著名的检索增强生成应用kimi,估值已经达到了180亿美元。
现在,你也有机会手搓一个属于自己的kimi啦! KIMI走的是检索增强生成路线,简称RAG:Retrieval Augmented Generation,它就是把信息检索与大模型结合,以缓解大模型推理“幻觉”的问题。 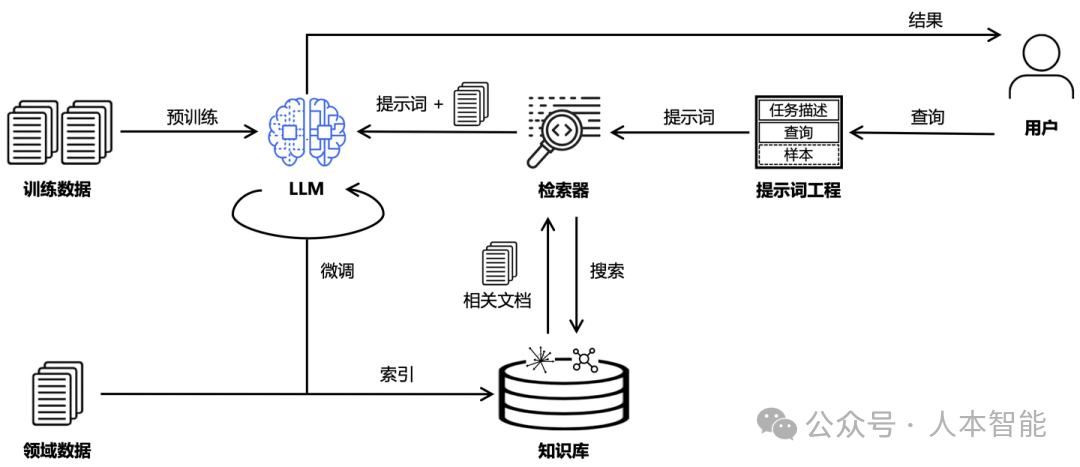
RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。更进一步地,RAG的整体链路还可以与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)等技术结合,构成更广义的RAG问答链路。
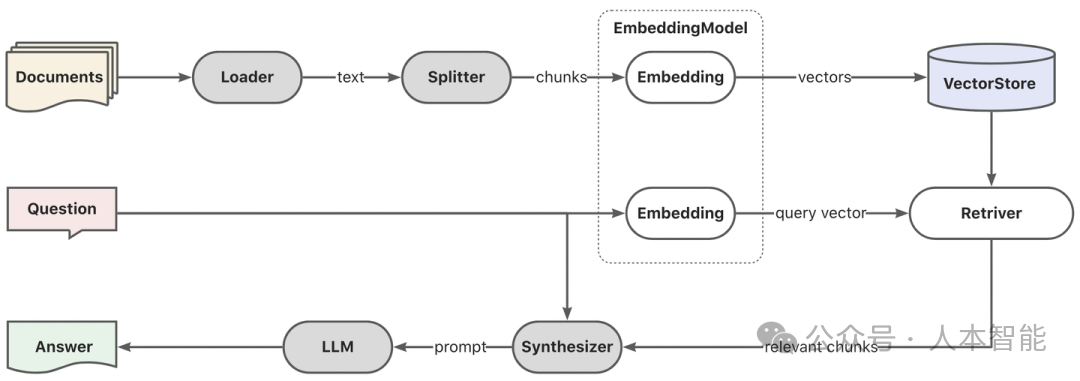
知识库内容缺失,截断有用文档,上下文整合丢失,有用信息未识别,提示词格式问题,准确性不足,答案不完整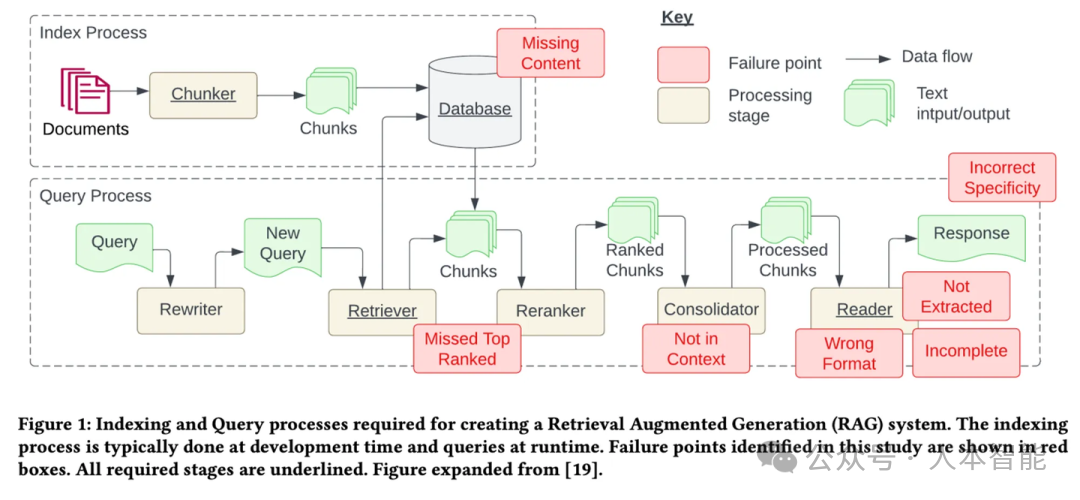 比如,最经典的RAG架构,首先是索引,就是向量嵌入,然后是检索,进行相似查询,最后是生成文档上下文 除了传统意义上的增强内容生成,RAG的理念还可以做很多事情,比如:增强训练,增强微调,增强语料,增强知识,增强检索,增强推理类似地,Graph RAG的核心链路也分如下三个阶段:第一是索引,通过LLM服务实现文档的三元组提取,写入图数据库。第二是检索:通过LLM服务实现查询的关键词提取和泛化(大小写、别称、同义词等),并基于关键词实现子图遍历(DFS/BFS),搜索N跳以内的局部子图。第三是生成:将局部子图数据格式化为文本,作为上下文和问题一起提交给大模型处理。开源的AI工程框架有诸多选型:LangChain、LlamaIndex、RAGFlow、DB-GPT等。知识图谱系统有:Jena、RDF4J、Oxigraph、OpenSPG等。图存储系统有Neo4j、JanusGraph、NebulaGraph、TuGraph等。而作为蚂蚁首个对外开源的Graph RAG框架所有环节均采用蚂蚁全自主的开源产品:DB-GPT + OpenSPG + TuGraph。一个可以支持RAG的AI工程框架,一个知识图谱系统和一个图存储系统。 有兴趣的小伙伴,快去看一下吧!
| 









