|
在大型语言模型(LLMs)的研究和应用中,一个突出的挑战是它们在生成文本时可能会产生“幻觉”(hallucinations),即生成与事实不符的内容。这种现象的出现,主要是因为这些模型仅依赖其内部的参数知识,难以确保生成文本的准确性。为了解决这一问题,研究者们提出了检索增强生成(RAG)的方法,它通过检索外部知识库中的相关信息来辅助语言模型生成更准确的文本。 然而,RAG方法的有效性高度依赖于检索到的文档与查询的相关性和准确性。如果检索结果不准确或不相关,可能会导致生成模型的性能下降,甚至加剧错误信息的产生。为了提高RAG方法的鲁棒性,来自中国科学技术大学的Shi-Qi Yan、Jia-Chen Gu等人,以及谷歌研究院的Yun Zhu和Zhen-Hua Ling,在2024年提出了一种新的模型——纠正性检索增强生成(Corrective Retrieval Augmented Generation,简称CRAG)。该模型旨在通过设计轻量级的检索评估器和引入大规模网络搜索,来改进检索文档的质量,并通过分解再重组算法进一步提炼检索到的信息,从而提升生成文本的准确性和可靠性。 CRAG模型的提出,是对现有RAG技术的有益补充和改进,它通过自我校正检索结果,增强了生成文本的鲁棒性。这一研究工作不仅展示了在处理语言模型生成任务时如何提高对检索错误的鲁棒性,而且通过一系列实验验证了CRAG在多种数据集上的有效性,包括短文本和长文本生成任务。该研究成果在自然语言处理领域具有重要的理论和实践意义,为提升语言模型在复杂知识密集型任务中的表现提供了新的思路和方法。 ingFang SC";font-weight: bold;color: rgb(255, 255, 255);line-height: 22px;letter-spacing: 1px;">1.1、从开卷考试到智能信息检索ingFang SC";font-weight: bold;color: rgb(24, 61, 111);line-height: 22px;letter-spacing: 1px;">
想象一下你正在参加一场开卷考试。面对试卷上的各种问题,你会如何作答呢?或许你会采取以下三种策略之一: 凭借记忆快速作答:对于熟悉的题目,直接凭借记忆快速作答。而对于不熟悉的题目,则查阅参考书,找到相关章节,快速理解并总结,然后将答案写在试卷上。 逐题查阅参考书:对于每一道题目,都仔细查阅参考书,找到相关章节,理解并总结内容,然后将答案写在试卷上。 批判性地查阅参考书:对于每一道题目,都查阅参考书并找到相关章节。在形成答案之前,你会将收集到的信息进行分类,区分哪些是正确的、哪些是错误的,哪些是模棱两可的。然后,你会分别处理每种类型的信息,最终将整理和总结后的答案写在试卷上。
这三种策略分别对应了三种不同的信息检索和答案生成方式。第一种策略类似于人类凭借自身知识储备直接作答,第二种策略类似于传统的检索增强生成 (RAG) 技术,而第三种策略则对应着本文将要介绍的 纠正性 RAG 模型 (CRAG)。 CRAG 模型通过引入信息评估机制和知识精炼算法,能够更有效地筛选和处理信息,从而提升信息检索和答案生成的质量,避免错误或误导性信息的干扰。 接下来,我们将深入探讨 CRAG 模型的工作原理、技术细节和优势,并对其应用前景进行展望。
传统的检索增强生成 (RAG) 方法在信息检索过程中存在一些局限性,这可能会影响最终生成内容的质量。下图展示了这种局限性带来的问题。 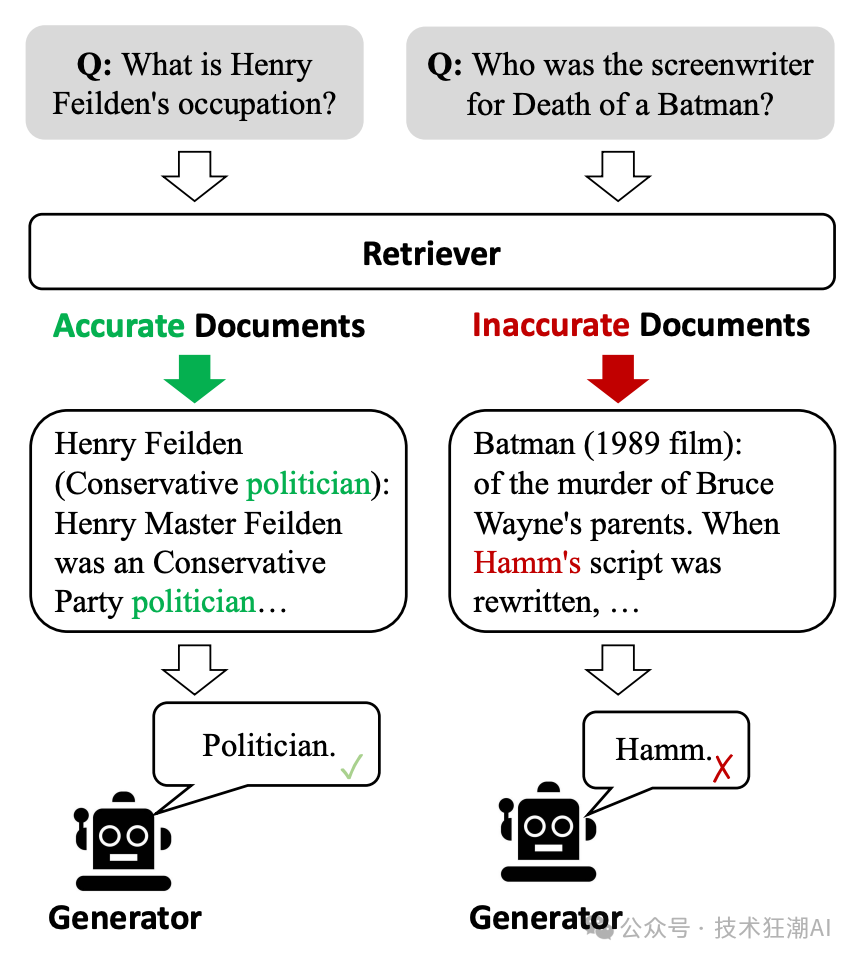
图 1: ( Figure 1: ) 示例表明,低质量的检索器 (负责信息检索的模型) 容易引入大量无关信息,这会阻碍生成器 (负责内容生成的模型) 获取准确的知识,并可能对其产生误导。来源:纠正性检索增强生成。 问题一:缺乏相关性评估 传统的 RAG 方法往往没有考虑检索到的文档与问题之间的相关性,而是简单地将所有文档合并在一起作为生成模型的输入。这会导致大量无关信息的引入,从而影响生成模型对知识的理解,并可能导致模型生成与事实不符的“幻觉”内容。 问题二:信息冗余 传统的 RAG 方法通常将整个检索到的文档作为输入,而实际上,文档中的大部分内容可能与生成内容无关。这些冗余信息不仅会增加模型的计算负担,还会影响模型对关键信息的提取和利用。 为了解决这些问题,CRAG 模型引入了信息评估机制和知识精炼算法,能够更有效地筛选和处理信息,从而提升信息检索和答案生成的质量。
CRAG 设计了一个轻量级的检索评估器,用于评估针对特定问题检索到的文档的整体质量。它还会利用网络搜索作为辅助工具,进一步提升检索结果的质量。 CRAG 具有即插即用的特性,可以与各种基于检索增强生成 (RAG) 的方法无缝集成。整体架构如图 2 所示。 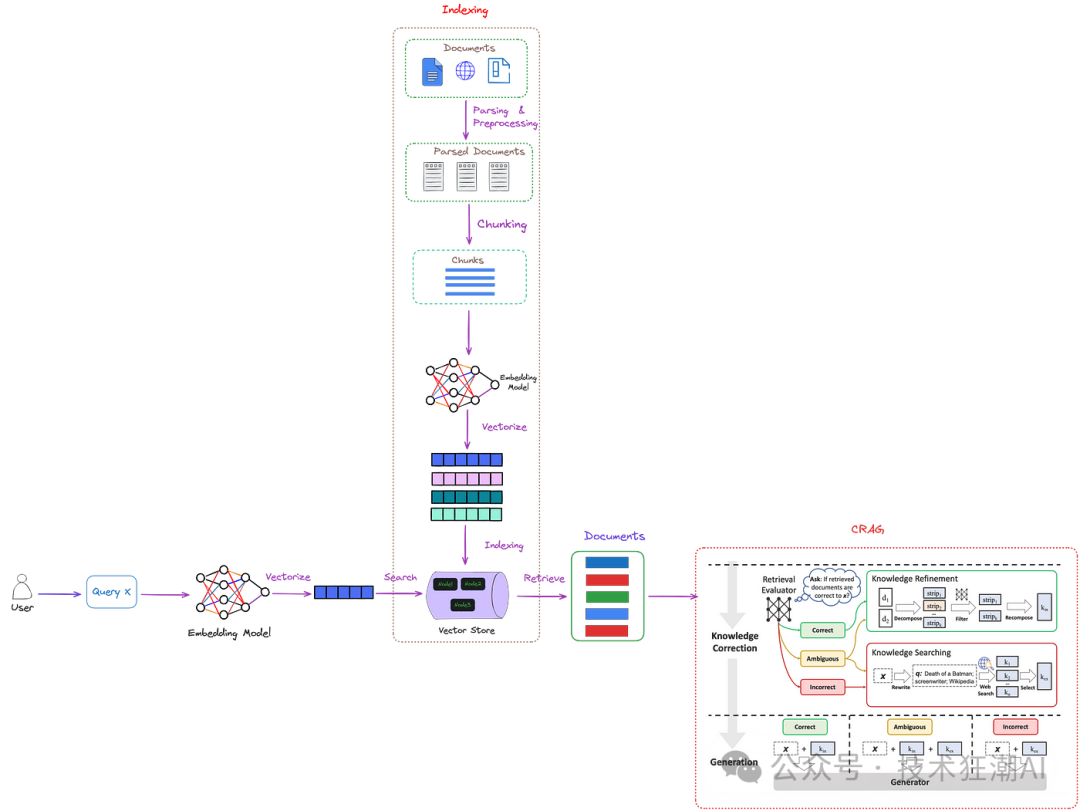
图 2: ( Figure 2: ) CRAG 在 RAG 中的位置 ( 红色虚线框 )。检索评估器用于评估检索到的信息与输入问题的相关性。它还会估计一个置信水平,并根据置信水平触发不同的知识检索操作,包括 { 正确、错误、模棱两可 } 三种情况。图中,“x”代表输入问题。图片由作者提供,CRAG 部分 ( 红色虚线框 ) 来源于纠正性检索增强生成。 如图 2 所示,CRAG 通过引入检索评估器来评估检索到的信息与问题之间的关系,从而改进增强了传统的 RAG 方法。 检索评估器会对检索到的信息进行判断,并给出三种可能的结果: 正确:这意味着检索到的信息包含了回答问题所需的必要内容。此时,CRAG 会使用知识细化算法 ( 一种用于优化信息的算法 ) 对检索到的信息进行处理和精炼。 错误:这意味着检索到的信息与问题无关。在这种情况下,CRAG 不会将这些信息传递给大语言模型 (LLM),而是会利用网络搜索引擎来获取外部知识,以寻找更相关的信息。 模棱两可:这意味着检索到的信息可能与问题相关,但不足以提供完整的答案。这时,CRAG 会结合使用知识细化算法和网络搜索引擎,获取更多信息来完善答案。
最后,经过处理和精炼的信息会被传递给大语言模型,用于生成最终的答案。图 3 将更详细地展示这个过程。 
图 3: ( Figure 3: ) 评估和处理流程。来源:纠正性检索增强生成。 需要注意的是,网络搜索并不是直接使用用户输入的问题进行搜索。它实际上是通过构建一个提示,然后以少样本学习 ( few-shot learning ) 的方式将其提供给 GPT-3.5 Turbo 模型,让 GPT-3.5 Turbo 生成用于搜索的查询语句。 在对 CRAG 的方法有了初步了解之后,我们接下来详细探讨 CRAG 的两个核心组成部分:检索评估器和知识精炼算法。 ingFang SC";font-weight: bold;color: rgb(255, 255, 255);line-height: 22px;letter-spacing: 1px;">3.1、检索评估器ingFang SC";font-weight: bold;color: rgb(24, 61, 111);line-height: 22px;letter-spacing: 1px;">
如图 4 所示,检索评估器对后续步骤的结果有着显著的影响,并且对于整个系统性能的好坏起着决定性的作用。 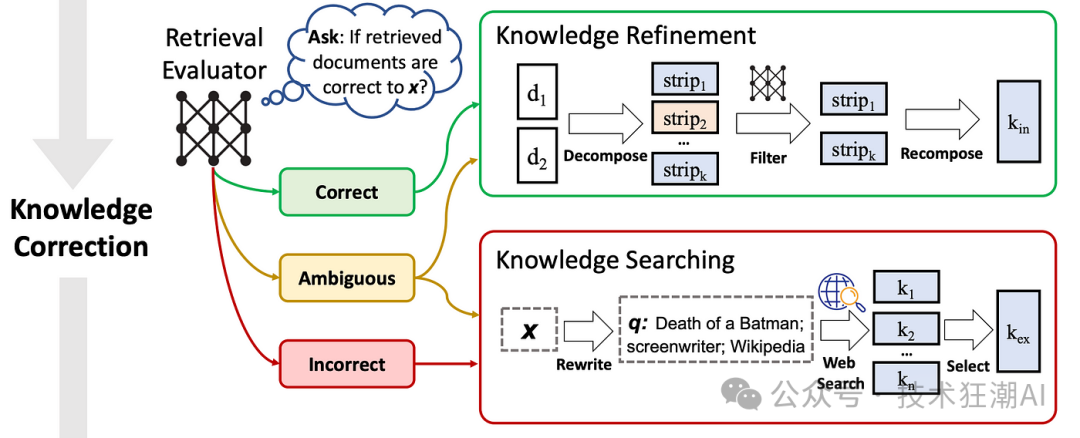
图 4: ( Figure 4: ) CRAG 中的知识纠正过程。来源:纠正性检索增强生成。 CRAG 使用一个轻量级的 T5-large 模型作为检索评估器,并对其进行了微调。值得一提的是,即使在大语言模型时代,T5-large 模型仍然被认为是轻量级的。 对于每个输入问题,CRAG 通常会检索十个相关的文档。然后,系统会将问题与每个文档分别组合在一起,作为输入数据,让 T5-large 模型预测它们之间的相关性。在微调过程中,模型会将标签 1 分配给正样本 ( 与问题相关的文档 ),将标签 -1 分配给负样本 ( 与问题无关的文档 )。在推理过程中,评估器会为每个文档分配一个介于 -1 到 1 之间的相关性分数。 这些相关性分数将根据预设的阈值被划分为三个不同的等级。显然,这一分类过程需要用到两个阈值。在 CRAG 中,阈值的设置可能会根据实验数据的不同而有所变化: 触发三个动作之一的两个置信度阈值是根据经验设置的。具体来说,它们在PopQA中设置为(0.59,-0.99),在PubQA和ArcChallenge中设置为(0.5,-0.91),以及在传记中设置为(0.95,-0.91)。 ingFang SC";font-weight: bold;color: rgb(255, 255, 255);line-height: 22px;letter-spacing: 1px;">3.2、知识精炼算法ingFang SC";font-weight: bold;color: rgb(24, 61, 111);line-height: 22px;letter-spacing: 1px;">
CRAG 设计了一种新颖的知识提取方法,即先分解文档再重新组合,以便深入挖掘文档中的核心知识点,这一过程在图 4 中有详细展示。 首先,利用一系列规则将文档细分为细小的知识单元,目的是获取更精细的知识点。如果检索到的文档只包含一句话或两句话,它将被视为一个整体。如果文档更长,则会根据其总长度被进一步细分为包含数个句子的小单元,每个单元都应包含一个完整的信息点。 然后,利用检索评估器为每个知识单元计算相关性评分,筛除那些评分较低的单元。剩下的、评分较高的知识单元将被重新组合,构建成完整的内部知识体系。
CRAG 是一个开源项目,LangChain 和 LlamaIndex 都提供了各自的实现版本。本文将以 LlamaIndex 的实现为例进行说明。
ingFang SC";font-weight: bold;color: rgb(255, 255, 255);line-height: 22px;letter-spacing: 1px;">4.1、环境配置ingFang SC";font-weight: bold;color: rgb(24, 61, 111);line-height: 22px;letter-spacing: 1px;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">condacreate-ncragpython=3.11
condaactivatecrag
pipinstallllama-indexllama-index-tools-tavily-research
mkdir"YOUR_DOWNLOAD_DIR" 安装完成后,LlamaIndex 和 Tavily 的相应版本如下: ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">(crag)$piplist|grepllama
llama-index0.10.29
llama-index-agent-openai0.2.2
llama-index-cli0.1.11
llama-index-core0.10.29
llama-index-embeddings-openai0.1.7
llama-index-indices-managed-llama-cloud0.1.5
llama-index-legacy0.9.48
llama-index-llms-openai0.1.15
llama-index-multi-modal-llms-openai0.1.5
llama-index-packs-corrective-rag0.1.1
llama-index-program-openai0.1.5
llama-index-question-gen-openai0.1.3
llama-index-readers-file0.1.19
llama-index-readers-llama-parse0.1.4
llama-index-tools-tavily-research0.1.3
llama-parse0.4.1
llamaindex-py-client0.1.18
(crag)$piplist|greptavily
llama-index-tools-tavily-research0.1.3
以下是测试代码示例。首次运行时,需要先下载 CorrectiveRAGPack 包。 importos
os.environ["OPENAI_API_KEY"]="YOUR_OPENAI_API_KEY"
fromllama_index.coreimportDocument
#选项:下载 CorrectiveRAGPack
#第一次执行需要下载CorrectiveRAGPack
#后续执行可以注释掉这一行。
fromllama_index.core.llama_packimportdownload_llama_pack
CorrectiveRAGPack=download_llama_pack(
"CorrectiveRAGPack","YOUR_DOWNLOAD_DIR"
)
#创建测试文档
documents=[
Document(
text="一群企鹅,在陆地上被称为“摇摆者”,在南极冰面上蹒跚而行,它们燕尾服般的羽毛在雪地上格外醒目。"
),
Document(
text="帝企鹅是所有企鹅物种中最高的,可以比任何其他鸟类潜得更深,达到 500多米的深度。"
),
Document(
text="企鹅的黑白颜色是一种被称为反荫蔽的伪装形式;从上面看,它们的黑色背部与海洋深处融为一体,而从下面看,它们的白色腹部与明亮的表面相匹配。"
),
Document(
text="尽管企鹅站姿挺拔,但它们是不会飞的鸟类;它们的翅膀已经进化成鳍状肢,使它们成为游泳健将。"
),
Document(
text="速度最快的物种巴布亚企鹅,游泳速度可达每小时 36 公里,它们利用鳍状肢和流线型身体在水中穿梭。"
),
Document(
text="企鹅是群居鸟类;许多物种形成大型繁殖群,数量可达数万只。"
),
Document(
text="有趣的是,企鹅的听力非常好,它们依靠独特的叫声在嘈杂的群体中识别它们的配偶和雏鸟。"
),
Document(
text="最小的企鹅物种小蓝企鹅,身高只有 40厘米左右,分布在澳大利亚南部和新西兰的海岸线上。"
),
Document(
text="在繁殖季节,雄性帝企鹅会在严酷的南极冬季忍受数月,禁食并孵化它们的蛋,而雌性则在海上捕猎。"
),
Document(
text="企鹅吃各种海鲜;它们的饮食主要包括鱼、鱿鱼和磷虾,它们在潜水探险中捕获这些食物。"
),
]
fromllama_index.packs.corrective_ragimportCorrectiveRAGPack
corrective_rag=CorrectiveRAGPack(documents,"YOUR_TAVILYAI_API_KEY")
#从这里开始,您可以使用该包,或在 ./corrective_rag_pack 中检查和修改该包。
# run()函数包含纠正性检索增强生成- CRAG 论文背后的逻辑。
query="最小的企鹅有多高?"
print('-'*100)
print("查询"+query+"的响应是:")
response=corrective_rag.run(query,similarity_top_k=2)
print(response)
首先,您需要申请一个 TavilyAI 的 API 密钥 (YOUR_TAVILYAI_API_KEY) 并将其填入代码中。TavilyAI 提供了用于信息检索和知识提取的 API 接口,可以通过这个网站(https://app.tavily.com/sign-in)申请。 测试代码产生了以下结果(大部分调试信息已被移除): (crag)$python/Users/dream/Documents/crag.py
----------------------------------------------------------------------------------------------------
TheresponseofthequeryHowtallisthesmallestpenguins?is:
----------------------------------------------------------------------------------------------------
Thesmallestpenguinsareabout40cm(16inches)tall.
理解测试代码的关键在于 corrective_rag.run() 的实现,让我们深入探讨。 4.3、CorrectiveRAGPack 类的构造器
要理解 CRAG 的工作原理,我们需要深入研究 corrective_rag.run() 函数的代码。这个函数实现了 CRAG 的核心逻辑,包括信息检索、相关性评估、信息提取等步骤。 classCorrectiveRAGPack(BaseLlamaPack):
def__init__(self,documents ist[Document],tavily_ai_apikey:str)->None: ist[Document],tavily_ai_apikey:str)->None:
"""Initparams."""
llm=OpenAI(model="gpt-4")
self.relevancy_pipeline=QueryPipeline(
chain=[DEFAULT_RELEVANCY_PROMPT_TEMPLATE,llm]
)
self.transform_query_pipeline=QueryPipeline(
chain=[DEFAULT_TRANSFORM_QUERY_TEMPLATE,llm]
)
self.llm=llm
self.index=VectorStoreIndex.from_documents(documents)
self.tavily_tool=TavilyToolSpec(api_key=tavily_ai_apikey)
请注意,默认设置是 gpt-4。如果您没有使用 gpt-4 的权限,您可以手动切换到 gpt-3.5-turbo。 4.4、class CorrectiveRAGPack:: run()
函数 run() 的源代码如下: classCorrectiveRAGPack(BaseLlamaPack):
...
...
defrun(self,query_str:str,**kwargs:Any)->Any:
"""Runthepipeline."""
#根据输入的查询字符串检索节点。
retrieved_nodes=self.retrieve_nodes(query_str,**kwargs)
#评估检索到的每个文档与查询字符串的相关性。
relevancy_results=self.evaluate_relevancy(retrieved_nodes,query_str)
#从评估为相关的文档中提取文本。
relevant_text=self.extract_relevant_texts(retrieved_nodes,relevancy_results)
#初始化 search_text 变量以处理可能未定义的情况。
search_text=""
#如果发现任何文档不相关,转换查询字符串以获得更好的搜索结果。
if"no"inrelevancy_results:
transformed_query_str=self.transform_query_pipeline.run(
query_str=query_str
).message.content
#使用转换后的查询字符串进行搜索并收集结果。
search_text=self.search_with_transformed_query(transformed_query_str)
#编译最终结果。如果有来自转换查询的额外搜索文本,
#则包含在内;否则,只返回初始检索的相关文本。
ifsearch_text:
returnself.get_result(relevant_text,search_text,query_str)
else:
returnself.get_result(relevant_text,"",query_str)
LlamaIndex的CRAG实现与标准CRAG流程有一些区别: 没有处理模棱两可的信息: LlamaIndex 的实现没有对模棱两可的信息进行判断和处理,而是直接将其与相关信息一起传递给大语言模型。 使用大语言模型评估相关性: LlamaIndex 使用大语言模型 (例如 GPT-3.5) 来评估检索到的信息与问题的相关性,而不是使用训练好的 T5-large 模型。这是因为大语言模型具有更强的理解和推理能力,可以更准确地判断信息的相关性。 跳过知识精炼的过程: LlamaIndex 跳过了知识精炼的步骤,直接将提取的相关信息传递给大语言模型进行答案生成。这是因为大语言模型本身就具备一定的知识整合和信息处理能力,可以将相关信息组织成连贯的答案。
LlamaIndex 的 CRAG 实现提供了一种更简洁、更高效的信息检索和答案生成方式,利用了大语言模型的强大能力,避免了复杂的知识细化过程。 代码如下: classCorrectiveRAGPack(BaseLlamaPack):
...
...
defevaluate_relevancy(
self,retrieved_nodesist[Document],query_str:str
)->List[str]:
"""评估检索到的文档与查询的相关性。"""
relevancy_results=[]
fornodeinretrieved_nodes:
relevancy=self.relevancy_pipeline.run(
context_str=node.text,query_str=query_str
)
relevancy_results.append(relevancy.message.content.lower().strip())
returnrelevancy_results
调用LLM的提示如下: DEFAULT_RELEVANCY_PROMPT_TEMPLATE=PromptTemplate(
template="""作为评分员,您的任务是评估检索到的文档对用户问题的回答的相关性。
检索到的文档:
-------------------
{context_str}
用户问题:
--------------
{query_str}
评估标准:
-考虑文档是否包含与用户问题相关的关键词或主题。
-评估不应过于严格;主要目标是识别并过滤掉明显不相关的检索。
决定:
-分配一个二进制分数来表示文档的相关性。
-如果文档与问题相关,请使用'yes';如果无关,请使用'no'。
请在下方提供您的二进制分数('yes'或'no'),以指示文档对用户问题的相关性。"""
)
CRAG 论文指出,ChatGPT 在判断信息与问题之间相关性的能力方面,不如 T5-Large 模型。 此外,在实际应用中,我们可以使用 CRAG 论文中提出的知识精炼算法来进一步提升结果的准确性。相关的代码实现可以在 CRAG 的开源项目中找到。 如前所述,CRAG 在进行网络搜索时,并不会直接使用用户输入的问题作为搜索关键词。相反,它会利用 GPT-3.5 模型来生成更有效的搜索查询。CRAG 会向 GPT-3.5 提供以下提示: DEFAULT_TRANSFORM_QUERY_TEMPLATE=PromptTemplate(
template=""“你的任务是优化一个查询,以确保它能够高效地检索到相关的搜索结果。\n
请分析给定的查询以抓住其核心语义或意图。\n
原始查询:
\n-------\n
{query_str}
\n-------\n
目标是改进这个查询,以提升其搜索效果。确保修改后的查询既精确又简洁。\n
请仅回复优化后的查询:”""
)
这段提示告诉 GPT-3.5,它的任务是将原始问题改写成一个更有效的搜索查询,以便检索到更相关的结果。
self-RAG 是另一种检索增强生成方法,它与 CRAG 有以下区别: 工作流程: self-RAG 可以直接使用大语言模型生成答案,而无需进行信息检索。而 CRAG 需要先检索相关信息,然后进行评估和筛选,最后才生成答案。 模型结构: self-RAG 的模型结构比 CRAG 更复杂,需要进行更复杂的训练过程,并在生成答案时进行多标签生成和评估。这导致 self-RAG 的推理成本更高,效率更低。而 CRAG 的模型结构更轻量级,推理速度更快。 性能表现: 根据图 5 所示的实验结果,CRAG 在大多数情况下都优于self-RAG,能够生成更准确、更相关的答案。
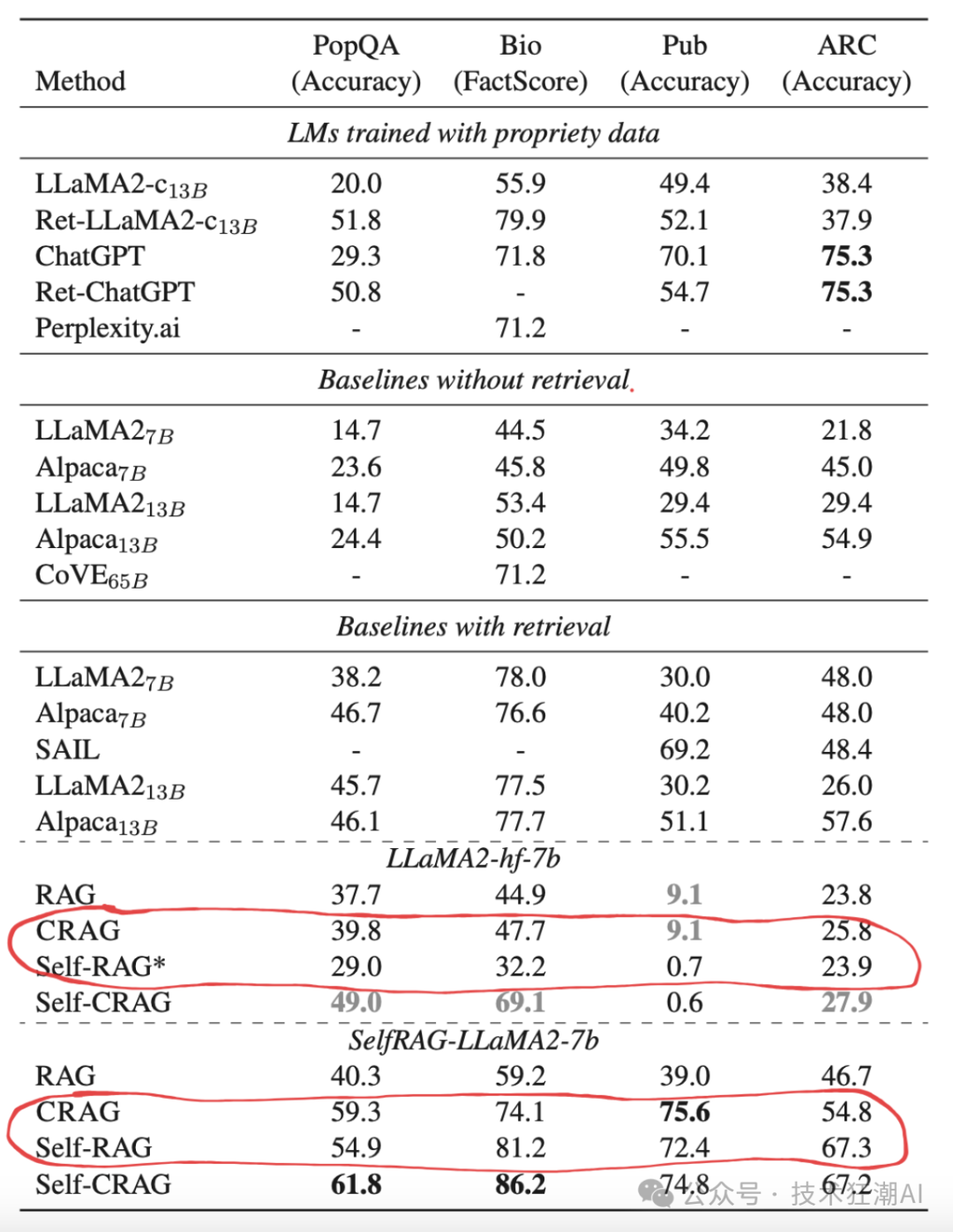
图 5: ( Figure 5: ) 四个数据集测试集上的总体评估结果。结果根据不同的 LLM 进行区分展示。加粗的数字表示所有方法和大语言模型中的最佳性能。灰色加粗的分数表示使用特定大语言模型的最佳性能。带 * 号的结果是由 CRAG 复现的,其他结果则引用自它们各自的原始论文。来源:校正检索增强生成。 总的来说,CRAG 和 self-RAG 各有优缺点。self-RAG 更适合那些对信息检索速度要求较高,且对答案准确性要求不太高的场景。而 CRAG 更适合那些对答案准确性要求较高,且对信息检索速度要求不太高的场景。 检索评估器可以理解为一个对信息进行打分和分类的模型。它的作用类似于 RAG 中的重新排序模型,用于判断检索到的信息与问题之间的相关性。 为了让检索评估器更准确地判断信息的相关性,我们可以引入更多与实际应用场景相关的特征。例如,在科学论文问答领域,检索到的信息通常包含很多专业术语,而在旅游领域的 RAG 应用中,用户的查询往往更加口语化。 通过在检索评估器的训练集中加入场景特定的特征,可以让检索评估器更好地理解不同领域的信息特点,模型能更准确地评估检索文档的相关性。此外,我们还可以添加其他特征,例如用户的搜索意图、编辑距离等,如图 6 所示: 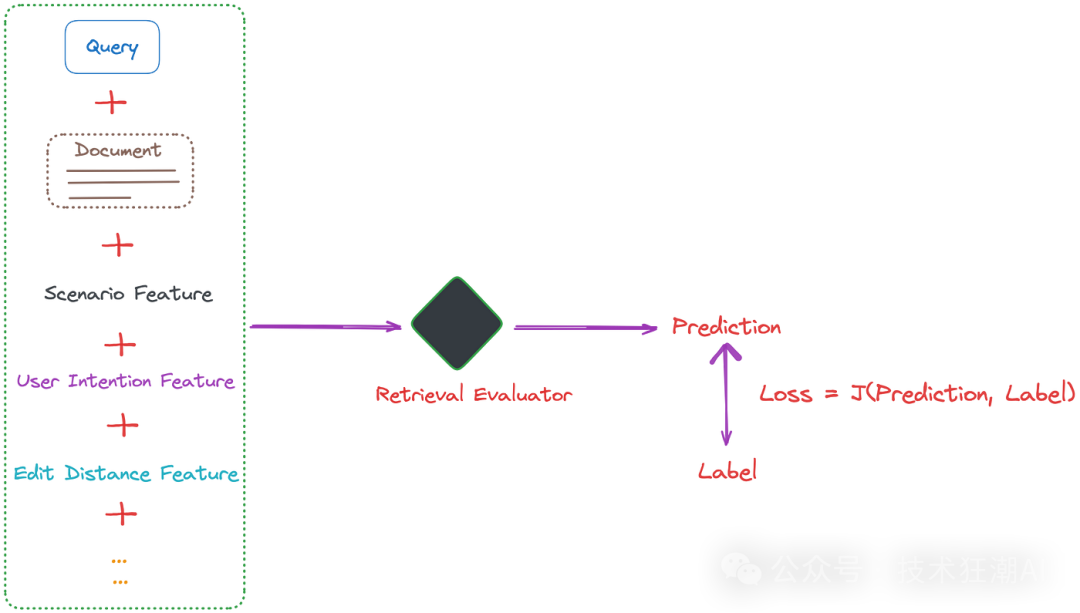
图 6: ( Figure 6: ) 通过整合额外的特征,改进 CRAG 中检索评估器的训练。图片由作者提供。 值得一提的是,轻量级的模型 (例如 T5-large) 也能够取得不错的效果,这使得 CRAG 可以在资源有限的小型团队或公司中得到应用。 前面提到过,相关性分数的阈值会根据不同的数据类型而有所不同。根据实验结果,我们可以发现,模棱两可和不相关的阈值通常在 -0.9 左右,这表明大部分检索到的信息都与问题有一定的相关性。因此,完全丢弃这些信息并完全依赖网络搜索可能不是明智之举。 在实际应用中,我们需要根据具体的问题和需求来调整阈值,以便在信息检索的准确性和全面性之间取得平衡。
本文从一个比较直观的例子出发,介绍了 CRAG 的工作原理和关键技术,并通过代码实例展示了如何使用 CRAG 进行信息检索和答案生成。 CRAG 作为一个即插即用的插件,可以显著提升检索增强生成 (RAG) 的性能,并提供了一个轻量级的解决方案来优化信息检索的质量。 | 









