ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.1em;visibility: visible;">如果你已经探索过使用 Neo4j 来实现 GraphRAG,你可能已经了解它在提升生成模型输出质量方面的潜力。传统上,这需要深入掌握 Neo4j 和 Cypher(Neo4j 的查询语言)。在本文中,您可以了解到一种更简单的方式,简化 Neo4j 与检索增强生成(RAG)应用的集成,使开发者更容易使用,那就是:适用于 Python 的官方 Neo4j GraphRAG 包(ingFang SC"; letter-spacing: 0.1em;">neo4j-graphrag)!
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">neo4j-graphrag:https://pypi.org/project/neo4j-graphrag/ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">该 Python 包为您提供了管理 RAG 过程中的检索与生成任务的高效工具。本文将展示如何使用该包执行检索任务。接下来的文章将介绍其生成功能,帮助您构建完整的端到端 RAG 流程。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(1, 155, 252);color: rgb(255, 255, 255);">什么是 GraphRAG?ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">neo4j-graphrag 包简化了图检索增强生成(GraphRAG)。在 Neo4j,我们相信将图数据库与向量搜索结合起来代表了 RAG 的下一步发展方向。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(1, 155, 252);color: rgb(255, 255, 255);">安装设置ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">首先,连接到一个预配置的 Neo4j 演示数据库,该数据库模拟了一个电影推荐知识图谱。您可以使用用户名和密码 "recommendations" 访问 https://demo.neo4jlabs.com:7473/browser/。这一设置提供了一个现实场景,向量嵌入数据已作为 Neo4j 数据库的一部分。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">使用 Cypher 命令可视化数据:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">MATCH(n)RETURNnLIMIT25;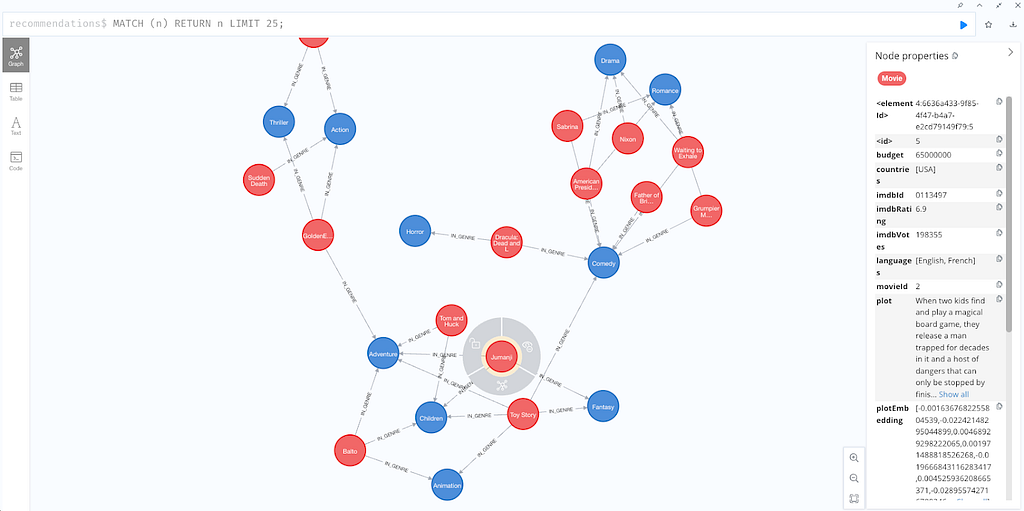
观察每个节点右侧详情中的plotEmbedding属性。我们将在演示中使用这些嵌入执行向量搜索。您可以通过以下 Cypher 命令检查是否存在moviePlotsEmbedding向量索引: SHOWINDEXESYIELD*WHEREtype='VECTOR'; 在您的 Python 环境中,安装 neo4j-graphrag 包及其他依赖包: pipinstallneo4j-graphragneo4jopenai 接着,使用 Neo4j Python 驱动程序连接到数据库: fromneo4jimportGraphDatabase
#演示数据库凭证
URI="neo4j+s://demo.neo4jlabs.com"
AUTH=("recommendations","recommendations")
#连接到Neo4j数据库
driver=GraphDatabase.driver(URI,auth=AUTH)
确保您已设置 OpenAI API 密钥: importos
os.environ["OPENAI_API_KEY"]="sk-..."
检索操作我们的包提供了适用于不同检索策略的多种检索器类(参见文档:https://neo4j.com/docs/neo4j-graphrag-python/current/)。在这里,我们使用VectorRetriever类: fromneo4j-graphrag.retrieversimportVectorRetriever
fromneo4j-graphrag.embeddings.openaiimportOpenAIEmbeddings
embedder=OpenAIEmbeddings(model="text-embedding-ada-002")
retriever=VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title","plot"],
)
我们使用text-embedding-ada-002模型,因为演示数据库中的电影情节嵌入是使用该模型生成的,从而使检索结果更加相关。您可以自定义返回的结果属性,这里我们指定了返回节点属性title和plot。 使用检索器搜索与查询最相关的电影情节,执行近似最近邻搜索以识别最佳匹配的前三个电影情节: query_text="AmovieaboutthefamoussinkingoftheTitanic"
retriever_result=retriever.search(query_text=query_text,top_k=3)
print(retriever_result)
结果可以进一步解析为: importre
fork,iteminenumerate(retriever_result.items):
plot=re.search(r"'plot':\s*'([^']*)'",item.content).group(1)
title=re.search(r"'title':\s*'([^']*)'",item.content).group(1)
score=item.metadata["score"]
print(f"Result{k}:{title}-{score}-{plot}")
GraphRAG让我们看看检索器如何集成到简单的 GraphRAG 流程中。要使用 neo4j-graphrag 包执行 GraphRAG 查询,需要以下几个组件: 1. 一个 Neo4j 驱动——用于查询 Neo4j 数据库。 2. 一个检索器——neo4j-graphrag 包提供了一些实现,并允许您编写自己的检索器。 3. 一个 LLM——我们需要调用一个 LLM 来生成答案。neo4j-graphrag 包目前仅提供 OpenAI 的 LLM 实现,但其接口与 LangChain 的聊天模型兼容,并允许您编写自己的接口。
实际操作只需几行代码: fromneo4j-graphrag.llmimportOpenAILLM
fromneo4j-graphrag.generationimportGraphRAG
#LLM
llm=OpenAILLM(model_name="gpt-4",model_params={"temperature":0})
#初始化RAG流程
rag=GraphRAG(retriever=retriever,llm=llm)
#查询图谱
query_text="Whatmoviesaresadromances?"
response=rag.search(query_text=query_text,retriever_config={"top_k":5})
print(response.answer)
|










