性能全面超越 R1、OpenAI-o1 等全球顶尖模型。 Qwen3 还是国内首个“混合推理模型”,“快思考”与“慢思考”集成进同一个模型,对简单需求可低算力“秒回”答案,对复杂问题可多步骤“深度思考”,大大节省算力消耗。 Qwen3 在推理、指令遵循、工具调用、多语言能力等方面均大幅增强。在官方的测评中,Qwen3 创下所有国产模型及全球开源模型的性能新高:在奥数水平的 AIME25 测评中,Qwen3 斩获 81.5 分,刷新开源纪录;在考察代码能力的 LiveCodeBench 评测中,Qwen3 突破 70 分大关,表现甚至超过 Grok3;在评估模型人类偏好对齐的 ArenaHard 测评中,Qwen3 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。 
性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署 Qwen3 满血版,显存占用仅为性能相近模型的三分之一。对于部署,官方建议使用 SGLang 和 vLLM 等框架。对于本地使用,官方强烈推荐使用 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。 此外,Qwen3 还提供和开源了丰富的模型版本,包含 2 款 30B、235B 的 MoE 模型,以及 0.6B、1.7B、4B、8B、14B、32B 等 6 款稠密模型,每款模型均斩获同尺寸开源模型 SOTA(最佳性能):Qwen3 的 30B 参数 MoE 模型实现了 10 倍以上的模型性能杠杆提升,仅激活 3B 就能媲美上代 Qwen2.5-32B 模型性能;Qwen3 的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如 32B 版本的 Qwen3 模型可跨级超越 Qwen2.5-72B 性能。 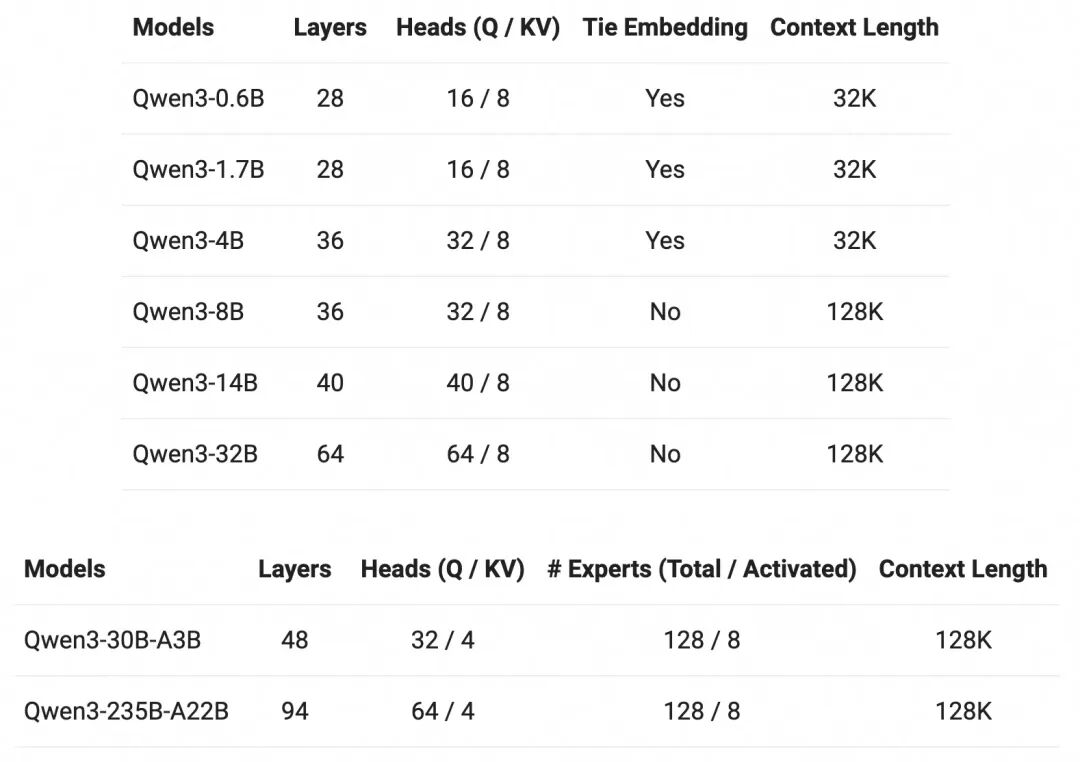
2.2.1 混合思维模式所有 Qwen3 模型都是混合推理模型,支持两种模式: 用户使用 API 可按需设置“思考预算”(即预期最大深度思考的 tokens 数量),进行不同程度的思考,灵活满足 AI 应用和不同场景对性能和成本的多样需求。比如,4B 模型是手机端的绝佳尺寸;8B 可在电脑和汽车端侧丝滑部署应用;32B 最受企业大规模部署欢迎,有条件的开发者也可轻松上手。 
该设计使 Qwen3 展现出与推理预算成正比的、可扩展且平滑的性能提升。用户能够更轻松地根据不同任务配置推理预算,在成本效率与推理质量之间实现更优的平衡。 
2.2.2 增强对 Agent 支持Qwen3 为即将到来的智能体 Agent 和大模型应用爆发提供了更好的支持。团队优化了 Qwen3 模型的编码和 Agent 能力,并增强了对 MCP 的支持。 在评估模型 Agent 能力的 BFCL 评测中,Qwen3 创下 70.8 的新高,超越 Gemini2.5-Pro、OpenAI-o1 等顶尖模型,将大幅降低 Agent 调用工具的门槛。同时,Qwen3 原生支持 MCP 协议,并具备强大的工具调用(function calling)能力,结合封装了工具调用模板和工具调用解析器的 Qwen-Agent 框架,将大大降低编码复杂性,实现高效的手机及电脑 Agent 操作等任务。 2.2.3 多语言支持Qwen3 模型支持 119 种语言和方言,极大地扩展了其在全球应用中的可用性。这种广泛的多语言功能使世界各地的用户能够在不同的语言和文化背景下充分发挥 Qwen3 的潜力。 语系和覆盖范围: 语系 | 语言与方言 | 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、达里语、南非荷兰语、马其顿语僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 | 汉藏语系 | 中文(简体、繁体、粤语)、缅甸语 | 亚非语系 | 阿拉伯语(标准语、纳吉迪语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 | 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) | 达罗毗荼人 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 | 突厥语 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 | 侗族 | 泰语、老挝语 | 乌拉尔语 | 芬兰语、爱沙尼亚语、匈牙利语 | 南亚语系 | 越南语、高棉语 | 其他 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
2.3.1 预训练在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5 是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用了几乎两倍的数据量,约 36 万亿个 token,涵盖了 119 种语言和方言。 为了构建如此大规模的数据集,Qwen3 不仅从网页收集数据,还从类似 PDF 的文档中提取内容。团队使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 提升提取内容的质量。为了增加数学和代码数据的比例,团队还利用 Qwen2.5-Math 和 Qwen2.5-Coder 生成了合成数据,包括教科书、问答对以及代码片段等。 预训练过程分为三个阶段。 在第一阶段(S1),模型在超过 30 万亿个 token 上进行预训练,使用的上下文长度为 4K tokens。这一阶段使模型掌握了基础语言能力和通用知识。 在第二阶段(S2),团队提升了数据集的质量,增加了 STEM、编程和推理等知识密集型数据的比例,并在额外的 5 万亿个 token 上进行了进一步预训练。 在最后一个阶段,使用高质量的长上下文数据,将模型的上下文长度扩展到了 32K tokens,以确保模型能够有效处理更长的输入。

由于模型架构的进步、训练数据量的增加以及更高效的训练方法,Qwen3 的稠密基础模型整体性能已经达到了参数量更大的 Qwen2.5 基础模型的水平。 例如,Qwen3-1.7B/4B/8B/14B/32B-Base 的性能分别相当于 Qwen2.5-3B/7B/14B/32B/72B-Base。值得注意的是,在 STEM、编程和推理等领域,Qwen3 的稠密基础模型甚至超越了更大规模的 Qwen2.5 模型。对于 Qwen3-MoE 基础模型,它们仅使用 10% 的激活参数,就能达到与 Qwen2.5 稠密基础模型相近的性能,从而在训练和推理成本上实现了显著节省。 2.3.2 后训练
为了开发能够兼顾逐步推理与快速响应的混合模型,团队设计并实现了一个四阶段的训练流程,该流程包括:(1) 长链式思维(CoT)冷启动,(2) 基于推理的强化学习(RL),(3) 思维模式融合,以及 (4) 通用强化学习。 第一阶段,团队使用多样化的长链式思维数据对模型进行微调,涵盖数学、编程、逻辑推理、STEM 问题等不同任务和领域。此过程旨在赋予模型基本的推理能力。 第二阶段则专注于扩大强化学习的算力规模,利用基于规则的奖励机制,提升模型的探索与利用能力。 第三阶段,通过在长链式思维数据与常规指令微调数据的组合上进行微调,将非思考型能力融入思考型模型。这些数据由第二阶段增强后的思考模型生成,从而实现推理与快速响应能力的自然融合。 第四阶段,团队在 20 多个通用领域任务上应用强化学习,进一步增强模型的通用能力并纠正不良行为。这些任务包括指令跟随、格式遵循、Agent 能力等。
为了验证Qwen3的效果,我们选用了0.6b的参数量,结果十分理想,证明未来在端侧也会有不错的表现。 3.1.1 资源准备3.1.2 创建实例,选择镜像和GPU驱动安装
3.2.1 升级python版本本文采用ollama方式部署Qwen3,需升级python版本(alinux3环境默认3.6),通过yum升级至python3.8,并通过update-alternatives切换环境默认的python解释器版本: yuminstall-ypython3.8update-alternatives--configpython3 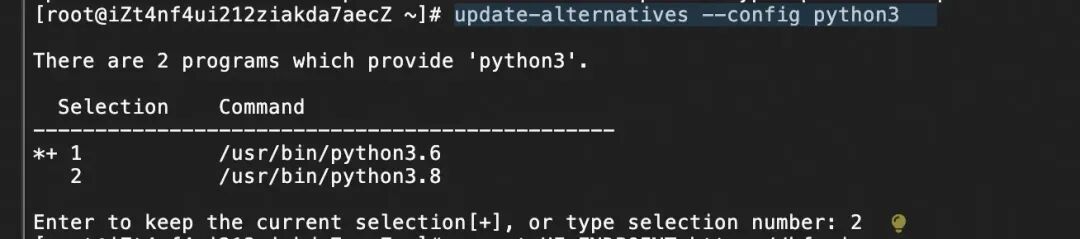
3.2.2 安装ollama这里采用modelscope提供的ollama的Linux版本安装Ollama-Linux安装[7] #使用命令行前,请确保已经通过pipinstallmodelscope安装ModelScope。modelscopedownload--model=modelscope/ollama-linux--local_dir./ollama-linux--revisionv0.6.7 #运行ollama安装脚本cdollama-linuxsudochmod777./ollama-modelscope-install.sh./ollama-modelscope-install.sh 3.3.1 启动Ollama服务3.3.2 修改配置文件systemctl edit ollama.service
[Service]Environment="OLLAMA_HOST=0.0.0.0"Environment="OLLAMA_ORIGINS=*"
3.3.3 启动Ollamasystemctldaemon-reloadsystemctlrestartollamasystemctlstatusollamaollamarunqwen3:0.6b 
在这一章中,我们将会实现一个用于网络搜索的服务器。 Python 3.10+ 环境 Python MCP SDK 1.2.0+
# 安装uvcurl -LsSf https://astral.sh/uv/install.sh | sh
# 为我们的项目创建一个新 directoryuv init mcpcdmcp
# 设置 Python 3.10+ 环境echo"3.11"> .python-version
# 创建 virtual environment 并激活它uv venvsource.venv/bin/activate
# 安装 dependenciesuv add"mcp[cli]"httpx
# 创建我们的 server filetouchweb_search.py
uv是一个用 Rust 编写的超快速 (100x) Python 包管理器和环境管理工具,由 Astral 开发。定位为 pip 和 venv 的替代品,专注于速度、简单性和现代 Python 工作流。
我们来创建一个叫web_search.py文件,来实现我们的服务。MCP 为我们提供了2个对象:mcp.server.FastMCP和mcp.server.Server,mcp.server.FastMCP是更高层的封装,我们这里就来使用它。 importhttpxfrommcp.serverimportFastMCP
# # 初始化 FastMCP 服务器app = FastMCP('web-search')
实现执行的方法非常简单,MCP 为我们提供了一个@mcp.tool()我们只需要将实现函数用这个装饰器装饰即可。函数名称将作为工具名称,参数将作为工具参数,并通过注释来描述工具与参数,以及返回值。 这里我们直接使用智谱的接口,它这个接口不仅能帮我们搜索到相关的结果链接,并帮我们生成了对应链接中文章总结后的内容。 官方文档:
https://bigmodel.cn/dev/api/search-tool/web-search-pro API Key 生成地址:
https://bigmodel.cn/usercenter/proj-mgmt/apikeys
@app.tool()asyncdefweb_search(query:str) ->str: """ 搜索互联网内容
Args: query: 要搜索内容
Returns: 搜索结果的总结 """
asyncwithhttpx.AsyncClient()asclient: response =awaitclient.post( 'https://open.bigmodel.cn/api/paas/v4/tools', headers={'Authorization':'换成你自己的API KEY'}, json={ 'tool':'web-search-pro', 'messages': [ {'role':'user','content': query} ], 'stream':False } )
res_data = [] forchoiceinresponse.json()['choices']: formessageinchoice['message']['tool_calls']: search_results = message.get('search_result') ifnot search_results: continue forresultinsearch_results: res_data.append(result['content'])
return'\n\n\n'.join(res_data)
最后,我们来添加运行服务器的代码。 if__name__=="__main__":app.run(transport='stdio') 此时,我们就完成了 MCP 服务端的编写。下面,我们来使用官方提供的Inspector可视化工具来调试我们的服务器。 我们可以通过两种方法来运行Inspector: 请先确保已经安装了 node 环境。
通过 npx: npx-y@modelcontextprotocol/inspector<command><arg1><arg2> 我们的这个代码运行命令为: npx-y@modelcontextprotocol/inspectoruvrunweb_search.py 通过 mcp dev 来运行: 我们的这个代码运行命令为: 当出现如下提示则代表运行成功。 
然后,我们打开这个地址,点击左侧的Connect按钮,即可连接我们刚写的服务。然后我们切换到Tools栏中,点击List Tools按钮即可看到我们刚写的工具,我们就可以开始进行调试。 
importasyncio
frommcp.client.stdioimportstdio_clientfrommcpimportClientSession, StdioServerParameters
# 为 stdio 连接创建服务器参数server_params = StdioServerParameters( # 服务器执行的命令,这里我们使用 uv 来运行 web_search.py command='uv', # 运行的参数 args=['run','web_search.py'], # 环境变量,默认为 None,表示使用当前环境变量 # env=None)
asyncdefmain(): # 创建 stdio 客户端 asyncwithstdio_client(server_params)as(stdio, write): # 创建 ClientSession 对象 asyncwithClientSession(stdio, write)assession: # 初始化 ClientSession awaitsession.initialize()
# 列出可用的工具 response =awaitsession.list_tools() print(response)
# 调用工具 response =awaitsession.call_tool('web_search', {'query':'今天北京天气'}) print(response)
if__name__ =='__main__': asyncio.run(main())

可以看到工具成功调用。 这里的思路是,对于复杂的描述的function call的描述信息,我们使用本地Ollama框架部署的Qwen3-0.6b小尺寸模型,本地部署模型的优势就是可以减少token的开销。对于后面的生成结果的过程,可以使用满血版Qwen3-235b-a22b,确保输出结果的稳健性和准确性。 首先我们来编写我们的MCPClient类。 importjsonimportasyncioimportosfromtypingimportOptionalfromcontextlibimportAsyncExitStack
fromopenaiimportOpenAIfromdotenvimportload_dotenv
frommcpimportClientSession, StdioServerParametersfrommcp.client.stdioimportstdio_client
# 初始化客户端,指向 Ollama 的本地服务client1 = OpenAI( base_url="http://your-ip:11434/v1", # Ollama API 地址 api_key="ollama"# Ollama 默认无需真实 API Key,填任意值即可)#初始化客户端,指向通过api调用的Qwen3-235b-a22bclient2 = OpenAI( # 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx", #api_key=os.getenv("api_key"), api_key='your-api-key', base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)
classMCPClient: def__init__(self): self.session:Optional[ClientSession] =None self.exit_stack = AsyncExitStack() self.client1 = client1 self.client2 = client2
然后我们添加connect_to_server方法来初始化我们的 MCP 服务器的 session。 asyncdefconnect_to_server(self): server_params = StdioServerParameters( command='uv', args=['run','web_search.py'], env=None )
stdio_transport =awaitself.exit_stack.enter_async_context( stdio_client(server_params)) stdio, write = stdio_transport self.session =awaitself.exit_stack.enter_async_context( ClientSession(stdio, write))
awaitself.session.initialize()
然后我们再实现一个用于调用 MCP 服务器的方法来处理和Qwen3之间的交互。
asyncdefconnect_to_server(self): server_params= StdioServerParameters( command='uv', args=['run','web_search.py'], env=None ) stdio_transport =awaitself.exit_stack.enter_async_context( stdio_client(server_params)) stdio, write = stdio_transport self.session =awaitself.exit_stack.enter_async_context( ClientSession(stdio, write)) awaitself.session.initialize()
接着,我们来实现循环提问和最后退出后关闭session的操作。 asyncdefchat_loop(self): whileTrue: try: query =input("\nQuery: ").strip()
ifquery.lower() =='quit': break
response =awaitself.process_query(query) print("\n"+ response)
exceptExceptionase: importtraceback traceback.print_exc()
asyncdefcleanup(self): """Clean up resources""" awaitself.exit_stack.aclose()
最后,我们来完成运行这个客户端相关的代码 asyncdefmain(): client = MCPClient() try: awaitclient.connect_to_server() awaitclient.chat_loop() finally: awaitclient.cleanup()
if__name__ =="__main__": import sys
asyncio.run(main())
这是一个最精简的代码,里面没有实现记录上下文消息等功能,只是为了用最简单的代码来了解如何通过大语言模型来调动 MCP 服务器。这里只演示了如何连接单服务器,如果想连接多个 MCP 服务器,无非就是循环一下connect_to_server中的代码,可以将他们封装成一个类,然后将所有的 MCP 服务器中的工具循环遍历生成一个大的available_tools,然后再通过大语言模型的返回结果进行调用即可。 可以参考官方案例:https://github.com/modelcontextprotocol/python-sdk/blob/main/examples/clients/simple-chatbot/mcp_simple_chatbot/main.py


这里我们只使用了一个调用网页总结API的工具,并且仅仅简单描述了一下功能,共消耗182tokens,可以想象多个描述复杂的tool将会消耗多少token。 在本篇文章中,我们详细介绍了如何在本地部署Qwen-3模型,并通过MCP(Model Control Protocol),在需要花费较多token的tool list环节使用节约成本的本地部署Qwen3-0.6b模型进行调用,在输出结果的环节使用Qwen3-235b-a22b调用。尽管我们在混合部署Qwen-3并通过MCP调用方面取得了一些进展,但仍存在一些不足之处: 1.资源消耗较大: 2.调试难度较高: 3.扩展性有限: 未来我们可以针对这些不足做进一步完善,比如可以引入更多的日志记录和监控工具,帮助快速诊断和修复故障;对成本节约进行进一步的量化;尝试使用不同Qwen3的请求参数值。随着技术的不断进步和完善,相信在未来能够克服现有挑战,为用户提供更加高效、可靠且安全的服务体验。 | 









