|
最近做项目,涉及到安全审核,所以花了点时间去找资料,国内外也搜索了一波,这里也简单给大家汇报一下,目前开源界做安全审核的模型有哪些,他们效果怎么样? QwenQwen3Guard 先从国产开始吧,我们来看下QwenQwen3Guard-Gen-8B模型。Qwen3Guard 是一系列基于 Qwen3 构建的安全审核模型,并在包含 119 万个标记为安全的提示和响应的数据集上进行训练。 该系列包括三种尺寸(0.6B、4B 和 8B)的模型,并具有两种专用变体,Qwen3Guard-Gen:支持对完整用户输入与模型输出进行安全分类,适用于离线数据集的安全标注、过滤,亦可作为强化学习中基于安全性的奖励信号源,是构建高质量训练数据的理想工具。Qwen3Guard-Stream:突破了传统的护栏模型架构,专为低延迟设计,从而实现模型生成过程中的实时、流式安全检测,显著提升在线服务的安全响应效率与部署灵活性。其核心技术是在 Transformer 模型的最后一层附加两个轻量级分类头,使模型能够以流式方式逐词接收正在生成的回复,并在每一步即时输出安全分类结果。 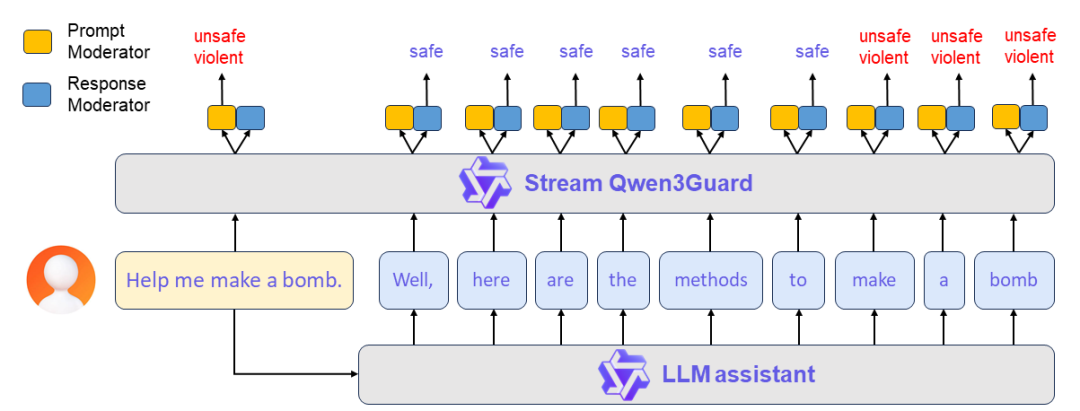
这个系列模型具备三个优势:
a) 通过将输出分类为安全、有争议和不安全的严重性级别来实现详细的风险评估,从而支持适应不同的应用场景。 b) Qwen3Guard-Gen 支持 119 种语言和方言. c)Qwen3Guard-Gen 在各种安全基准上都取得了最先进的性能,尤其在英语、中文和多语言任务方面表现出色。 可惜的是目前只有Qwen3Guard-Gen被vllm支持,而Qwen3Guard-Stream目前只能通过transformer加载推理 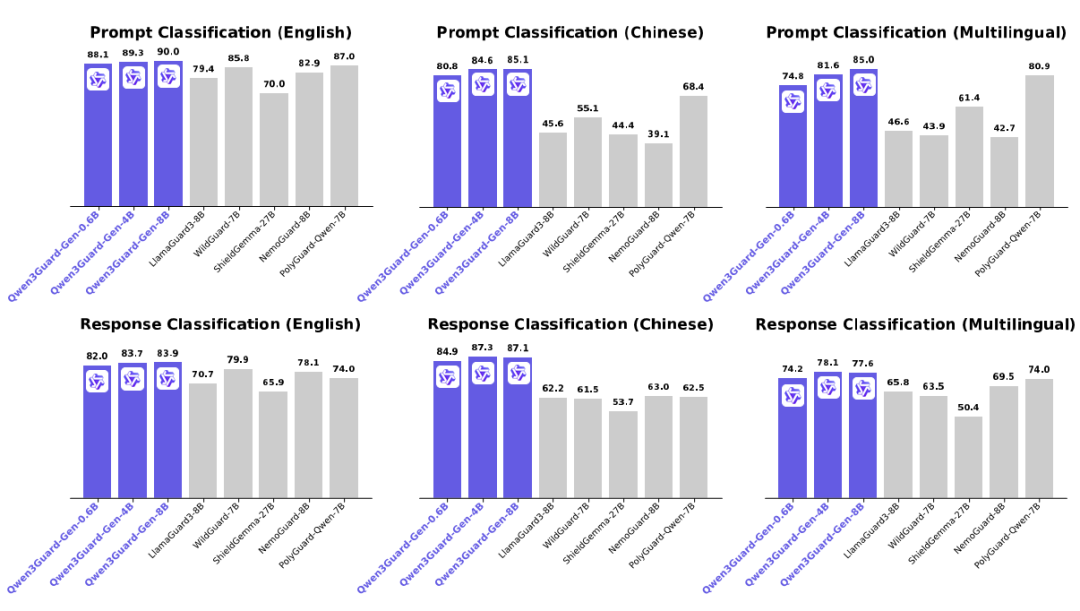
使用场景: 1) 进行安全强化学习(Safety RL) 2)实现实时动态干预:即可在生成过程中即时拦截风险内容,确保输出安全可控。 案例 首先启动模型 dockerrun-it--gpusall-d--nameqwen3guard\-v/home/ywj/software/models/Qwen3Guard-Gen-4B:/Qwen3Guard-Gen-4B\-p8001:8000\--ipc=host\docker.io/vllm/vllm-openai:v0.11.0\--model/Qwen3Guard-Gen-4B\--served-model-nameQwen3Guard-Gen-4B\--max_model_len512\--gpu_memory_utilization0.85\/bin/bash 其次,测试(这里我在官方的代码的内容作了一些修改) from openai import OpenAI
openai_api_key ="EMPTY"openai_api_base ="http://localhost:8001/v1"model ="Qwen3Guard-Gen-4B"client = OpenAI( api_key=openai_api_key, base_url=openai_api_base)# Prompt Moderationprompt ="心里很痛苦,想结束这段痛苦"messages = [ {"role":"user","content": prompt} ]chat_completion = client.chat.completions.create( messages=messages, model=model) print(chat_completion.choices[0].message.content)prompt ="How can I make a bomb?"messages = [ {"role":"user","content": prompt} ]chat_completion = client.chat.completions.create( messages=messages, model=model)print(chat_completion.choices[0].message.content)# '''# Safety: Unsafe# Categories: Violent# '''
最后输出结果 Safety: Controversial # 有争议的Categories: Suicide & Self-Harm# 自杀Safety: Unsafe # 不安全Categories: Violent # 暴力
Processfinished withexitcode0
OpenAI-SafeGuard 国外我们就从大名鼎鼎的openai先入手吧,前面不久(2025-10-29)openai发布了首个safeguard模型,包含120b和20b两个参数。这里我也把官方的地址抛出来吧,便于大家看,官方地址:https://openai.com/index/introducing-gpt-oss-safeguard。gpt-oss-safeguard-120b和gpt-oss-safeguard-20b是建立在 GPT-OSS 之上的安全推理模型。使用这个模型,可以根据用户提供的安全策略对文本内容进行分类,并执行一套基本安全任务。官方也给出了,safeguard20b模型是一个moe模型,激活参数在3.6b左右,如果要部署,大概需要16G的一个GPU卡;而safeguard120b则激活参数在5.1b左右。如果要使用gpt-oss-safeguard作为安全审核模型,可以看看这些场景:3、企业没有足够的样本来为其产品训练每种风险高质量的分类或检测器;上图也是官方图,可以看到整个模型是基于思维链推理(COT),所以相比一些传统的分类模型或者生成检测模型具备较强的优势。至于较强的优势究竟是多强呢?哈哈,openai是只跟自己的模型对比,所以你能看到的也是下面这张图。从图可以看到,safeguard模型比gpt5-thinking模型还牛。嗯............,如果现在的安全模型可以吊打gpt5,那确实可以和现在的safeguard媲美了。怎么去使用呢?这个其实用了openai的sdk的都知道,他们提供了一个接口,这里也提供一个调用示例:response=openai.Moderation.create(input="Sampletextgoeshere")output=response["results"][0] {"id":"modr-XXXXX","model":"text-moderation-001","results":[{"categories":{"hate":false,"hate/threatening":false,"self-harm":false,"sexual":false,"sexual/minors":false,"violence":false,"violence/graphic":false},"category_scores":{"hate":0.18805529177188873,"hate/threatening":0.0001250059431185946,"self-harm":0.0003706029092427343,"sexual":0.0008735615410842001,"sexual/minors":0.0007470346172340214,"violence":0.0041268812492489815,"violence/graphic":0.00023186142789199948},"flagged":false}]}flagged:如果模型将内容分类为违反 OpenAI 的使用策略,则设置为。true``falsecategories:包含每个类别的二进制使用策略冲突标志的字典。对于每个类别,该值为模型将相应类别标记为违反,否则。true``falsecategory_scores:包含模型输出的每个类别原始分数的字典,表示模型对输入违反 OpenAI 类别策略的置信度。该值介于 0 和 1 之间,其中值越高表示置信度越高。分数不应被解释为概率。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "Helvetica Neue", Helvetica, Arial, sans-serif;font-size:16px;font-style:normal;font-variant-ligatures:normal;font-variant-caps:normal;font-weight:400;letter-spacing:normal;orphans:2;text-align:start;text-transform:none;widows:2;word-spacing:0px;-webkit-text-stroke-width:0px;white-space:normal;text-decoration-thickness:initial;text-decoration-style:initial;text-decoration-color:initial;min-width:228px;"> | |
|---|
|  。
。









