|
JoyAgent 是京东自主研发的智能体引擎平台。今年7月其多智能体引擎模块JoyAgent (JDGenie)正式开源;9月在 JDGenie 基础上进一步开源 DataAgent 能力,此次,京东再次发布重要更新-在JoyAgent-JDGenie中开源多模态RAG能力。持续推进智能体技术在开源社区的共建与共享。目前该项目在GitHub上已获得11.2kStar,欢迎开发者体验并参与共享。 | https://github.com/jd-opensource/joyagent-jdgenie | | https://github.com/jd-opensource/joyagent-jdgenie/blob/data_agent/README_mrag.md |
多模态知识管理简介 传统RAG基础架构 传统的检索增强生成(RAG)技术,在处理文本知识方面取得了显著的成功,它通过外部知识库有效缓解了大型语言模型的“幻觉”问题。但其局限性也日益凸显 一、多模态问题:处理结构化与非结构化内容当面对企业内普遍存在的文档时,一个仅能理解文字的RAG系统,无法阅读和理解图片、表格中蕴含的丰富信息。这导致了检索的片面性与答案的不完整性,大量高价值的知识资产因此沉睡,无法被有效利用。 一方面图像中的数据(如截图或扫描件)也无法被文本RAG系统直接理解。另一方面PDF文档尤其是包含嵌入式表格、图表和复杂布局的文档,需要复杂的解析逻辑,因为其格式和布局往往不一致 。传统的文本提取方法在此处会丢失关键信息,例如表格中数字的列关系或图表中数据的视觉趋势。大型语言模型(LLM)主要通过海量的顺序文本进行训练,因此它们在处理多维、关系化的表格数据时会遇到困难 。如果将表格简单地转换为纯文本进行嵌入,就会破坏其固有的结构化关系,导致检索结果的准确性大打折扣 。 二、数据质量与动态性:RAG性能的杀手企业知识库面临的另一个严峻挑战是数据质量的参差不齐和内容的频繁更新。如果知识库中存在不一致的格式、过时的信息、重复的条目或相互冲突的事实,往往无法给出准确的回答 。 同时,知识库并非静态不变。在实际的企业环境中,文档更新频繁。管理这些变更是本身就是一项复杂的任务,因为每一次更新或删除都可能需要同步其在索引中的所有相关数据块和向量。此外,公司的一些核心信息往往驻留于实时、动态的运营系统(如CRM、ERP)中 。这些数据都是传统RAG所无法处理的。 JoyAgent企业内多模态知识管理系统架构一、知识加工层时序知识图谱我们引入graphiti,一个构建和查询时间感知知识图谱的框架,建设时序知识图谱。Graphiti 基于事件更新的时序知识图谱构建,增量更新、双时间建模(跟踪事件发生时间和摄入时间),并在无需完整重新计算的情况下处理随时间演变的关系统计。利用它可以可以整合并维护动态的用户交互和业务数据,支持智能体基于状态的推理和任务自动化。 - 时间特征在需要历史分析的场景中特别有价值,如金融服务的审计合规或供应链管理的趋势预测。
多文档格式多数据源支持为了支持企业内丰富的文档格式,我们支持文档(Excel、Word、PDF、PPT,图片等),同时需要对视频做专门的ASR以及关键帧切片处理。 此外,为了提升异构数据的处理效果,我们定义了统一的文档结构,针对不同类型的文件定义不同的解析算法,输出统一的文档结构,方便后续的用户人工干预和索引构建流程。 企业中大量的支持存储在系统里(例如ERP,CRM等),因此除了支持普通的文件输入,我们还需要支持API形式的数据录入。我们专门优化了针对API的数据调用流程和系统描述。这样上层Agent能动态发现是否需要调用某个API获取对应的数据。 知识使用层-多模态RAG多结构索引为了尽可能的召回需要的知识片段,以及建立知识之间的相互关系。我们建立了基于图谱的GraphRAG, 基于tag的关键词索引以及传统的Emebedding索引。 分块策略直接决定上下文的完整性和连贯性,从而影响生成输出的质量。普通分块可能破坏语义完整性,降低相关性。在长篇文档中往往标题,副标题是对一大片文档的整体总结,如果只看分块可能会造成信息丢失。因此,我们优化了分块策略,引入层级分块策略。 Hierarchical Chunk Index(层级分块索引) 层级分块能够将文档内容按照语义关系和结构层级进行分块管理,使得系统在检索时能够更细致地定位相关信息,并有效支持长文档和复杂结构的内容解析与检索 知识图谱召回 GraphRAG 通过构建节点(实体)和边(关系)的图结构,捕捉这些内在连接,实现多跳推理——例如,从“产品销售数据”跳到“客户反馈”再到“供应链调整”。这种方法在复杂推理任务中可将准确率提升高达35%。为了适应企业数据的动态性以及时序性,我们引入了时序知识图谱,每条边记录事件有效期和系统录入时间,允许企业查询历史状态,这就使得AI Agent能维护连续上下文,跟踪用户偏好。 Agentic 搜索传统的RAG系统本质上是一种“被动”的、单轮次的“检索后阅读”模式。它擅长于处理简单的信息检索,但面对复杂、多步骤的查询时,其能力边界便显现出来。Agentic RAG 能根据检索结果进行主动规划、推理和执行,将LLM从一个被动的响应者转变为一个能够主动思考、调查并解决问题的智能体。 为了平衡时间和效率问题,目前我们开放了配置选项,用户可以自主选择是否需要开启Agentic的能力,如果关闭,则回归传统模式,走一次检索总结流程。 多模态检索 由于大量的知识在图片,pdf或者表格中,在没有看到query前直接用ocr,或者摘要会造成信息丢失。因此在我们实现多模态检索时,我们增加了VLM进行回答的过程。我们将query与召回的图片进行交给VLM进行处理。再将VLM输出的答案与文本召回的Chunk一起交给后续的LLM进行处理。 目前我们提供了两种多模态能力。我们提供了两个多模态工具,供上层Agent自主决策调用哪个多模态能力。 - 图片问答,用户输入图片,直接对图片内容进行问答、摘要、翻译等操作。
- 图片检索,用户输入图片或者文字,利用向量检索召回相似图片。
我们还有一个文本搜索工具。这样让Agent自主决策调用哪个工具,甚至是多步的工具组合,我们可以让多模态检索Agent处理企业内各种复杂场景。举个例子,供应链管理人员收到仓库上传的异常货物照片,需要判断异常类型、查找历史处理案例,并获取应急处理流程。 评测数据在公开数据集DoubleBench上,我们对比测评了MDocAgent、Colqwen-gen、ViDoRAG、M3DOCRAG等多模态问答系统。最终答案的准确性采用LLM作为评判标准进行评估。 GPT-4o根据0到10的等级对生成的答案与真实答案的正确性进行评分。得分不低于7分的答案为正确,不高于3分的答案为错误,其余答案为部分正确。JoyAgent的正确率达到76.2%,优于当前其他多模态问答系统。 - Colqwen-gen:参照组,结果由gpt-4o直接回复生成(不采用RAG)。
此外,我们还利用企业内部文档,包括培训资料,产品RPD,运营计划构建了测试集,在150个query,500篇文档的测试集中横向对比了coze,ima和JoyAgent。 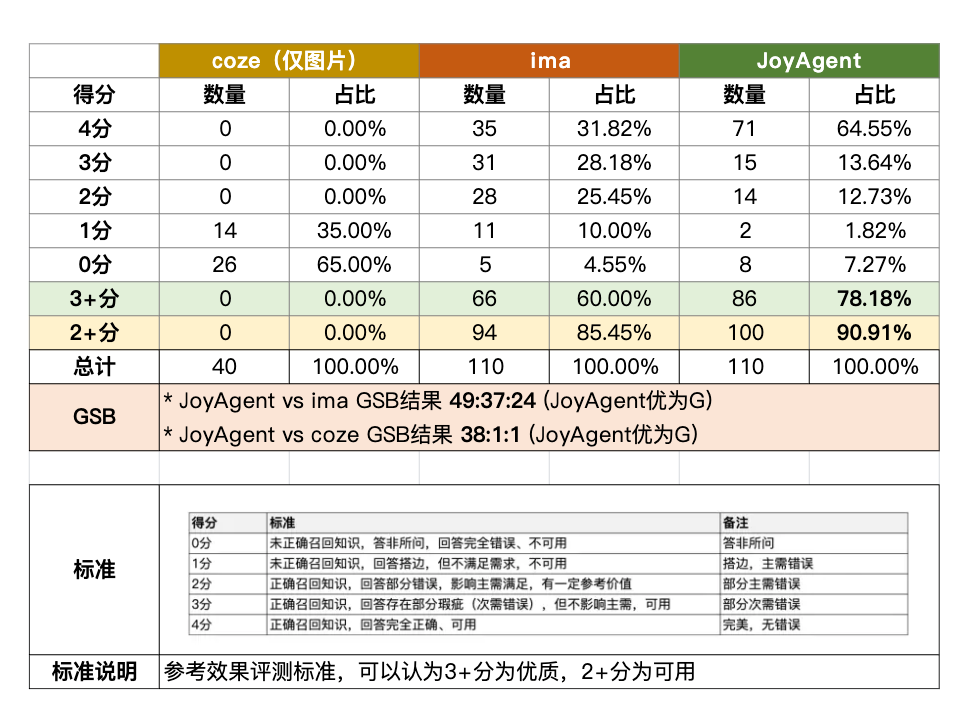
未来计划RAG的未来发展将是多范式融合的持续演进。可以预见,未来的系统将无缝地集成Agentic和GraphRAG的能力,智能体将能够动态地决定何时从知识图谱中检索关系信息,何时调用外部工具执行复杂任务。同时,多模态能力的持续进步将使RAG系统能够处理并理解更加多样化的数据类型,从而真正成为一个能够理解和利用企业所有知识资产的综合性智能系统。 当然知识加工和知识检索知识知识库管理的第一步,利用知识生成知识,才是诗和远方。我们将继续沿着多模态DeepSearch的方向继续迭代,加深知识和文档管理层面能力建设。真正为企业内员工知识加工,知识检索,知识生成提供帮助J
| 









