相比于 AI 大模型内置的静态预训练数据,知识库中的内容能够实时更新,确保 LLM 可以访问到最新的信息,避免因信息过时或遗漏而产生的问题。
知识库与文档
开发者可以通过此方式确保 LLM 不仅仅依赖于训练数据中的知识,还能够处理来自实时文档和数据库的动态数据,从而提高回答的准确性和相关性。
https://docs.dify.ai/zh-hans/guides/knowledge-base/readme
在 Dify 中,知识库(Knowledge)是一系列文档(Documents)的集合,一个文档内可能包含多组内容分段(Chunks),知识库可以被整体集成至一个应用中作为检索上下文使用。文档可以由开发者或运营人员上传,或由其它数据源同步。
知识库管理
创建知识库并上传文档大致分为以下步骤:
- 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
- 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
- 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
Dify默认支持的格式为:txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv
Unstructured ETL支持的格式为:txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub
知识库元数据
https://docs.dify.ai/zh-hans/guides/knowledge-base/metadata
元数据是用于描述其他数据的信息。简单来说,它是”关于数据的数据”。它就像一本书的目录或标签,可以为你介绍数据的内容、来源和用途。 通过提供数据的上下文,元数据能帮助你在知识库内快速查找和管理数据。
在知识库中,元数据字段分为两类:内置元数据(Built-in)和自定义元数据。
| | |
|---|
| | |
| | |
| | |
| | |
| | 添加元数据字段后,字段会储存在知识库的元数据列表中/需要手动设置,才能将该字段应用于具体文档。 |
用户可以根据元数据标签快速筛选和查找相关信息,节省时间并提高工作效率。数据帮助企业或组织有效分类和存储数据,提高数据的管理和检索能力,增强数据的可用性和一致性。
知识库索引设置
https://docs.dify.ai/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
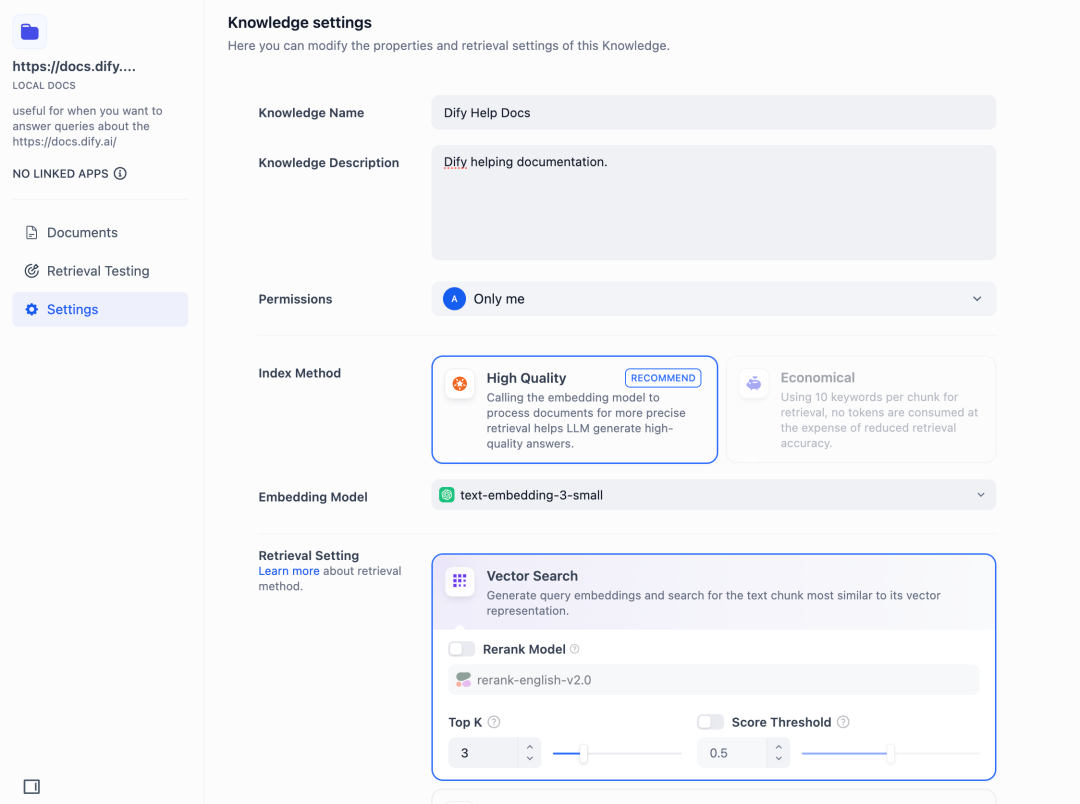
高质量
在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。
将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。关于各个设置的详细说明,请继续阅读检索设置。
选择高质量模式后,当前知识库的索引方式无法在后续降级为 “经济”索引模式。如需切换,建议重新创建知识库并重选索引方式。
经济
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。
选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 “高质量”索引方式。
向量检索设置
Rerank 模型:默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
Score 阈值:用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
外部知识库
https://docs.dify.ai/zh-hans/guides/knowledge-base/connect-external-knowledge-base
对于内容检索有着更高要求的进阶开发者而言,Dify 平台内置的知识库功能和文本检索和召回机制存在限制,无法轻易变更文本召回结果。
连接外部知识库功能可以将 Dify 平台与外部知识库建立连接。通过 API 服务,AI 应用能够获取更多信息来源。这意味着:
- Dify 平台能够直接获取托管在云服务提供商知识库内的文本内容,开发者无需将内容重复搬运至 Dify 中的知识库;
- Dify 平台能够直接获取自建知识库内经算法处理后的文本内容,开发者仅需关注自建知识库的信息检索机制,并不断优化与提升信息召回的准确度。
请求接受以下 JSON 格式的数据。
POST <your-endpoint>/retrieval HTTP/1.1
-- 请求头
Content-Type: application/json
Authorization: Bearer your-api-key
-- 数据
{
"knowledge_id":"your-knowledge-id",
"query":"你的问题",
"retrieval_setting":{
"top_k": 2,
"score_threshold": 0.5
}
}










