ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;background-color: rgb(255, 255, 255);visibility: visible;">
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;display: table;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);visibility: visible;">引言在深度学习模型设计中,正则化(Regularization)是通过对模型施加约束或惩罚的方式。
如果不加任何约束,模型很容易将训练数据中的噪声也学习到,从而过度拟合于训练数据,无法很好地泛化到新的测试数据上,对未见过的、新的数据,判断的准确率低,是提高模型泛化能力的一种手段。 ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">超参数在开始介绍正则化前,我们先来了解下超参数。在深度学习中,所谓学习,实际上是指设计好模型后,利用预处理的数据(已经打过标记的数据,比如图片A是猫,图片B是狗),结合数学方法(损失函数,梯度等),不断调整模型中的参数,使得模型输出的结果尽可能地跟打过标记的数据一致。判断模型输出结果跟标记号的数据的一致程度,我们用损失函数(模型结果 - 实际结果)的值来评估,值越大说明偏离的越多,算法的目标就是通过梯度,找到参数调整的方向,再结合学习率(调整的系数,系数越大,调整的越多),不断更新参数。其实,这里的学习率就是超参数的一种。超参数(Hyper-parameter)指的是在模型训练之前需要人为设定的一类参数值。与模型在训练过程中自动学习获得的参数(如神经网络中的权重和偏置)不同,超参数无法通过模型自身训练获得,需要人为依据经验或者一些调参技巧来设置合适的值。上文提到的学习率,以及本文要讲的L1\L2正则化强度,都是超参数(其它的像Dropout率,训练时的迭代次数,训练数据的批次大小等等)。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">L1、L2正则化的数学定义L1正则化通过向损失函数添加一个与模型权重的绝对值成正比的项(即L1范数),它在数学上的表示如下:
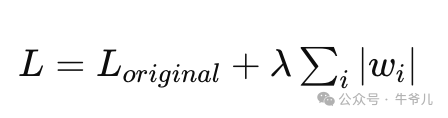
其中Loriginal是原始的损失,比如MSE,λ是人为设定的超参数(正则化强度),控制L1正则化项对总损失的贡献大小,鼓励模型产生更少的非零权重,也就是某些权重会被置为0,准确点的表述是推向0(why?可以先想一下)。
L2正则化,也称为权重衰减,通过向损失函数添加一个与权重系数平方成正比的项,从而鼓励模型学习到更小的权重。它在数学上的表示如下: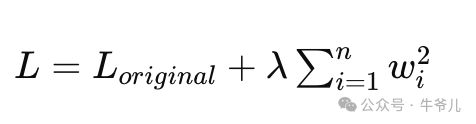
公式中只是把L1的取绝对值换成了取平方。L2正则化倾向于惩罚大的权重值,促使模型偏好于更小的权重值(为什么不像L1那样,降部分权重置为0呢?)。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">为什么L1、L2正则化,能够使得模型泛化能力更好,减少过拟合?L1、L2正则化的核心是降低模型的复杂度,也就是对参数的依赖。在训练模型的过程中,为什么会出现过拟合的情况呢?
主要还是因为在学习的过程中,模型参数导致的,参数越多,模型的表达能力就越强,它就越能让预测值接近实际值,出现过拟合的情况。比如,在做线性回归的过程中,如果数据交叉的比较厉害,相比用直接来分割数据,曲线的效果会更好,反馈到模型上,就是模型会更复杂,直线可以用一元一次方程表示,而曲线,那就~
L1正则化倾向于产生稀疏的权重矩阵,即许多权重被置为零。相当于进行了特征选择,只保留了对模型输出最有贡献的输入特征。当一些特征对预测目标贡献不大时,L1正则化通过消除这些不重要的特征来简化模型,这有助于提高模型的解释性和泛化能力。
L2正则化鼓励模型权重趋向于较小的值,但不会完全置为零,这是跟L1的核心区别。它导致了权重的平滑分布,减少了模型对单个特征的依赖,使模型更加稳健。通过惩罚大的权重值,L2正则化有助于防止模型权重对少数极端值过度敏感,从而提升模型在新数据上的表现。 ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">为什么L1、L2对参数的约束会表现不同?L1,L2正则化,从数学上理解他们表现出的差异会更好一些,在反向传播求梯度时,L1对wi求偏导数,结果是 λ(需要考虑参数的符号),且是不连续的;L2对wi求偏导数时,结果是2λwi,且是连续的。
对于L1来说,更新步骤会考虑到 λ 乘以权重的符号。如果wi > 0,更新类似 wi = wi -λ;如果wi < 0时,更新类似 wi = wi +λ;对于非常小的 wi,很容易将wi更新为0,或者跨过0,改变符号。这对于计算损失来说,只有在wi=0时,才能取到最小值,跨过0点,都会让损失函数变大。
但是对于L2,由于函数的连续性,在更新参数后,损失函数始终是往减小的方向逼近,但是不会存在突变点,这个特点,导致L2能够保留小的参数,而不是将参数置为0。 ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">pytorch里面如何实现L1,L2?这里直接上核心代码吧,本文主要是想让大家能够理解L1,L2的概念以及差异。
L1正则化:
import torchimport torch.nn as nnimport torch.optim as optim# 正则化强度lambda_l1 = 0.05
# 训练模型for epoch in range(100):# 训练100轮optimizer.zero_grad() # 清空梯度outputs = model(x_train)# 前向传播mse_loss = criterion(outputs, y_train)# 计算MSE损失l1_reg_loss = 0for param in model.parameters():l1_reg_loss += torch.norm(param, 1)# 计算L1正则化损失loss = mse_loss + lambda_l1 * l1_reg_loss# 总损失包括MSE损失和L1正则化损失loss.backward()# 反向传播optimizer.step()# 更新权重
if epoch % 10 == 0:print(f'Epoch {epoch}, Loss: {loss.item()}')
L2正则化:
#使用SGD优化器并添加L2正则化(权重衰减)optimizer=optim.SGD(model.parameters(),lr=0.01,weight_decay=0.01)#weight_decay参数就是λ
|










