|
当我们开发一段代码,可以精确地用测试用例来测试这段代码,固定的输入对应固定的输出,测试所有的输入就可以覆盖所有的代码逻辑。然而大模型输入输出是自然语言,自然就会接收千奇百怪的输入。例如: 产品研发时,需要对大模型的输入输出做调试,确定任务拆解能力是否符合预期; 业务上线后,需要评估大模型面向真实场景的质量,是否解决实际问题; 日常经营中,需要对所有输入输出做审计、以保持合规性。
结合以上需求,我们需要对大模型应用的输入与输出具备评判的能力,对内容进行检索、分析与评估,确保应用整体行为符合预期。 为了更好的处理大模型输入输出日志,从而更好的理解用户需求、评估大模型的表现。这就要求日志管理工具具备面向自然语言的搜索、处理、分析的能力,包括: 语义富化:多角度提炼结构化信息,包括用户意图、主题、情绪等内容; 向量检索:一站式向量检索能力,集成 embedidng/vector_index 能力,开箱即用。除了关键字、子串匹配外,还能够根据意图来检索内容。 混合检索:同时使用关键字精确匹配和向量近似匹配,融合多字段检索需求。 聚类:同更高视角对自然语言进行聚类分析,掌握热点和离群点。
在 RAG 领域,要把文件转化为结构化 Markdown 信息,再对 Markdown 文件切分 chunk 构建向量索引。在 RAG 场景中,传统文档处理流程存在信息损耗问题。需要通过多模态特征提取,构建多维度语义特征空间,从不同的角度来观察 LLM 输入输出,这些角度包括: 用户意图:用户在会话中所展示出来的意图,例如是翻译、技术咨询、法律咨询、查询与检索; 所属主题:会话所属主题,例如教育、云计算、法律; 总结:原始的会话往往叠加复杂的上下文,语义索引用一句话描述会话的信息,用户搜索总结可以快速命中记录; 情绪:用户在会话中所展示的情绪,是正面、负面、中性; 关键词:抽取会话中的关键词; 问题:针对原始会话提出几个问题,而原始会话是问题的答案。当用户使用问题去召回历史会话时,可以直接通过该字段召回; 实体抽取:抽取出现的实体,例如国家、地名、人名等。
借助于 LLM 评估、向量索引,给 Prompt/Response 提取出结构化信息,并且以可视化的形式展示分析结果。基于评估结果,从而实现对用户意图、情绪、关注点、常见问题的理解,了解 LLM 响应质量,方便下一次训练积习难改调优,对输入、输出进行合规审计,避免法律风险。 利用日志服务 SLS 的语义处理能力,在数据加工过程中提供开放式接口的方案,对接百炼托管模型 API 或者自研 LLM API,从而实现基于 LLM 进行语义富化。 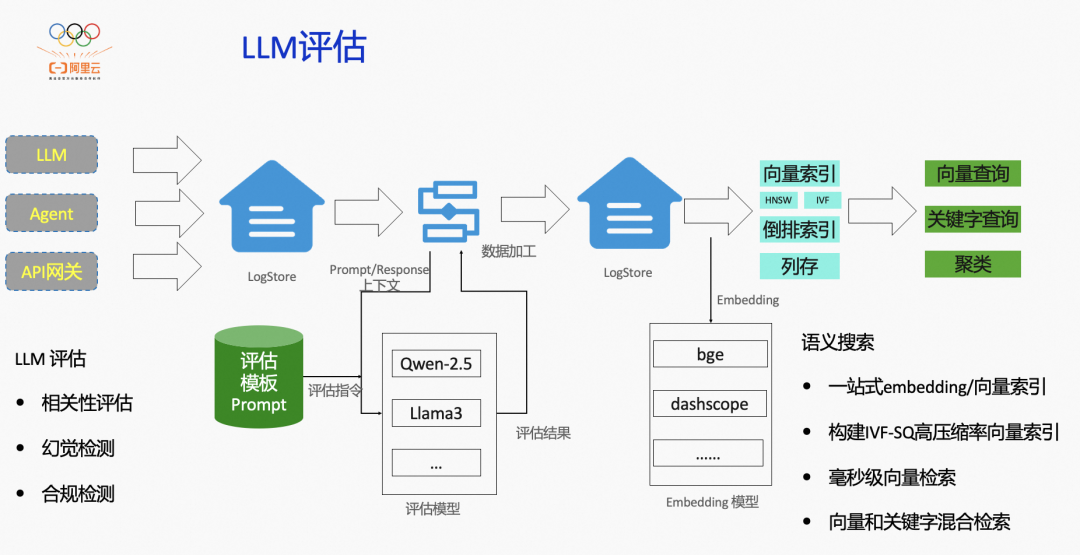
LLM 评估架构包括以下几个关键组件: 通用 HTTP 函数:数据加工 SPL 语法提供了通用的 HTTP 调用函数,传入URL、 Body、Header等信息,调用外部服务来处理数据,获取处理结果。 调用 Qwen 模型:在通用 HTTP 函数之上,封装出 Qwen 的 AIGC 函数,传入 Qwen 地址,百炼 access-key,system prompt,user prompt 来调用百炼的 Qwen 模型。 系统/自定义 Prompt 库:SLS 提供用于评估功能的 Evaluation System Prompt 模板库,选择需要的评估功能所对应的 Evaluation System Prompt,并把日志中的 prompt/response 作为普通文本传入 User Prompt。也可以传入自己的 Prompt,自定义处理逻辑。
通过可自定义 Prompt,自定义 endpoint,自定义 model 来实现独特的业务需求。以下是 SLS内置的语义富化语句: *|extend"__tag__:__sls_qwen_user_tpl__"=replace(replace(replace(replace(replace(replace(replace(replace("__tag__:__sls_qwen_user_tpl__",'<INPUT_TEMPLATE>',"output.value"),'\','\\'),'"','\"'),chr(8),'\b'),chr(12),'\f'),chr(10),'\n'),chr(13),'\r'),chr(9),'\t')|extend"__tag__:__sls_qwen_sys_tpl__"=replace(replace(replace(replace(replace(replace(replace("__tag__:__sls_qwen_sys_tpl__",'\','\\'),'"','\"'),chr(8),'\b'),chr(12),'\f'),chr(10),'\n'),chr(13),'\r'),chr(9),'\t')|extendrequest_body=replace(replace("__tag__:__sls_qwen_body_tpl__",'<SYSTEM_PROMPT>',"__tag__:__sls_qwen_sys_tpl__"),'<USER_PROMPT>',"__tag__:__sls_qwen_user_tpl__")|http-call-method='post'-headers='{"Authorization":"Bearerxxxxxx","Content-Type":"application/json","Host":"dashscope.aliyuncs.com","User-Agent":"sls-etl-test"}'-timeout_millis=60000-body='request_body''http://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation'asstatus,response_body|extendtmp_content=json_extract_scalar(response_body,'$.output.choices.0.message.content')|extendoutput_enrich=regexp_replace(regexp_replace(tmp_content,'^([^{]|\s)+{','{'),'}([^}]|\s)+$','}')|project-away"__tag__:__sls_qwen_sys_tpl__","__tag__:__sls_qwen_user_tpl__","__tag__:__sls_qwen_body_tpl__",trimed_input,tmp_content,request_body,response_body语义评估结果: 
在实际落地上,向量检索存在诸多工程挑战,包括但不限于: 若要完成向量检索,需要先把文本经过 embedding 转换为向量,然后为向量构建索引。工程复杂度较高,需要维护数据的导入、embedding 模块、向量索引模块、查询模块。 召回率受 embedding 模型、向量索引类型影响,研发代价较大。 成本较高,无论是 embedding 转换成本,还是构建向量索引,都需要引入 GPU 完成。而向量的存储空间也非常高,在查询时需要占用大量内存。这些因素导致了向量检索的成本居高不下。
如上文架构图所示,SLS 提供一站式的向量检索能力。Prompt/Response 等自然语言写入 SLS 后,可自动完成 embedding 转向量、构建向量索引。在查询时,自动将查询语句转换为向量,然后从向量索引中查找近似向量,根据命中的 docID 去读取原始数据。无需关心中间的向量类型,只需要写入文本数据,查询文本数据即可。 SLS 提供向量查询语法,在使用查询语法的过程中需要关注以下关键点: - 通过 similarity 语法来表达近似度的语义;
指定查询距离,0 表示最相似,1 表示最不相似。
similarity(Key,query)<distance 在某些场景下,不仅需要近似检索长文本,还需要精确匹配某些字段。例如查询某个 uid 的 Prompt,需要同时精确命中 uid 和近似查询 Prompt 列。这时候就需要混合检索了。混合检索使用 and 条件连接,会分别查询关键字倒排索引和向量索引,然后合并两者结果: uid:123andsimilarity(key,query)<distance 针对纷繁复杂的用户输入和大模型输出,如何找到其中的热点问题?有哪些问题是离群点?当只有文本时,由于文本之间是互不相同的,很难做分析。而通过向量把文本转换为向量后,就可以根据空间距离来对向量做聚类了。聚类依赖于 SQL 函数,cluster_centroids 函数指定一个二维数组,和聚类个数,生成对应的聚类结果: clustering_centroids(array(array(double))samples,integernum_of_clusters)
与此同时,高维向量在空间中无法可视化,SLS 提供降维函数,把高维向量转换为二位向量,用于可视化,我们可以从下图看到语义聚类与降维后的可视化效果图。 t_sne(array(array(double)) 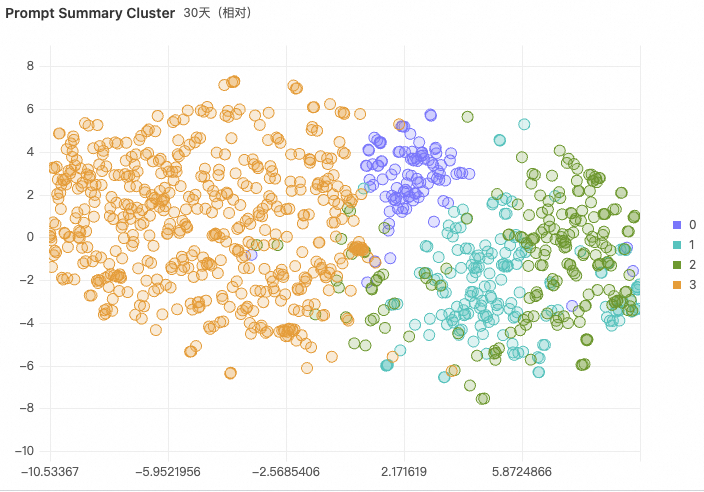
LLM Prompt/Reponse 语义洞察的工程实践 从原始 Prompt 和 Response 提取语义信息后,通过关键字检索、向量检索、语义聚类达到以下业务目标: 通过检索特定的关键字查找是否存在不合规行为。例如把一些违禁词设为关键字,查询近似词,这通过 similarity 语法来实现。similarity 可通过调整距离来调整相似性。 similarity("input_semantic.summary","恶意关键词")<0.4在语义处理阶段,评估引擎对自然语言做了分类,提取了主题、情绪等分类内容。在 Chatbot 应用中,可以查看特定主题的会话历史。 input_semantic.topic:database 基于聚类,我们可以把相似内容聚成一类,可以查看话题之间的相关性和距离。聚类效果图如下图中的最右侧图所示,每一种颜色是一种类别,可以很清晰地看到某些话题和其他话题距离比较远。 通过语义富化、搜索,可以更好地实现对大模型输入输出的理解,从而建设更懂得自然语言的大模型应用。除此之外,还可以把方法从内容分析,拓展到各垂直场景中,例如: | 









