|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.578px;color: rgb(172, 57, 255);visibility: visible;">注意力计算Q、K、V ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;text-indent: 0em;font-size: var(--articleFontsize);visibility: visible;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;visibility: visible;">Transformer的起源:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.578px;caret-color: rgba(0, 0, 0, 0.9);background-color: rgb(253, 253, 254);color: rgb(255, 76, 65);visibility: visible;">Google Brain 翻译团队通过论文《Attention is all you need》提出了一种全新的简单网络架构—ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.578px;caret-color: rgba(0, 0, 0, 0.9);background-color: rgb(253, 253, 254);color: rgb(255, 76, 65);visibility: visible;">—ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.578px;background-color: rgb(255, 255, 255);">Transformer,它完全基于注意力机制,摒弃了循环和卷积操作。  ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: center;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;">注意力机制是全部所需 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);text-align: center;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;">注意力机制是全部所需ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);">正如论文标题所言“注意力机制是全部所需”,强调了注意力机制是Transformer架构的核心要素,就如同人的心脏一样,充当着发动机的作用。 注意力计算Q、K、V 神经网络算法 - 一文搞懂Transformer
神经网络算法 - 一文搞懂 Transformer(总体架构 & 三种注意力层) 神经网络算法 - 一文搞懂Transformer中的三种注意力机制
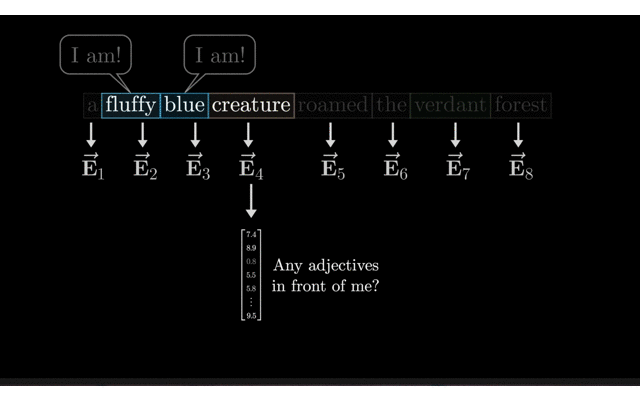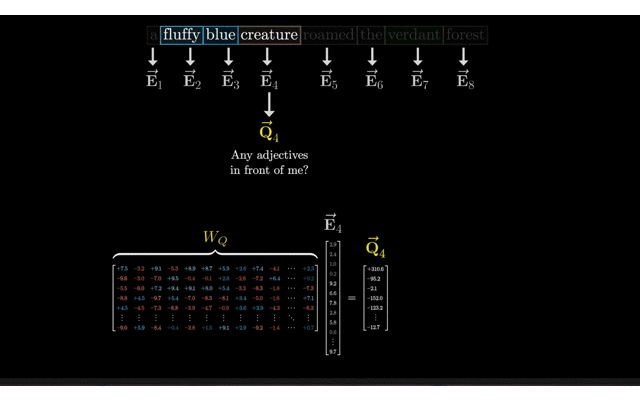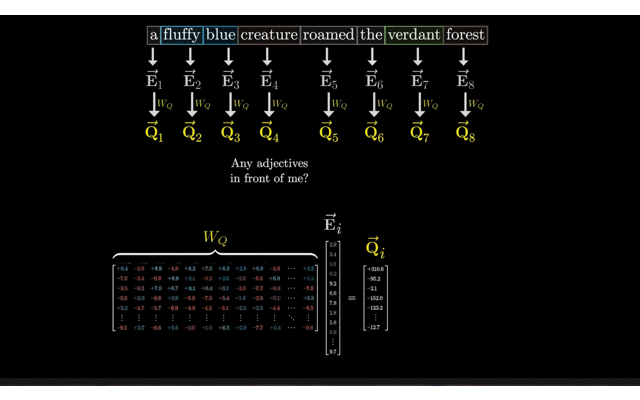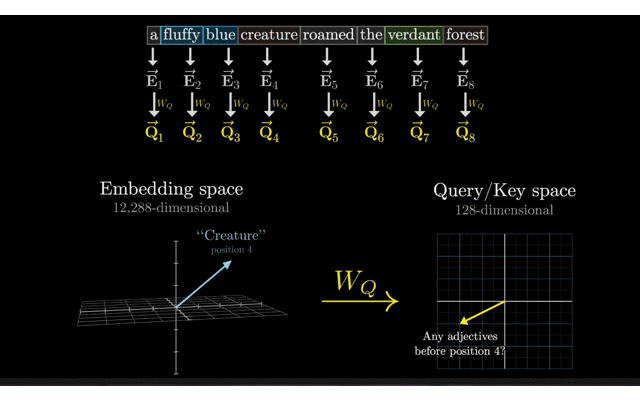
注意力计算Q、K、V:在注意力机制中,Q(Query)、K(Key)、V(Value)通过映射矩阵得到相应的向量,通过计算Q与K的点积相似度并经过softmax归一化得到权重,最后使用这些权重对V进行加权求和得到输出。权重矩阵W:W_Q、W_K和W_V
权重矩阵W_Q计算Query(Q):在Transformer模型中,Query(Q)是通过将输入数据的嵌入矩阵E与权重矩阵W_Q相乘得到的。
- 在Transformer模型中,权重矩阵W是用于将输入数据(如词嵌入)映射到Q、K、V(Query、Key、Value)向量的线性变换矩阵。对于Query(Q),有一个专门的权重矩阵W_Q。
- W_Q的维度通常是(d_model, d_k),其中d_model是输入嵌入的维度(也是模型的维度),而d_k是Q/K/V向量的维度。假设d_k被设定为128。
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Query矩阵Q是通过将X与权重矩阵W_Q相乘得到的。 具体地,对于Q中的每一个嵌入向量q_i(形状为(d_model)),Q中的一个向量q_i可以通过q_i = e_i * W_Q计算得到。 因此,整个Query矩阵Q(形状为(batch_size, sequence_length, d_k))可以通过E * W_Q计算得到。
计算Q(Query) 权重矩阵W_K计算Key(K):在Transformer模型中,Key(K)是通过将输入数据的嵌入矩阵E与权重矩阵W_K相乘得到的。
在Transformer模型中,权重矩阵W_K也是一个可训练的权重矩阵,用于将输入数据的嵌入映射到Key向量(K)。 W_K的维度通常是(d_model, d_k),其中d_model是输入嵌入的维度(也是Transformer模型的维度),d_k是Key向量的维度。假设d_k被设定为128。
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Key矩阵K是通过将E与权重矩阵W_K相乘得到的。 具体地,对于K中的每一个嵌入向量k_i(形状为(d_model)),K中的一个向量k_i可以通过k_i = e_i * W_K计算得到。 因此,整个Key矩阵K(形状为(batch_size, sequence_length, d_k))可以通过X * W_K计算得到。
计算K(Key) 权重矩阵W_V计算Value(V):在Transformer模型中,Value(V)是通过将输入数据的嵌入矩阵E与权重矩阵W_V相乘得到的。
在Transformer模型中,权重矩阵W_V也是一个可训练的权重矩阵,用于将输入数据的嵌入映射到Value向量(V)。 W_V的维度通常是(d_model, d_v),其中d_model是输入嵌入的维度(也是Transformer模型的维度),d_v是Value向量的维度。假设d_k被设定为128。
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Value矩阵V是通过将E与权重矩阵W_V相乘得到的。 具体地,对于E中的每一个嵌入向量e_i(形状为(d_model)),V中的一个向量v_i可以通过v_i = e_i * W_V计算得到。 因此,整个Value矩阵V(形状为(batch_size, sequence_length, d_v))可以通过E * W_V计算得到。
计算V(Value) Q、K、V计算:Q用于查询,K用于匹配,V提供被加权的信息。通过计算Q和K的点积来衡量注意力分数,进而决定V的加权方式。Q(query)、K(Key)、V(Value)计算 |










