|
大家好,我是HxShine。 今天分享微软公司的一篇文章,Title: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models。这篇文章介绍了一种名为LLMLingua的粗到细的提示压缩方法,能够在保持语义完整性的同时,将提示prompt压缩20倍,并且基本不损失性能。 主要分为三个步骤来完成prompt的有效压缩,同时确保基本不损失性能。 - 预算控制(budget controller): 为各种组件(instructions, demonstrations, and questions)分配不同的压缩比,通过预算控制器在高压缩比率下维护整体语义完整性。
- 迭代压缩算法(token-level iterative compression algorithm): 使用基于token的迭代算法,准确捕捉压缩内容之间的关联性,从而更有效地压缩prompt并保留知识。
- 指令调整(instruction tuning): 通过指令调整实现语言模型间的分布对齐,解决小模型和黑盒大模型之间的分布差异。
一、概述 Title: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models URL: https://arxiv.org/abs/2310.05736 CODE:https://github.com/microsoft/LLMLingua Authors: Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu 1 Motivation- 随着COT[1]方法、RAG检索方法技术的出现,prompt越来越长,导致比较费API cost,时间成本、金额成本都比较高。
- Natrual Language本身是冗余的,尤其是口语下,另外ChatGPT实际上能很好的理解某种被压缩的文字[2]。
- LLM本身已经学会了非常多知识,即prompt中更高置信的部分token完全不需要交给LLMs,他也能从上下文中猜测出来。
prompt压缩的一些关键问题:
- 压缩和性能平衡: 我们应该如何去设计一个prompt 压缩算法,从而能够最大化的压缩prompt,同时又不影响LLMs的性能。
- 能否即插即用: 这种被压缩的prompt能直接用在下游任务中吗?
- 为什么压缩prompt对LLM有效,如何证明? 有什么证据能证明Black-box LLMs能理解这种被压缩的prompt?
- 为什么不用GPT-X: 为什么不用GPT-X来做这件事?
2 Methods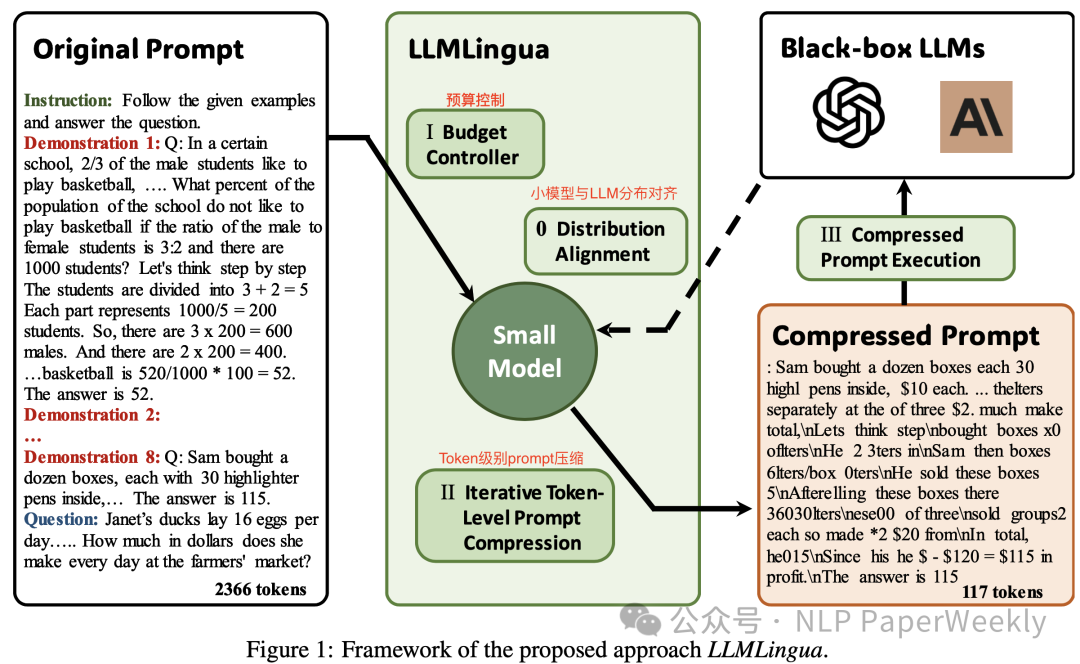 2.1 Budget controller预算控制器(Budget Controller)是LLMLingua方法中的一个重要组件,用于在压缩提示(prompt)时动态分配不同的压缩比率给原始提示中的不同部分。 背景: Prompt中不同成分对于压缩的敏感程度是不同的,例如System prompt,question prompt的敏感度更高,而demonstrations(示例)敏感度低,可以分配更高的压缩比。 目标: 给Instructions(指令)以及question(用户问题)分配较小的压缩比,保留更重要的指令信息。对于demonstrations(示例)可以分配更高的压缩比,去除其冗余信息。 方法: 设置选定的示例集 D:确定一个初始的示例集 D,这个集合将包含经过压缩后的 Demonstrations。
- 根据目标整体压缩率 π 和预定义的指令和问题部分的压缩率 π_ins 和 π_que,计算 Demonstrations 部分的压缩率 π_dems,公式为:其中,分别表示指令和问题部分的令牌长度。
计算每个示例Demonstrations 的困惑度(Perplexity):使用一个小语言模型(如 GPT-2 或 LLaMA)计算原始示例集中每个 Demonstration 的困惑度。 按困惑度对示例Demonstrations 进行排序:将所有 Demonstrations 按照它们的困惑度降序排列,形成一个列表。 - 如果当前已选择的示例数量加上当前示例的困惑度超过了目标压缩率 π_dems 乘以示例集的总令牌数,那么停止迭代。
- 否则,将当前 Demonstration 添加到选定的示例集 D 中。
初始化一个计数器 α,用于跟踪已选择的示例Demonstrations数量。 对于列表中的每个 Demonstration(从第一个开始):
分配剩余预算:在完成 Demonstrations 部分的压缩后,将剩余的预算分配给指令和问题部分。这可以通过调整 和 的值来实现。 输出结果:输出经过粗粒度压缩的示例集 D,以及为指令和问题部分分配的额外预算 和 。 通过这个过程,预算控制器能够确保在压缩过程中,关键信息得以保留,同时实现对原始提示的有效压缩。这种方法特别适用于处理包含多个 Demonstrations 的提示,可以通过示例级别的控制来满足压缩要求。 2.2 Iterative Token-level Prompt Compression (ITPC)背景: 在LLMLingua方法中,利用困惑度(Perplexity)进行提示(prompt)压缩遇到了一个固有的局限性,即独立性假设。这个假设认为提示中的每个令牌(token)都是相互独立的,即一个令牌的出现概率仅取决于它之前的令牌,而与其他令牌无关。然而,在自然语言中,令牌之间往往存在复杂的依赖关系,这种关系对于理解上下文和保持语义完整性至关重要。 在数学上,这个独立性假设可以表示为: - $$P(x) = \prod_{i=1}^{N} P(x_i | x_{<i}) $$=""
这个假设的局限性在于,它忽略了令牌之间的条件依赖性,这可能导致在压缩过程中丢失关键信息,尤其是在进行高比例压缩时。例如,如果一个令牌在上下文中提供了关键的推理步骤或逻辑连接,那么仅仅基于其困惑度来决定是否保留这个令牌可能会导致推理过程的不完整。 为了解决这个问题,LLMLingua提出了迭代令牌级提示压缩(Iterative Token-level Prompt Compression, ITPC)算法。这个算法通过迭代地处理提示中的每个段(segment),并考虑每个令牌在当前上下文中的条件概率,从而更好地保留了令牌之间的依赖关系。这种方法允许算法在压缩提示时更加精细地评估每个令牌的重要性,而不是仅仅基于其独立的概率。 总结来说,利用困惑度进行提示压缩的固有局限性在于它简化了令牌之间的复杂关系,而LLMLingua通过迭代算法来克服这一局限性,实现了更有效的提示压缩,同时保持了语义的完整性。 方法: 迭代令牌级提示压缩(Iterative Token-level Prompt Compression, ITPC),其旨在通过考虑令牌之间的条件依赖关系来保留提示中的关键信息。以下是ITPC的详细步骤: 设置选定的令牌集 T:初始化一个空的令牌集 T,用于存储压缩后的令牌。 获取分段集合 S:将目标提示 x' 分割成若干个段 S = {s1, s2, ..., sN}。
使用小语言模型 计算该段的所有令牌的条件概率分布,公式: 其中,x' 是原始提示经过prompt压缩后的结果; 是第 i 个段;x'{i-1} 是第 i-1 个令牌;s{i-1} 是第 i-1 个段的最后一个令牌。 根据困惑度分布和相应的压缩比率 动态计算压缩阈值 : 其中,是段 的压缩比率,可以根据段的来源(来自 、 或)来确定,不同的来源设置不同的压缩比例。 将满足条件(PPL > )的令牌添加到令牌集 T 中。
输出压缩后的提示:将令牌集 T 中的所有令牌连接起来,形成最终的压缩提示。 通过这个迭代过程,ITPC算法能够在保持提示语义完整性的同时,有效地压缩提示的长度,从而减少大型语言模型(LLM)的推理成本。 2.3 Instruction Tuning指令调整(Instruction Tuning)是LLMLingua方法中的一个关键步骤,旨在缩小小型语言模型(用于压缩提示)与大型语言模型(LLM)之间的分布差异。以下是指令调整的详细步骤: 初始化小型语言模型:从一个预训练的小型语言模型 开始,例如 GPT-2 或 LLaMA。 使用LLM生成数据:使用目标LLM生成一些数据,这些数据将用于调整小型语言模型的参数。 定义优化目标:设定一个优化目标,使得小型语言模型 生成的指令 和LLM生成的文本 的分布尽可能相似。优化目标可以表示为: 其中, 是小型语言模型的参数, 是第 个训练样本对, 是损失函数, 是样本总数。 执行指令调整:使用上述优化目标对小型语言模型进行微调,以最小化两个模型之间的分布差异。
在调整完成后,评估小型语言模型的性能,确保其能够更准确地模拟目标LLM的分布。
通过指令调整,LLMLingua方法能够提高压缩提示的质量和LLM推理的效率,尤其是在处理复杂任务时,这种方法有助于保留关键信息并提高推理的准确性。 3 Conclusion- 压缩算法表现突出: 在GSM8K、BBH、ShareGPT和Arxiv-March23四个来自不同场景的数据集上的实验表明,LLMLingua能够实现高达20倍的压缩比率,并且几乎不损失性能。
- LLM能有效的恢复压缩的prompt,同时prompt压缩对输出长度的减少也有益处,还有个潜在的好处是可以处理更长的文本。
- 推理加速: 提供了一种有效的加速模型推理的方法,显著减少了因长提示而导致的成本。
4 Limitation- 适应性: 需要测试在更多场景与任务下压缩算法的适用性和表现。
- 鲁棒性: 需要进一步研究压缩算法对于不同类型和结构的长提示的鲁棒性。
二、详细内容 1 做了哪些实验?
- GSM8K:一个数学推理数据集,包含8,000个问题,用于评估模型在数学推理和公式推导方面的能力。
- BBH (Big-bench Hard):一个包含多种语言和符号推理任务的数据集,用于评估链式推理(chain-of-thought)提示的有效性。
- ShareGPT:一个对话数据集,包含用户与ChatGPT的对话,用于评估模型在对话理解和生成方面的能力。
- Arxiv-March23:一个学术文章摘要数据集,包含2023年3月从arXiv预印本库收集的最新学术文章,用于评估模型在文本摘要方面的能力。
- 对于GSM8K和BBH,使用精确匹配(Exact Match, EM)作为评估指标。
- 对于ShareGPT和Arxiv-March23,使用BLEU、ROUGE和BERTScore作为评估指标。
- LLMLingua:文章提出的方法,包括预算控制器(Budget Controller)、迭代令牌级提示压缩(Iterative Token-level Prompt Compression)和分布对齐(Distribution Alignment)。
- Baselines:包括GPT4-Generation(直接使用GPT-4压缩提示)、随机选择(Random Selection)、Selective-Context(基于小语言模型的自信息选择性压缩)等。
- 在GSM8K和BBH数据集上,设置了不同的压缩比(如1-shot、half-shot、quarter-shot等)来评估模型在不同压缩程度下的性能。
- 在ShareGPT和Arxiv-March23数据集上,设置了不同的目标压缩比(如2x、3x、5x等)。
- 使用了GPT-3.5-Turbo-0301和Claude-v1.3作为目标LLMs,通过OpenAI和Claude API进行访问。
- 使用Alpaca-7B或GPT2-Alpaca作为小型预训练语言模型()进行压缩。
- 实现基于PyTorch 1.12.05和Huggingface的Transformers库。
- 使用GPT-4模型尝试恢复压缩后的提示,并展示了恢复结果,以验证LLMs理解压缩提示的能力。
2 在对话(ShareGPT)和摘要(Ariv- March23)数据集上的表现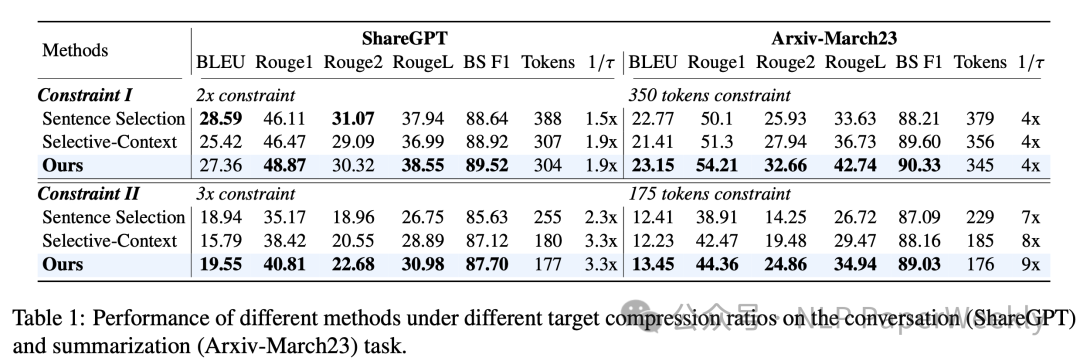 实验说明: - Constraint I (2x constraint): 目标压缩比为2倍。
- Constraint II (3x constraint): 目标压缩比为3倍。
- Selective-Context: 使用小语言模型计算每个词汇单元(如句子、短语或令牌)的自信息,然后删除信息量较低的内容以实现提示压缩。
- Ours (LLMLingua): 提出了LLMLingua方法,包括预算控制器、迭代令牌级提示压缩和分布对齐。
性能指标: - Tokens: 在给定压缩比下,压缩后的提示中的令牌数量。
- BLEU, ROUGE, RougeL, BS, F1: 这些是评估摘要任务性能的指标,分别代表BLEU分数、ROUGE分数、RougeL分数、BERTScore分数和F1分数。
- Tokens 1/π: 在给定压缩比下,压缩后的提示长度与原始提示长度的比例。
结论: - LLMLingua方法在大多数情况下都优于其他方法,尤其是在BLEU、ROUGE和BERTScore F1分数上。这表明LLMLingua能够在保持较高性能的同时实现显著的压缩比。
- 在ShareGPT任务中,LLMLingua在4倍压缩比下,BLEU分数为27.36,ROUGE分数为48.87,BERTScore F1分数为90.33,而Selective-Context在相同压缩比下的性能略低。
- 在Arxiv-March23任务中,LLMLingua在9倍压缩比下,BERTScore F1分数为89.03,同样优于Selective-Context。
这些结果表明LLMLingua方法在对话和摘要任务中都能够有效压缩提示,同时保持了良好的性能,这对于减少大型语言模型(LLM)的推理成本和提高效率具有重要意义。 3 在数学推理(GSM8K)和复杂语言任务(Big-bench Hard, BBH)数据集上的表现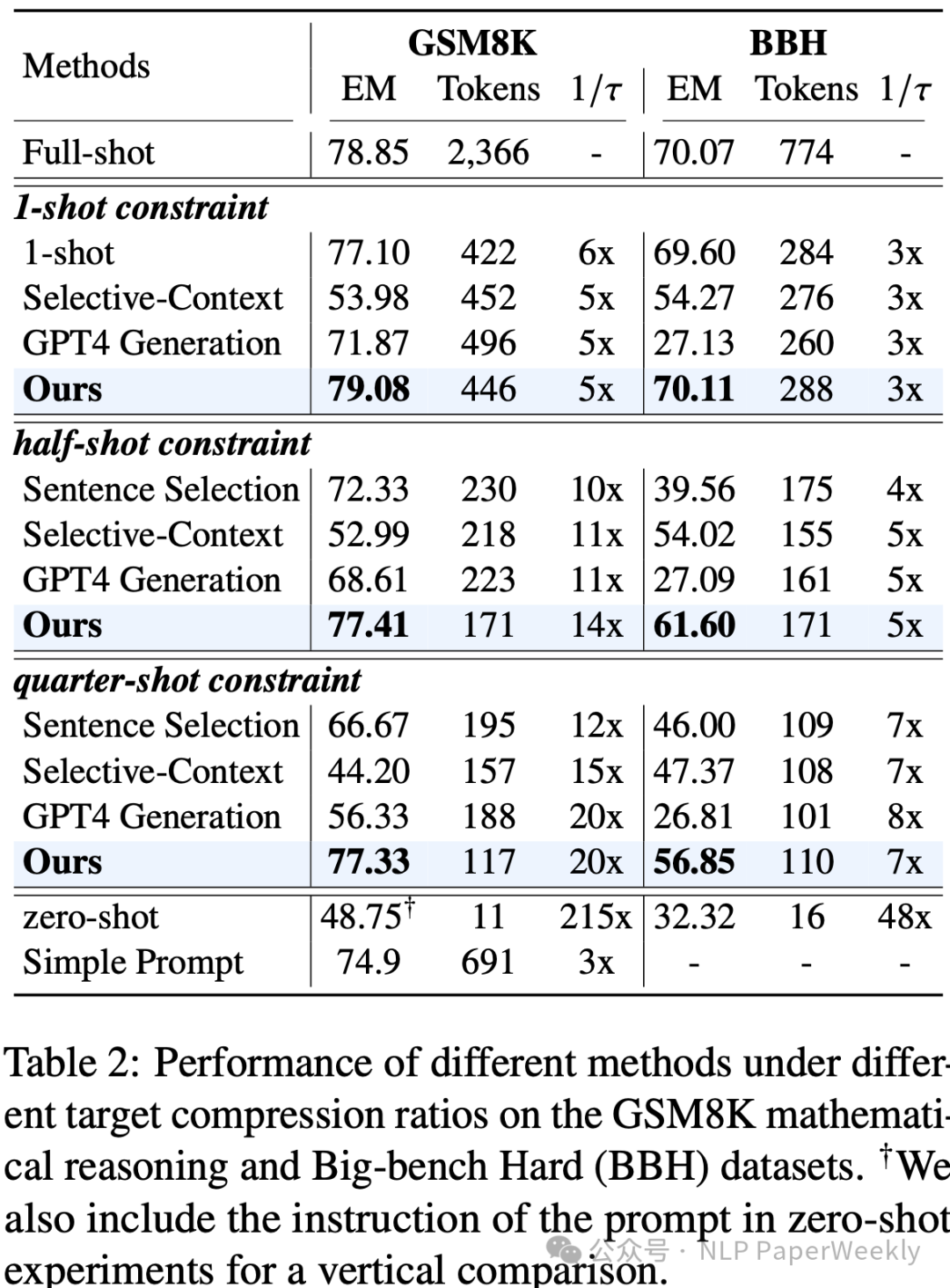 说明: - 1-shot constraint: 目标压缩比为1倍,即不压缩。
- Selective-Context: 使用小语言模型基于自信息选择性地压缩提示。
- GPT4 Generation: 使用GPT-4生成压缩后的提示。
- Ours (LLMLingua): 使用LLMLingua方法进行提示压缩。
性能指标: - EM: Exact Match,即精确匹配分数,用于评估数学推理任务的性能。
- Tokens: 在给定压缩比下,压缩后的提示中的令牌数量。
- 1/π: 压缩比,表示压缩后的提示长度与原始提示长度的比例。
结论: LLMLingua方法在不同的压缩比下都显示出了较好的性能。例如,在GSM8K数据集上,LLMLingua在5倍压缩比下达到了79.08%的EM分数,而在BBH数据集上,在3倍压缩比下达到了70.11%的EM分数。这些结果表明LLMLingua能够在保持较高推理性能的同时实现显著的压缩效果。 相比之下,GPT4 Generation方法在压缩提示时可能会遗漏关键信息,导致性能下降。Selective-Context方法虽然在某些情况下表现良好,但在压缩比增加时性能下降较快。LLMLingua通过预算控制器和迭代令牌级压缩算法,能够在保持语义完整性的同时实现更高的压缩比。 总的来说,LLMLingua方法在数学推理和复杂语言任务中都显示出了其有效性,能够在不牺牲太多性能的情况下实现提示的高效压缩。 4 消融实验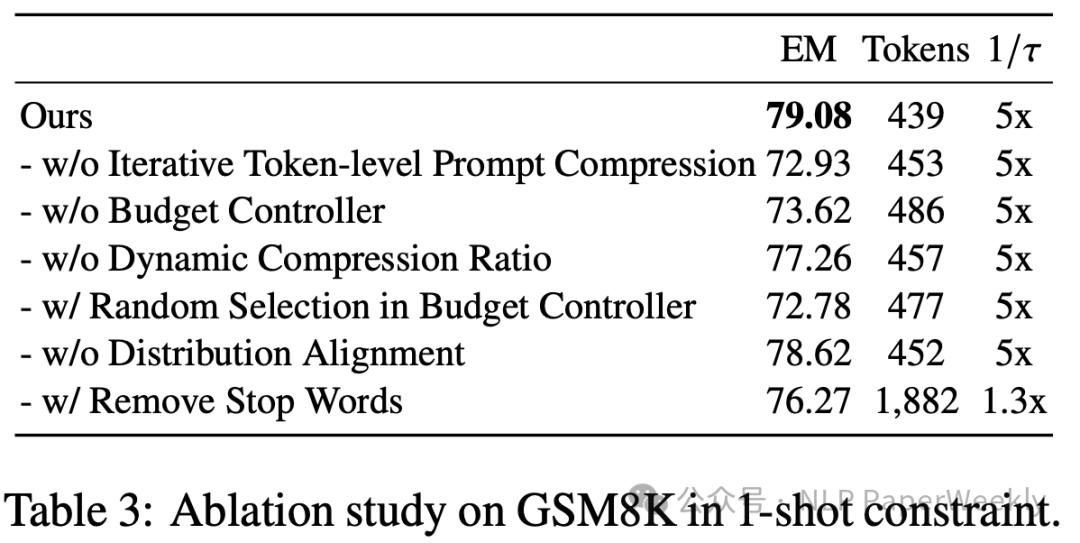 说明: - w/o Iterative Token-level Prompt Compression: 移除了迭代令牌级压缩,改为单次推理进行令牌级压缩。
- w/o Budget Controller: 移除了预算控制器,直接使用迭代令牌级压缩算法(ITPC)并应用相同的压缩比率给所有组件。
- w/o Dynamic Compression Ratio: 使用相同的压缩比率给所有组件,不进行动态调整。
- w/ Random Selection in Budget Controller: 在预算控制器中随机选择示范或句子进行示范级提示压缩。
- w/o Distribution Alignment: 移除了分布对齐模块,直接使用预训练的LLaMA-7B作为小型语言模型。
- w/ Remove Stop Words: 在原始提示中移除停用词,使用NLTK库实现。
性能指标: - EM: Exact Match,即精确匹配分数,用于评估数学推理任务的性能。
- Tokens: 在给定压缩比下,压缩后的提示中的令牌数量。
- 1/π: 压缩比,表示压缩后的提示长度与原始提示长度的比例。
结论: - 迭代令牌级压缩(Iterative Token-level Prompt Compression)对于保持压缩提示的精确匹配分数至关重要。没有这个组件,精确匹配分数会显著下降。
- 预算控制器(Budget Controller)有助于在不同组件之间平衡压缩比,以保持语义完整性。没有预算控制器,性能会有所下降。
- 动态压缩比率(Dynamic Compression Ratio)允许模型根据提示的不同部分调整压缩策略,这对于保持性能是有益的。
- 分布对齐(Distribution Alignment)通过调整小型语言模型以更接近目标LLM的分布,进一步提高了性能。
- 随机选择(Random Selection)在预算控制器中可能导致信息丢失,因为不是基于困惑度选择示范。
- 移除停用词(Remove Stop Words)可能会移除一些对推理过程重要的信息,导致性能下降。
三、总结 总结1:LLMLingua展示了在不损失大型语言模型性能的前提下,大幅度压缩模型输入提示的可能性,这为在资源受限情境下使用复杂模型提供了一条有效途径。 本文利用经过Alignment的well-trained的小的语言模型,例如GPT2-small或者LLaMA-7B,来检测和剔除prompt中的不重要token,将其转化为一种人类很难理解但是LLMs能很好理解的形势。并且这种被压缩的prompt可以直接用在black-box LLMs中,实现最高20倍的压缩,且几乎不影响下游任务性能。[2] 总结2:(Iterative Token-level Prompt Compression)对于保持压缩提示的精确匹配分数至关重要。没有这个组件,精确匹配分数会显著下降。 总结3:LLM的确能懂被压缩后人类难以理解的prompt,甚至还能复原原始prompt出来。  四、参考 [1]: Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models[J]. Advances in Neural Information Processing Systems, 2022, 35: 24824-24837. [2]: (Long)LLMLingua: 从压缩Prompt出发, 探究属于 LLMs 的语言,缓解Lost in the middle, 提升Long Context 下的性能:https://zhuanlan.zhihu.com/p/660805821 ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-weight: bold;color: rgb(0, 0, 0);font-size: 1.3em;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">五、更多文章精读- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: left;">百川智能RAG方案总结:搜索出生的百川智能大模型RAG爬坑之路
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: left;">ICLR 2023 | ReAct:首次结合Thought和Action提升大模型解决问题的能力
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: left;">ICLR 2023 | Self-Consistency: Google超简单方法改善大模型推理能力
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: left;">LLama2详细解读 | Meta开源之光LLama2是如何追上ChatGPT的?
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: left;">ChatLaw:北大凭什么以13B的基座模型击败恐怖如斯的GPT4?
|










