|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 0px 8px 2em;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">这两天看了不少关于AI大模型应用中长短时记忆的实现方法。突然想到,一直在学习和使用的MetaGPT(开源AI Agent多智能框架),我竟然没有注意过它里面的关于记忆的实现方法。今天,补上这一课,深入其源码,看它的 Memory 模块是如何实现的。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">0. 关于大模型记忆的前期文章ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">感兴趣的可以看下我前面的几篇关于大模型记忆的文章,废了点功夫从网上搜集了目前比较常用和前沿的长短时记忆的实现方法:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">1. 先用起来 - 使用 MemoryingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 2em 8px;">在MetaGPT中,Memory类是智能体的记忆的抽象。当初始化时,Role初始化一个Memory对象作为self.rc.memory属性,它将在之后的_observe中存储每个Message,以便后续的检索。简而言之,Role的记忆是一个含有Message的列表。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">我们前面学习MetaGPT的系列文章中其实每次都在用这个Message。例如这篇文章中的代码:【AI Agent系列】【MetaGPT多智能体学习】3. 开发一个简单的多智能体系统,兼看MetaGPT多智能体运行机制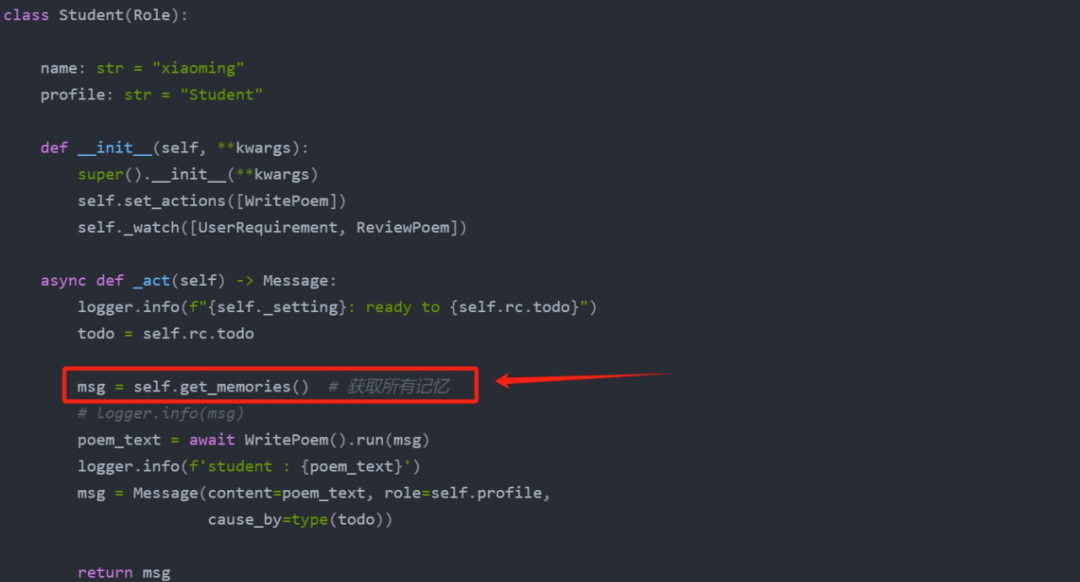
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">get_memories函数就是用来获取记忆的。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 2em 8px;">你可以通过前面MetaGPT系列文章中的任一个Demo代码去体验这个函数的使用。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">2. 再深入看源码2.1 Memory模块总览下图是 MetaGPT 中 Memory 部分的代码文件: 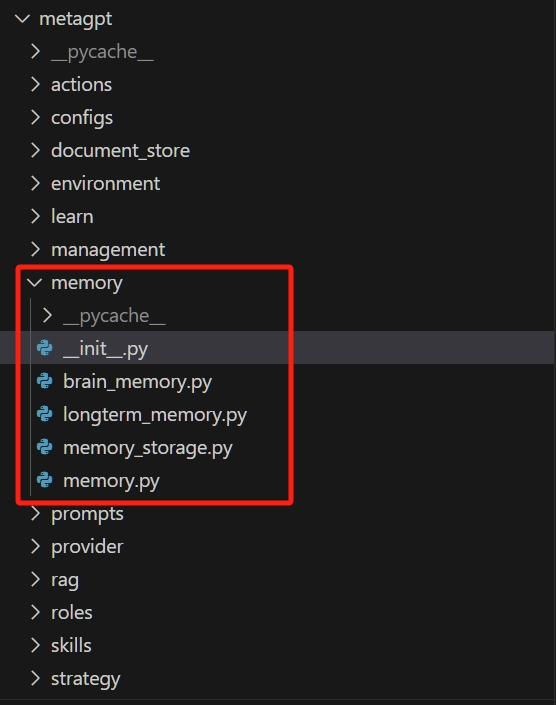
memory.py 是基础的 memory 基类,也是最常用的 Memory 类型。longterm_memory.py 是长时记忆的实现。memory_storage.py 是辅助 longterm_memory.py 来进行记忆的持久化存储和查询的类。brain_memory.py 看描述是具有长时记忆和记忆压缩能力,但是并没有看到应用的地方。 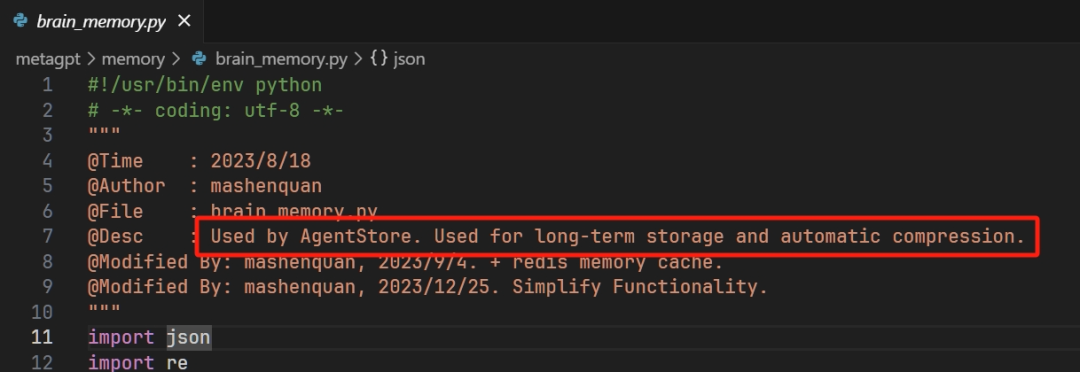
2.2 基础记忆这部分功能在 memory.py 文件中,这是记忆模块的基类。 classMemory(BaseModel):
"""Themostbasicmemory:super-memory"""
storage:list[SerializeAsAny[Message]]=[]
index efaultDict[str,list[SerializeAsAny[Message]]]=Field(default_factory=lambda:defaultdict(list)) efaultDict[str,list[SerializeAsAny[Message]]]=Field(default_factory=lambda:defaultdict(list))
ignore_id:bool=False
其 storage 是一个 list 列表,所以是保存在内存中的,关机、重启之后,记忆消失,无法持久化存储。 2.2.1 接口说明(1)add:往记忆中添加一条记忆 实现中,还增加了self.index[message.cause_by].append(message)的处理,让使用者可以通过message.cause_by参数快速获取指定动作的记忆。 defadd(self,message:Message):
"""Addanewmessagetostorage,whileupdatingtheindex"""
ifself.ignore_id:
message.id=IGNORED_MESSAGE_ID
ifmessageinself.storage:
return
self.storage.append(message)
ifmessage.cause_by:
self.index[message.cause_by].append(message)
(2)add_batch:添加一系列消息 (3)get_by_role:返回指定Role的记忆,判定条件message.role == role (4)get_by_content:查找带有 content 的记忆,类似关键字检索?判定条件content in message.content (5)delete_newest:删除最新的一条记忆 (6)delete:删除指定的一条记忆 (7)clear:清空记忆 (8)count:记忆数量 (9)try_remember:查找带有 keyword 的记忆,与get_by_content有点重复?keyword in message.content (10)get:获取最近的K条记忆,K=0时返回全部的记忆 (11)find_news:找出想观察但上次没观察到的消息?没想象出怎么使用,给大家看下源码理解一下吧: deffind_news(self,observed:list[Message],k=0)->list[Message]:
"""findnews(previouslyunseenmessages)fromthethemostrecentkmemories,fromallmemorieswhenk=0"""
already_observed=self.get(k)
news:list[Message]=[]
foriinobserved:
ifiinalready_observed:
continue
news.append(i)
returnnews
(12)get_by_action 、 get_by_actions:返回指定动作产生的记忆 2.3 longterm_memory.py长时记忆的实现,启动时恢复记忆,变化时更新记忆。 classLongTermMemory(Memory):
"""
TheLong-termmemoryforRoles
-recovermemorywhenitstaruped
-updatememorywhenitchanged
"""
model_config=ConfigDict(arbitrary_types_allowed=True)
memory_storage:MemoryStorage=Field(default_factory=MemoryStorage)
rc:Optional[RoleContext]=None
msg_from_recover:bool=False
2.3.1 接口说明(1)add:添加一条记忆 defadd(self,message:Message):
super().add(message)
foractioninself.rc.watch:
ifmessage.cause_by==actionandnotself.msg_from_recover:
#currently,onlyaddrole'swatchingmessagestoitsmemory_storage
#andignoreaddingmessagesfromrecoverrepeatedly
self.memory_storage.add(message)
首先是调用super也就是基础Memory的add接口,添加记忆到内存中。 然后通过self.memory_storage.add(message)保存记忆。memory_storage的add接口,是调用 FAISS 向量数据库去进行向量化和存储。 defadd(self,message:Message)->bool:
"""addmessageintomemorystorage"""
self.faiss_engine.add_objs([message])
logger.info(f"Role{self.role_id}'smemory_storageaddamessage")
(2)recover_memory:恢复记忆 defrecover_memory(self,role_id:str,rc:RoleContext):
self.memory_storage.recover_memory(role_id)
self.rc=rc
ifnotself.memory_storage.is_initialized:
logger.warning(f"ItmaythefirsttimetorunRole{role_id},thelong-termmemoryisempty")
else:
logger.warning(f"Role{role_id}hasexistingmemorystorageandhasrecoveredthem.")
self.msg_from_recover=True
#self.add_batch(messages)#TODOnoneed
self.msg_from_recover=False
通过memory_storage来recover_memory,最终也是通过 FAISS 数据库进行记忆查询: defrecover_memory(self,role_id:str)->list[Message]:
self.role_id=role_id
self.role_mem_path=Path(DATA_PATH/f"role_mem/{self.role_id}/")
self.role_mem_path.mkdir(parents=True,exist_ok=True)
self.cache_dir=self.role_mem_path
ifself.role_mem_path.joinpath("default__vector_store.json").exists():
self.faiss_engine=SimpleEngine.from_index(
index_config=FAISSIndexConfig(persist_path=self.cache_dir),
retriever_configs=[FAISSRetrieverConfig()],
embed_model=self.embedding,
)
else:
self.faiss_engine=SimpleEngine.from_objs(
objs=[],retriever_configs=[FAISSRetrieverConfig()],embed_model=self.embedding
)
self._initialized=True
这里恢复的是指定Role的记忆,通过self.role_id来区分。 (3)find_news 与基础Memory不同的是,它首先在基础Memory中找,然后在 long-term memory 中找,将两者的结果结合作为最终结果返回。 asyncdeffind_news(self,observed:list[Message],k=0)->list[Message]:
"""
findnews(previouslyunseenmessages)fromthethemostrecentkmemories,fromallmemorieswhenk=0
1.findtheshort-termmemory(stm)news
2.furthermore,filteroutsimilarmessagesbasedonltm(long-termmemory),getthefinalnews
"""
stm_news=super().find_news(observed,k=k)#shot-termmemorynews
ifnotself.memory_storage.is_initialized:
#memory_storagehasn'tinitialized,usedefault`find_news`togetstm_news
returnstm_news
ltm_news:list[Message]=[]
formeminstm_news:
#filteroutmessagessimilartothoseseenpreviouslyinltm,onlykeepfreshnews
mem_searched=awaitself.memory_storage.search_similar(mem)
iflen(mem_searched)==0:
ltm_news.append(mem)
returnltm_news[-k:]
(4)persist 将数据持久化存储。 defpersist(self):
ifself.faiss_engine:
self.faiss_engine.retriever._index.storage_context.persist(self.cache_dir)
2.4 brain_memory.pyclassBrainMemory(BaseModel):
history ist[Message]=Field(default_factory=list) ist[Message]=Field(default_factory=list)
knowledgeist[Message]=Field(default_factory=list)
historical_summary:str=""
last_history_id:str=""
is_dirty:bool=False
last_talk:Optional[str]=None
cacheable:bool=True
llm:Optional[BaseLLM]=Field(default=None,exclude=True)
这个Memory没太搞清楚具体是干啥的,但是看到里面是用Redis存储的,并且里面有summary信息的步骤,可以学习一下这种记忆思路。 看源码,它是将历史对话信息用大模型进行总结,然后存储到Redis里面。 asyncdefsummarize(self,llm,max_words=200,keep_language:bool=False,limit:int=-1,**kwargs):
ifisinstance(llm,MetaGPTLLM):
returnawaitself._metagpt_summarize(max_words=max_words)
self.llm=llm
returnawaitself._openai_summarize(llm=llm,max_words=max_words,keep_language=keep_language,limit=limit)
asyncdef_openai_summarize(self,llm,max_words=200,keep_language:bool=False,limit:int=-1):
texts=[self.historical_summary]
forminself.history:
texts.append(m.content)
text="\n".join(texts)
text_length=len(text)
iflimit>0andtext_length<limit:
returntext
summary=awaitself._summarize(text=text,max_words=max_words,keep_language=keep_language,limit=limit)
ifsummary:
awaitself.set_history_summary(history_summary=summary,redis_key=config.redis_key)
returnsummary
raiseValueError(f"texttoolong:{text_length}")
它上面还有一层函数 get_title,又将上面Summary的信息抽出了一个标题: asyncdefget_title(self,llm,max_words=5,**kwargs)->str:
"""Generatetexttitle"""
ifisinstance(llm,MetaGPTLLM):
returnself.history[0].contentifself.historyelse"New"
summary=awaitself.summarize(llm=llm,max_words=500)
language=config.language
command=f"Translatetheabovesummaryintoa{language}titleoflessthan{max_words}words."
summaries=[summary,command]
msg="\n".join(summaries)
logger.debug(f"titleask:{msg}")
response=awaitllm.aask(msg=msg,system_msgs=[],stream=False)
logger.debug(f"titlersp:{response}")
returnresponse
这是不是算分层存储了? 3. 总结总得看下来,MetaGPT的记忆模块其实实现的很简单,主要是在短时记忆上面进行了实现。对于长时记忆,只是简单的实现了将其存入了向量数据库,可以选择持久化的基础能力。对于长上下文这种的记忆能力,并没有特别实现。感觉longterm_memory并没有写完的样子,没看到实际使用。其brain_memory是第一次见,也没看到实际使用,但里面的对历史对话进行总结存储,对总结内容再进行标题化存储的方法值得借鉴。 参考1.https://docs.deepwisdom.ai/main/zh/guide/tutorials/use_memories.html 2.https://github.com/geekan/MetaGPT
|










