前段时间,Meta 开源了 Llama 3.2 轻量化模型,为移动端跑大模型提供了新选择!
同时,Llama 3.2 视觉模型(Llama 3.2 Vision)也正式开源,号称媲美 GPT-4o。
前两天,Llama 3.2 Vision 已在 Ollama 上线!
今日分享,就对它实测一番。
最后,应用到我们上篇的票据识别任务中,看看效果真有官宣的那么惊艳么?
1. Llama 3.2 亮点
老规矩,还是简短介绍下:Llama 3.2 都有哪些亮点?
一句话:轻量化 + 视觉多模态能力!
具体点:
- 文本模型:有 1B 和 3B 版本,即便参数少,也支持128k tokens的上下文长度;基于LoRA和SpinQuant 对模型进行深度优化,内存使用量减少41%,推理效率翻了2-4倍。
- 多模态模型:有 11B 和 90B 版本,在视觉理解方面,与Claude3 Haiku和GPT 4o-mini 可 PK。
2. Llama 3.2 实测
Ollama 是面向小白友好的大模型部署工具,为此本篇继续采用 Ollama 跑 Llama 3.2。
不了解 Ollama 的小伙伴,可翻看教程:
本地部署大模型?Ollama 部署和实战,看这篇就够了
2.1 环境准备
参考上述教程,假设你在本地已经准备好 Ollama。
当前 Ollama Library 中已支持 Llama 3.2 下载,因此,一行命令拉起llama3.2-vision。
ollamarunllama3.2-vision
如果遇到如下报错:
pullingmanifest
Error:pullmodelmanifest:412:
ThemodelyouareattemptingtopullrequiresanewerversionofOllama.
说明你的 ollama 版本需要更新了。
如果你也和我一样,采用 docker 安装,则需要删除容器,重新下载最新镜像进行安装:
dockerstopollama
dockerrmollama
dockerimagermollama/ollama
#注:海外镜像,国内用户需自备梯子
dockerpullollama/ollama
可以发现,当前最新版本为 0.4.1:
ollama--version
ollamaversionis0.4.1
然后,再起一个容器:
dockerrun-d--gpus"device=2"-vollama:/root/.ollama-p3002:11434--restartunless-stopped--nameollamaollama/ollama
注:我这里指定 --gpus "device=2",如果单张显存不够,需指定多张卡,Ollama 会帮你自动分配。
显存占用情况如何?
2.2 文本模型
进入容器,并下载模型 llama3.2 3B版本:
dockerexec-itollama/bin/bash
ollamarunllama3.2
显存占用:请确保至少 4 G 显存。

2.3 多模态模型
进入容器,并下载模型 llama3.2-vision 11B版本:
dockerexec-itollama/bin/bash
ollamarunllama3.2-vision
显存占用:请确保至少 12 G 显存。
注:ollama 中模型默认采用了 4bit 量化。
3. 接入 Dify
3.1 模型接入
要把 Ollama 部署的模型接入 Dify 有两种方式。
首先,找到设置 - 模型供应商。
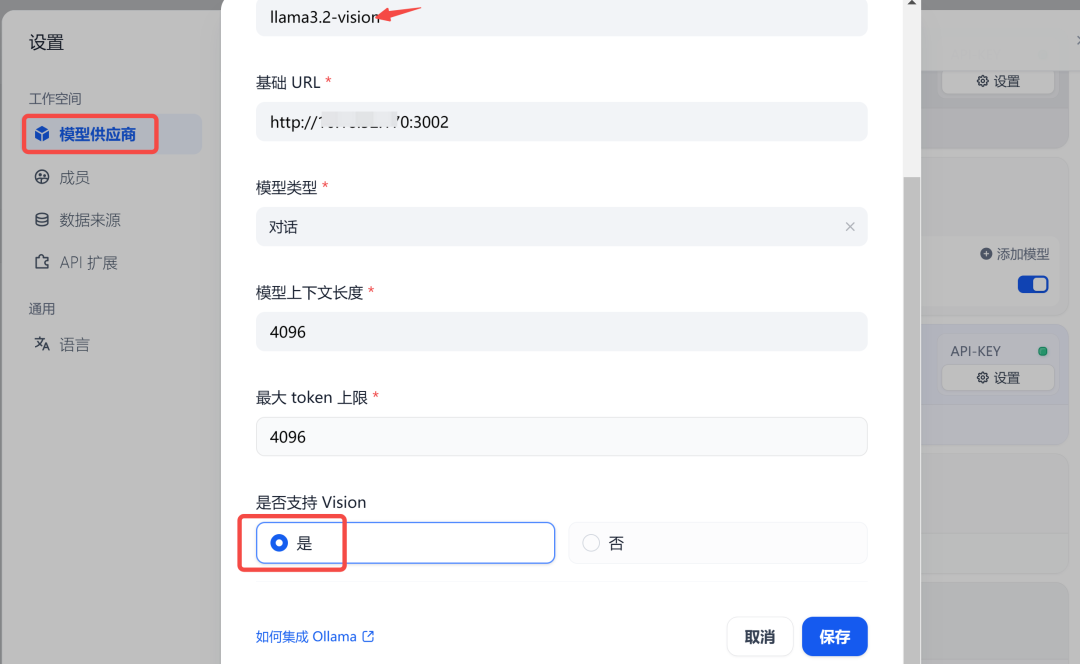
方式一:找到 Ollama 类型,然后进行添加,记得把Vision能力打开:
方式二:
把 Ollama 模型接入 OneAPI,然后在模型供应商这里选择 OpenAI-API-compatible。
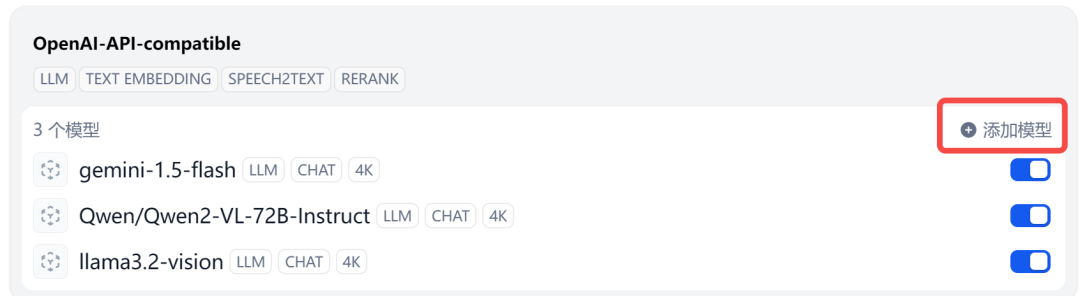
不了解 OneAPI 的小伙伴可以回看教程:一键封装成OpenAI协议,强推的一款神器!
个人更推荐 方式二,你会体会到接口统一的快乐~
3.2 应用集成
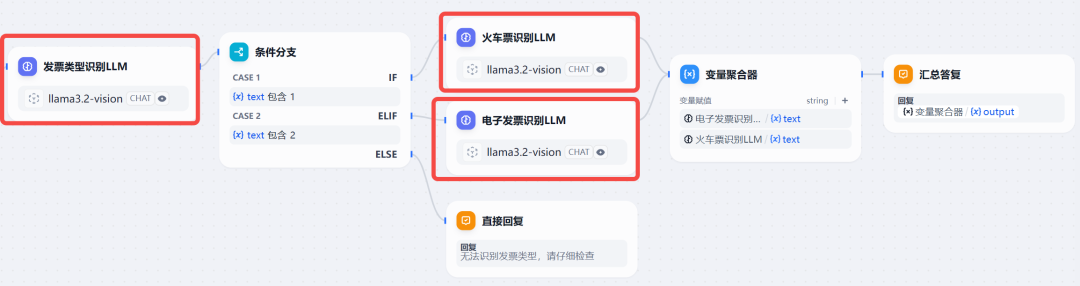
最后,我们在上篇的基础上,把用到 Qwen2-VL 的组件,LLM 全部替换成刚刚接入的 llama3.2-vision,如下图:
实测效果咋样?
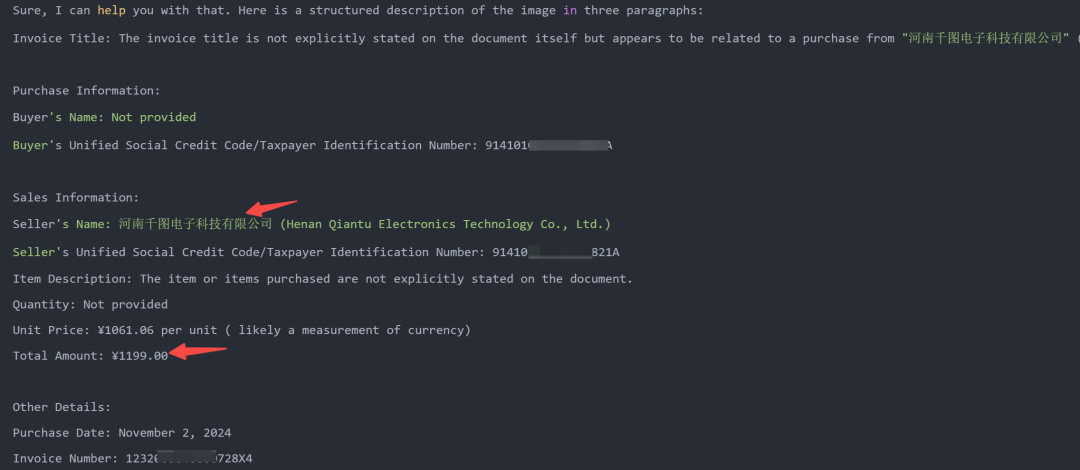
嗯~ o( ̄▽ ̄)o 价格等基本信息还是抓到了。
只是,相比上篇实测的 Qwen2-VL 就差点意思了:
- 从中文指令遵循上看:给到同样的提示词,llama3.2-vision 压根不按你的意图来;
- 从识别结果上看:中文 OCR 也被 Qwen2-VL 甩开好几条街。
当然,换用 90B 的模型会不会好很多?感兴趣的朋友可以试试~










