|
前言 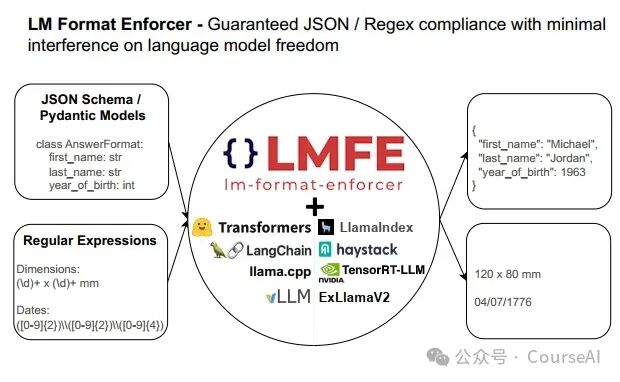 LLM已经向我们展示了其强大的生成能力,但是当我们想提从生成的文本中提取结构化数据,确实遇到了非常大的挑战。 特别是在提取json格式时, 不仅要求模型输出符合特定的语法规则,还需要确保数据能被正确的提取出来。 下面将给大家介绍 lm-format-enforcer 这个款Json格式提取工具 lm-format-enforcer 的能力 比JSONFormer Outlines支持更多的能力。 目前已经成为了vllm 作为 JSON 格式输出的后端之一. 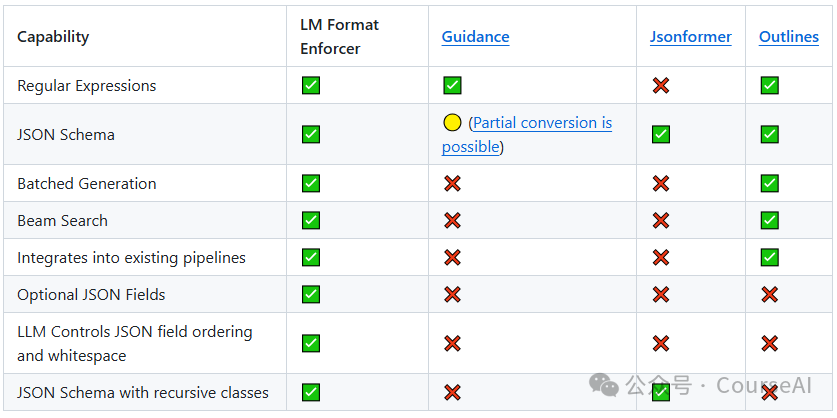 支持批量生成和波束搜索 :每个input/beam 可以在每个时间步过滤不同的标记 支持 JSON 模式、JSON 模式(无模式)和正则表达式格式 使语言模型可以自由控制 JSON 模式中的空格和字段顺序,从而减少幻觉。 支持transformers,LangChain,LlamaIndex,llama.cpp,vLLM,Haystack,NVIDIA TensorRT-LLMandExLlamaV2.
Json格式化输出的原理解析  lm-format-enforcer约束Json输出的原理:语言模型在每个时间步骤step,输出LLM的logits之后,在生成下一个token之前,通过设定的规则,只允许在给定的token的范围内采样,并通过添加bias的方式,不允许采样其他token,从而实现指定的结构化生成。 具体可以参考上图,分两步走: Token 词表前缀树的构建首先会根据 tokenizer 给出的词表,初始化一个字符级别的前缀树。 前缀树上某个节点对应某个token,该节点的第一个子节点连着这个token中的第一个个字符,下一个子节点,对应这token中的下一个字符。 当token中的字符遍历完了,这时候就是填入该token对应的 token id 这样整个token词表中的 token 和 token id 的映射都会通过这样的方式插入到前缀树中。
约束Token按照指定格式输出在初始化的时候,会接收用户指定的 json schema 接着在后续每一步生成过程中,会根据之前生成的内容,判断目前处于什么状态
lm-format-enforcer 实战 frompydanticimportBaseModel
fromlmformatenforcerimportJsonSchemaParser
fromlmformatenforcer.integrations.transformersimportbuild_transformers_prefix_allowed_tokens_fn
fromtransformersimportpipeline
classAnswerFormat(BaseModel):
first_name:str
last_name:str
year_of_birth:int
num_seasons_in_nba:int
#Createatransformerspipeline
hf_pipeline=pipeline('text-generation',model='TheBloke/Llama-2-7b-Chat-GPTQ',device_map='auto')
prompt=f'HereisinformationaboutMichaelJordaninthefollowingjsonschema:{AnswerFormat.schema_json()}:\n'
#Createacharacterlevelparserandbuildatransformersprefixfunctionfromit
parser=JsonSchemaParser(AnswerFormat.schema())
prefix_function=build_transformers_prefix_allowed_tokens_fn(hf_pipeline.tokenizer,parser)
#Callthepipelinewiththeprefixfunction
output_dict=hf_pipeline(prompt,prefix_allowed_tokens_fn=prefix_function)
#Extracttheresults
result=output_dict[0]['generated_text'][len(prompt):]
print(result)
#{'first_name':'Michael','last_name':'Jordan','year_of_birth':1963,'num_seasons_in_nba':15
| 









