在学习大模型训练和部署的过程中,很多人都是按照网络上的教程进行学习;但这些教程大部分只讲了浅显的东西,还有很多问题没有讲明白。
比较明显的两个问题就是,大模型的规模问题和大模型的适配问题。
规模问题
学习和企业级应用是有着巨大差别的,比如说学习大模型的过程中,只需要设计一个几十个参数的大模型即可了解大模型的设计,训练和使用原理。
但在真正的企业级应用中,大模型的参数少则几个亿,多则几十,几百,甚至几万亿的参数量。

在这种企业级应用中,如果大规模的参数怎么保存,怎么加载;单机硬件资源有限的情况下,怎么进行分布式训练和分布式部署。
以openAI的chatGPT来说,最新版的gpt4o预估有一千七百多亿个参数,后续的gpt5等更高等级的版本中,参数量可能会更多。
而如此规模的大模型,要在一台机器上进行训练和推理几乎是不可能的,哪怕是超级计算机也会很吃力。
而在之前的学习过程中,基本上都是从pytorch或huggingface或者github上下载一些开源的大模型。
而这些大模型主要是用来学习的,因此参数量规模较小,个人电脑就可以跑的起来。
个人开发的一个人工智能聊天机器人小程序,感兴趣的可以点击查看:
但在真正的企业级环境中,哪怕可以使用个人电脑或者服务器进行训练和推理;但当企业用户规模达到一定程度之后,如果不进行分布式或集群部署,是绝对不行的。
大模型的适配问题
比如说我们使用ollama或者其它的框架,在本地部署大模型,我们知道在学习的过程中都是直接从网络上下载别人弄好的大模型。
假如说,需要你自己设计或者从网上找一个开源的大模型进行训练之后,怎么才能把这个模型适配到ollama框架中,也就是说要把大模型转化为ollama要求的格式。
比如说,使用llama.cpp项目进行大模型的适配具体应该怎么做?
大模型企业级方案
在前一节中说,大模型个人使用和企业级应用是完全两回事,不论是从参数量还是访问规模上都不可同日而语。
企业级大模型需要解决以下几个问题:
可以单机部署的小模型怎么解决大规模用户访问?
举个例子,企业中有一个几个亿参数的小模型,但企业却有几个亿的用户需要使用它,应该怎么办?
这时,一种方案是把小模型进行集群部署,比如说用一百台或者一千台机群分别部署同样的小模型,然后采用负载均衡的方式进行访问。
其次,如果有一个几千亿参数的大模型,单机无法支持的情况下应该怎么训练和部署?
这种方式只能采用分布式部署或者分布式+集群的方式进行部署;比如把一个模型按照功能逻辑拆分成几个模块,然后在不同的机器上进行训练和推理;最后用并行计算的方式对外提供服务。
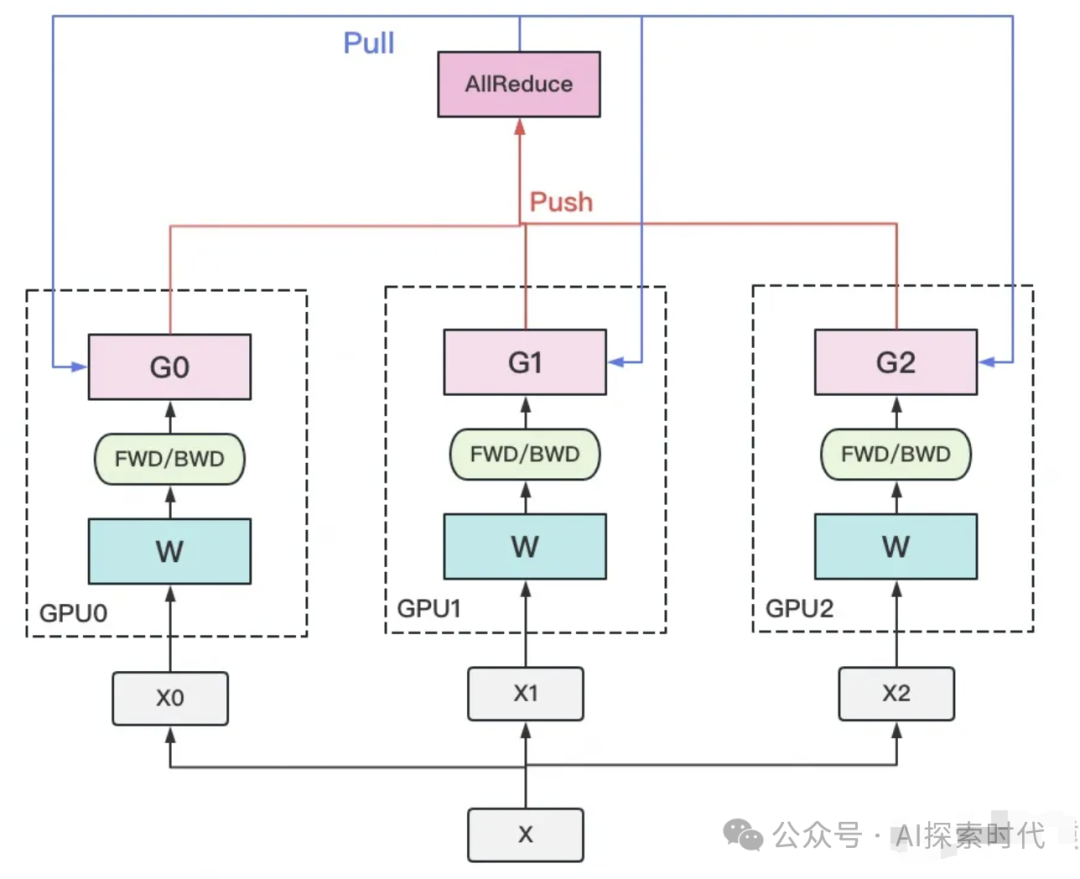
关于大模型分布式训练和推理的三大并行方式:
数据并行(Data Parallelism):
将模型复制到多台机器上,并在每台机器上使用不同的训练数据进行训练。
每台机器计算出梯度后,将这些梯度聚合到一起并更新模型参数。
常用的工具包括TensorFlow的分布式策略、PyTorch的分布式数据并行等。
模型并行(Model Parallelism):
流水线并行(Pipeline Parallelism):
混合并行(Hybrid Parallelism):
最后一种并行方式属于把前面三种方式的结合,算不上是一种新的方式。
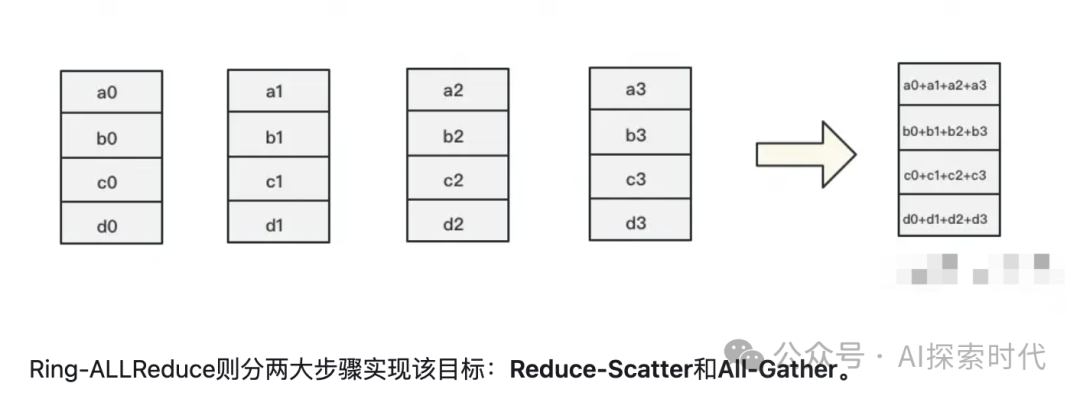
常见的一些技术框架:
实现分布式部署的一些工具和框架:
TensorFlow:提供了多种分布式策略,如tf.distribute.MirroredStrategy(数据并行)和tf.distribute.TPUStrategy(TPU上的数据并行)。
PyTorch:提供了torch.distributed包,支持数据并行和模型并行。
Horovod:一个开源库,最初由Uber开发,支持TensorFlow、Keras、PyTorch等的分布式训练,简化了多GPU和多机器训练的实现。
DeepSpeed:微软开源的一个深度学习优化库,支持大规模模型的分布式训练和推理。
这篇文章只是简单介绍和说明一下大模型训练和部署中可能出现的问题,以及企业级应用中的解决方案,由于个人也在学习的过程中,所以有些东西讲的有点乱,也不是很明白。










