在AI应用领域,各种新技术新名词层出不穷,但最实用的技术莫过于RAG了。
相信稍微接触过AI的同学都不会陌生,但要想用好RAG,还是有一定门槛。
今天咱们就来聊一聊RAG。

RAG是什么?
检索增强生成
Retrieval-Augmented Generation
一般用户在使用大模型的时候,其实只需要使用自然语言问问题,大模型就会返回相应的答案。
所以只要掌握好提示词工程,大多数场景就已经可以让大模型乖乖给你干活了。想了解提示词的同学,可以去看上一篇文章。
你真的会写提示词吗?高质量提示词指南来了!
但是大模型能回答的仅限于公域知识。如果你有一个私域文档,希望大模型根据文档的内容回答问题。要怎么搞?
也很简单,只要把文档丢给大模型让他参考就可以了。
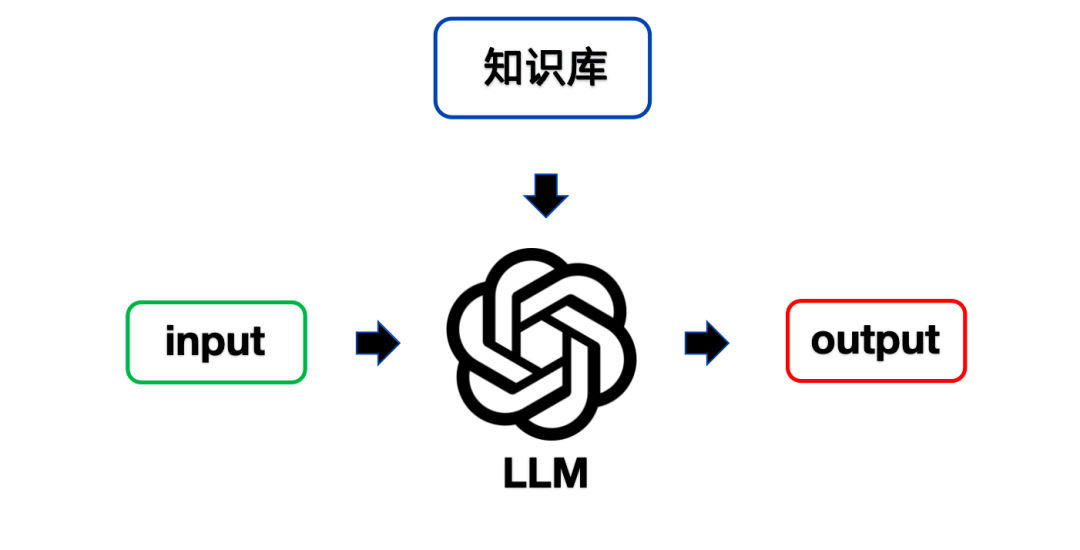
比如,你有一个文档《公司考勤管理制度》,只需要把文档的内容全部复制粘贴到提示词中,并要求大模型参考知识回答问题即可。
但是,如果文档非常长,比如是一本书,没办法一次性丢给大模型参考,该怎么办?
这个时候就需要用到我们的RAG(检索增强生成)技术了。
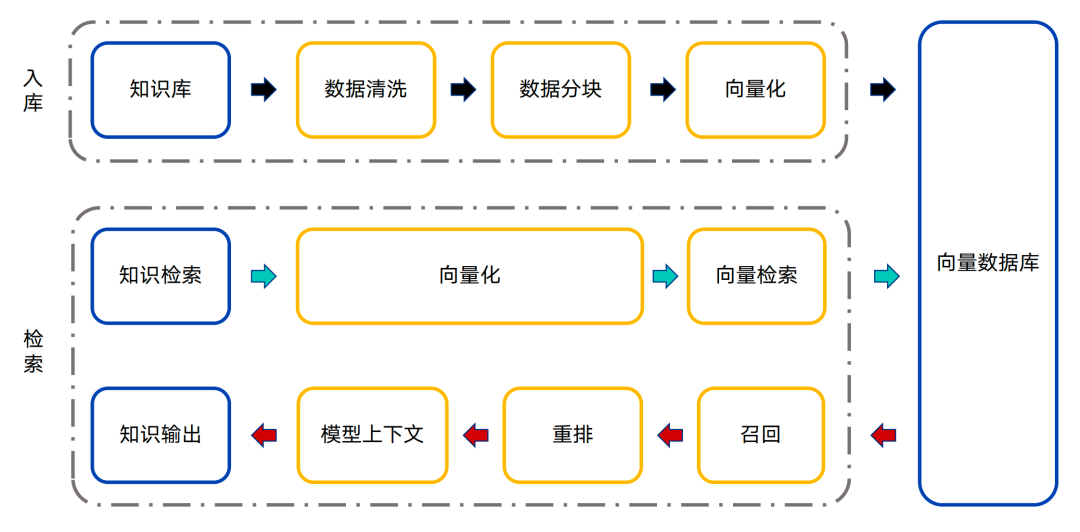
核心是把知识进行模块化存储,使用时按需召回最匹配的知识并作为上下文提供给大模型。
RAG的好处
提高准确性
通过引用外部知识库,RAG 能够弥补LLM 在特定领域知识或最新信息方面的不足,从而提高生成响应的准确性。
更新鲜的信息
RAG 能够访问实时更新的外部数据源,使得模型生成的响应更加及时和符合最新情况。
降低成本
与重新训练LLM相比,RAG 是一种更具成本效益的方式来增强LLM 的能力,因为它无需对模型进行大规模的重新训练。
增强可解释性
RAG可以提供生成响应所依据的外部来源,增强了响应的可解释性和可信度。
消除幻觉
基于确定性的知识能够让大模型的回答更加稳定,大幅度降低胡编乱造的可能性。
RAG的技术原理
RAG技术入门非常简单,现在市面上很多的AI开发框架和智能体开发平台都内置了知识库能力,轻轻松松就可以搞出一个企业知识库,并且知识库的检索也能达到及格水平。
但AI技术的特点往往就是上手容易但深入困难,想要进一步优化你的私域知识库,就得适当了解RAG的技术原理,根据自己的实际情况选择更好的技术路径。
RAG的技术路径有很多种,但总体来说,可以划分为“知识入库”和“知识检索”两个大的板块。
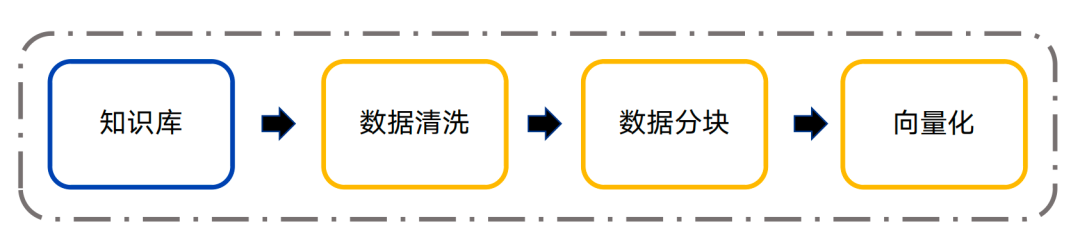
知识入库
知识入库质量的好坏,决定了知识检索的效果。
| |
|---|
| 去除无效数据,例如:外部链接、重复数据、特殊符号、无效信息等。 |
| 针对不同的文档类型进行分块处理。比如按段落分块、按固定长度分块等。 |
| |
这里每一个步骤都足够复杂,咱们后面的系列文章会逐步进行讲解。
知识检索
从向量数据库中查找对应的知识并作为上下文输入到大模型中。
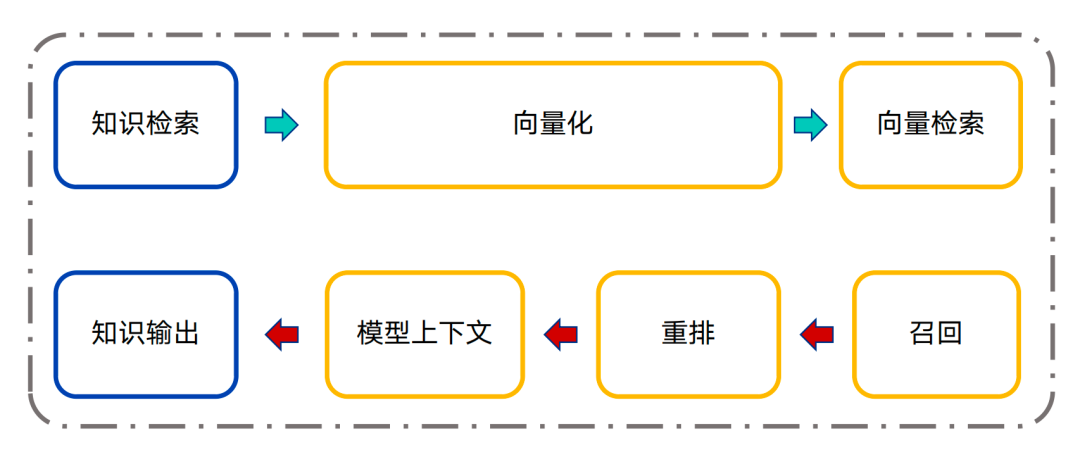
| |
|---|
| 把要检索的内容转化成向量,通过全文检索、稀疏向量检索、稠密向量检索等方式获得最相关的TopK个结果。 |
| 通过对向量检索中召回的TopK歌结果进行二次精排和加工,最终找出最符合的几个结果。 |
举个例子
现在有一个私域知识库文件"公司考勤管理制度.pdf"
<html>
<body>
<div>
XXX公司考勤管理制度
# 第一条 目的
为规范员工考勤管理,维护正常工作秩序,保障企业和员工的合法权益,根据《中华人民共和国劳动法》及相关法律法规,结合公司实际情况,制定本制度。
# 第二条 适用范围
本制度适用于公司全体正式员工、试用期员工及兼职员工。
# 第三条 标准工作时间
公司实行标准工时制,工作日为周一至周五,每日工作时间为:
上午 09:00-12:00
下午 13:00-18:00(含1小时午休)。
特殊岗位或因工作需要调整工作时间的,需经人力资源部审批后执行。
# 第四条 考勤方式
员工需通过 指纹打卡/人脸识别/企业微信签到 等方式记录考勤,每日上下班各打卡一次。
因公外出或出差需提前提交<ahref="http://xxx.erp.cn">《外出申请单》</a>,经部门负责人审批后备案。
</div>
<div>
...
附件:
<ahref="http://xxx.erp.cn">《外出申请单》</a>
人力资源部
XXXX年XX月XX日
</div>
</body>
</html>
一. 数据清洗
删除文档中多余的链接、无效的文本、链接等。 并且进行结构化的分段。方便后续分块。
清洗后的文档:
XXX公司考勤管理制度
# 第一条 目的
为规范员工...
# 第二条 适用范围
...
# 第三条 标准工作时间
...
# 第四条 考勤方式
员工需通过 指纹打卡/人脸识别/企业微信签到 等方式记录考勤,每日上下班各打卡一次。
因公外出或出差需提前提交《外出申请单》,经部门负责人审批后备案。
...
人力资源部
XXXX年XX月XX日
二. 数据分块
咱们采用根据段落分块,既每个段落作为一个独立的分块。
# block_01
XXX公司考勤管理制度
# block_02
第一条 目的
为规范员工...
# block_03
第二条 适用范围
本制度适用于...
# block_04
第三条 标准工作时间
公司实行标准工时制,工作日为周一至周五,每日工作时间为:
上午 09:00-12:00
下午 13:00-18:00(含1小时午休)。
...
# block_05
...
三. 向量化
使用嵌入模型(Embedding Model)把文档中的每个分块(block)转化成向量,并存储在向量数据库中。
转化后的向量大概长这样:
# block_01
{
context: 'XXX公司考勤管理制度',
vector: [
0.11878310581111173, 0.9694947902934701, 0.16443679307243175,
0.5484226189097237, 0.9839246709011924, 0.5178387104937776,
0.8716926129208069, 0.5616972243831446,
...
]
}
# block_02
...
到这一步,我们的向量数据库中已经存储了完整的文档信息。
四. 向量检索
现在用户问了一个问题:
公司的上班时间是?
首先需要把"公司的上班时间是?"也转化成向量:
{
context: '公司的上班时间是?',
vector: [
0.24878310581111173,0.5694947902934701,0.58943679307243175,
0.2354226189097237,0.4469246709011924,0.3138387104937776,
0.6786926129208069,0.4436972243831446,
...
]
}
然后去向量数据库检索,得到如下结果:
[{
id:"block_01",
context:"XXX公司考勤管理制度",
score:"0.7843"
},{
id:"block_05",
context:"公司考勤方式...",
score:"0.334"
}, {
id:"block_04",
context:"第三条 标准工作时间...",
score:"0.103"
}]
其中score是当前分块与待查询值的距离,值越小,语义上越接近。
五. 重排
其实经过第四步,就已经可以找到我们想要的数据了,但很多时候文档会召回大量非常相似的内容。
向量数据库检索的时候,为了性能会牺牲部分检索的精度,也就意味着可能会召回许多完全不相关的内容,那么这个时候就需要用到重排。
重排简单来说就是优中选优,从之前召回的内容中,选择更加符合要求的TopK个结果。
重排后的结果:
[{
id:"block_04",
context:"第三条,标准工作时间..."
}]
六. 大模型回答
有了知识库的筛选结果,那么只需要把结果返回给大模型,由大模型进行回复即可。
# Data
第三条 标准工作时间
公司实行标准工时制,工作日为周一至周五,每日工作时间为:
上午 09:00-12:00
下午 13:00-18:00(含1小时午休)。
# Source
《XXX公司考勤管理制度》
# Question
公司上班时间是?
# Answer
工作日为周一至周五
上午 09:00-12:00
下午 13:00-18:00
午休1小时。
数据来源于XXX公司考勤管理制度










