ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">多模态 RAG 与 GPT4Vision 和 LangChain是指一个框架,它结合了 GPT-4-Vision(OpenAI 的 GPT-4 的多模态版本,能够处理和生成文本、图像以及可能的其他数据类型)的能力与 LangChain,这是一个旨在促进使用语言模型构建应用程序的工具。以下是关键概念的分解:
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: start;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;" class="list-paddingleft-1">多模态 RAG(检索增强生成):
*多模态:这个术语指的是处理和生成多种类型数据的能力,例如文本、图像、音频等。GPT-4-Vision 是一个能够处理文本和视觉输入的多模态模型的例子。
*检索增强生成(RAG):RAG 是一种结合了基于检索模型(从数据库或知识库中获取相关信息)与基于生成模型(创建内容)的优点的技术。在 GPT-4-Vision 的上下文中,RAG 可用于生成丰富、信息丰富的响应,这些响应基于文本和视觉数据。 GPT-4-Vision: ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: normal;orphans: 2;text-align: start;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;" class="list-paddingleft-1">GPT-4-Vision 是一个能够处理文本和图像的 GPT-4 版本,使其能够回答问题、生成描述以及执行需要理解视觉内容的任务。在这里我们可以使用gpt-4o-mini来提取文本/表格/图像。 这种能力在视觉上下文重要的任务中尤为有用,例如分析图像、创建视觉描述或结合文本和图像数据以提供更丰富的输出。 ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;"> ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">下面的代码演示了选项 3。让我们看看这个概念如何在一些应用中实际使用,在这些应用中我们将看到文本/表格/图像的使用。以下是每个部分的详细解释的代码: ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">下面的代码演示了选项 3。让我们看看这个概念如何在一些应用中实际使用,在这些应用中我们将看到文本/表格/图像的使用。以下是每个部分的详细解释的代码:!pip install langchain unstructured[all-docs] pydantic lxml openai chromadb tiktoken pytesseract
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">请在您的虚拟环境中安装上述软件包。除了上述 pip 软件包外,您还需要在系统中安装poppler(安装说明)和tesseract(安装说明)。from typing import Any
import os
from unstructured.partition.pdf import partition_pdf
import pytesseract
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
import base64
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, AIMessage
from dotenv import load_dotenv
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
# 从 .env 加载环境变量
load_dotenv()
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">此部分导入必要的库,并使用dotenv从.env文件加载环境变量。该文件可能包含敏感信息,例如 API 密钥,应保持私密。pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">设置 Tesseract OCR 可执行文件的路径。这使程序能够使用 OCR 从嵌入在 PDF 文档中的图像中提取文本。input_path = os.getcwd()
output_path = os.path.join(os.getcwd(), "figures")
# 获取元素
raw_pdf_elements = partition_pdf(
filename=os.path.join(input_path, "test.pdf"),
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=output_path,
)
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">定义输入和输出路径。input_path是当前工作目录,output_path是提取的 PDF 图像将被保存的位置。提取 PDF 文件中的元素,包括文本、表格和图像。参数控制文档的分块方式以及图像的存储位置。text_elements = []
table_elements = []
image_elements = []
# 编码图像的函数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
for element in raw_pdf_elements:
if 'CompositeElement' in str(type(element)):
text_elements.append(element)
elif 'Table' in str(type(element)):
table_elements.append(element)
table_elements = [i.text for i in table_elements]
text_elements = [i.text for i in text_elements]
# 表格
print("表格元素的数量为 :", len(table_elements))
# 文本
print("文本元素的数量为 :", len(text_elements))
for image_file in os.listdir(output_path):
if image_file.endswith(('.png', '.jpg', '.jpeg')):
image_path = os.path.join(output_path, image_file)
encoded_image = encode_image(image_path)
image_elements.append(encoded_image)
# 图像
print("图像元素的数量为 :",len(image_elements))
ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">初始化列表以存储从 PDF 中提取的不同类型的元素:文本、表格和图像。定义一个函数以 base64 格式编码图像,这使得它们可以轻松嵌入到提示中或存储。循环遍历提取的元素,将它们分类为文本和表格。每个元素的文本存储在相应的列表中。循环遍历输出目录中提取的图像,将它们编码为 base64,并存储在 image_elements 列表中。打印出每个类别(文本、表格、图像)中提取和处理的元素数量。chain_gpt= ChatOpenAI(model="gpt-4o-mini", max_tokens=1024)
初始化ChatOpenAI模型的实例,用于生成文本、表格和图像的摘要。 # 文本摘要的函数
def summarize_text(text_element):
prompt = f"总结以下文本:\n\n{text_element}\n\n摘要:"
response = chain_gpt.invoke([HumanMessage(content=prompt)])
return response.content
# 表格摘要的函数
def summarize_table(table_element):
prompt = f"总结以下表格:\n\n{table_element}\n\n摘要:"
response = chain_gpt.invoke([HumanMessage(content=prompt)])
return response.content
# 图像摘要的函数
def summarize_image(encoded_image):
prompt = [
AIMessage(content="你是一个擅长分析图像的机器人。"),
HumanMessage(content=[
{"type": "text", "text": "描述这张图像的内容。"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
},
},
])
]
response = chain_gpt.invoke(prompt)
return response.content
定义函数以使用初始化的ChatOpenAI模型生成文本、表格和图像的摘要。图像摘要函数包括描述图像内容的提示。 # 初始化向量存储和存储层
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
# 初始化检索器
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key)
初始化一个向量存储(Chroma)以存储嵌入,并初始化一个内存存储以保存原始文档。id_key用于唯一标识文档。初始化一个MultiVectorRetriever,用于根据查询检索相关文档。 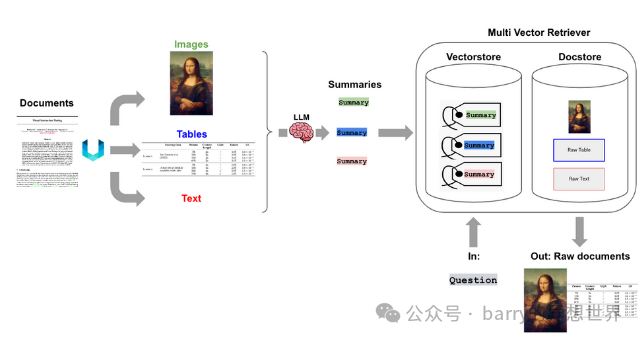
# 将文档添加到检索器的函数
def add_documents_to_retriever(summaries, original_contents):
doc_ids = [str(uuid.uuid4()) for _ in summaries]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, original_contents)))
# 添加文本摘要
add_documents_to_retriever(text_summaries, text_elements)
# 添加表格摘要
add_documents_to_retriever(table_summaries, table_elements)
# 添加图像摘要
add_documents_to_retriever(image_summaries, image_elements) # 希望很快能有真实图像
让我们测试一下如果我们给出一个问题,其中上下文涉及来自文本、图像和表格的所有信息,LLM 将如何回答。 template = """仅根据以下上下文回答问题,该上下文可以包括文本、图像和表格:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(temperature=0, model="gpt-4o-mini")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke(
"数据库中的图像显示了什么?展示一个包含独特名词短语和频率的图表。"))
多模态 RAG 与 GPT4Vision 和 LangChain 代表了构建先进 AI 应用程序的强大组合。通过利用 GPT-4-Vision 的多模态能力和 LangChain 提供的灵活工具,开发人员可以创建处理和生成文本和视觉内容的系统,从而导致更复杂和上下文感知的 AI 解决方案。以下是我们所涵盖的关键内容。 我们使用 Unstructured 从文档(PDF)中解析图像、文本和表格。 我们使用 multi-vector retriever 和 Chroma 来存储原始文本和图像及其摘要以供检索。 我们使用 GPT-4V(GPT-4o-mini)进行图像摘要(用于检索)以及从图像和文本(或表格)的联合审查中生成最终答案。 检索是基于与图像摘要以及文本块的相似性进行的。
|










