|
前文我升了 CUDA、部署了 DeepSeek-OCRDeepSeek-OCR 本地部署(上):CUDA 升级 12.9,vLLM 升级至最新稳定版
DeepSeek-OCR 本地部署(下):vLLM 离线推理,API 重写,支持本地图片、PDF 解析重写的 API 也支持 PaddleOCR-VL本地部署 PaddleOCR,消费级显卡轻松跑,支持本地图片和 PDF 文件 然后腾讯也来了:大模型 OCR 的黄金时代,腾讯开源混元 OCR,文档解析、视觉问答和翻译方面达到 SOTA,文中我提到想等等看新版 vLLM 来了再部署 可是看到 N 多同学部署失败,还有 HunyuanOCR 到底需要多少显存可以跑起来有点疑问。 前文我就提到,可能是官方文档写错了现存和磁盘空间,当时写的是需要 80GB 显存 后来修改成了 20GB 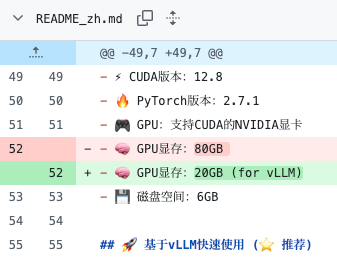 安装及模型启动 - 官方教程我没有使用官方教程,感觉。。。太麻烦了 1 是失败概率蛮高,依赖太多,安装环境不能用 pip,必须使用 uv 2 是我是在离线环境部署,所以下面方式对我无效 uv venv hunyuanocr
sourcehunyuanocr/bin/activate
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
模型启动就简单了,只要前面 vLLM 安装顺利,下面就几乎不会出问题 出问题,大概率是 CUDA 版本太低造成的,建议 12.9 以上,毕竟未来 vLLM 0.11.1 之后版本默认就要 12.9 起步了 下载好 HunyuanOCR 模型文件后正常启动就行 # 模型启动-官方教程
vllm serve tencent/HunyuanOCR \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--gpu-memory-utilization 0.2
安装及模型启动 - 我的方式最省心,省事儿,离线最友好的方式必须是 Docker 第一步,拉取 vllm/vllm-openai 官方镜像,选最近的一个 nightly 即可 docker pull vllm/vllm-openai:nightly
 第二步,保存镜像到内网,如果本机测试那就没这一步了 第三步,启动模型,核心参数和官方教程没啥区别 docker run --rm --runtime=nvidia --name Hunyuan-ocr --ipc=host --gpus'"device=1"'-p 5000:8000 -v /data/llm-models:/models vllm/vllm-openai:nightly
--model /models/HunyuanOCR --port 8000 --no-enable-prefix-caching --mm-processor-cache-gb 0
我的显卡是 24GB 的 4090 模型只占 1.9GB,其他都是 KV cache 占用 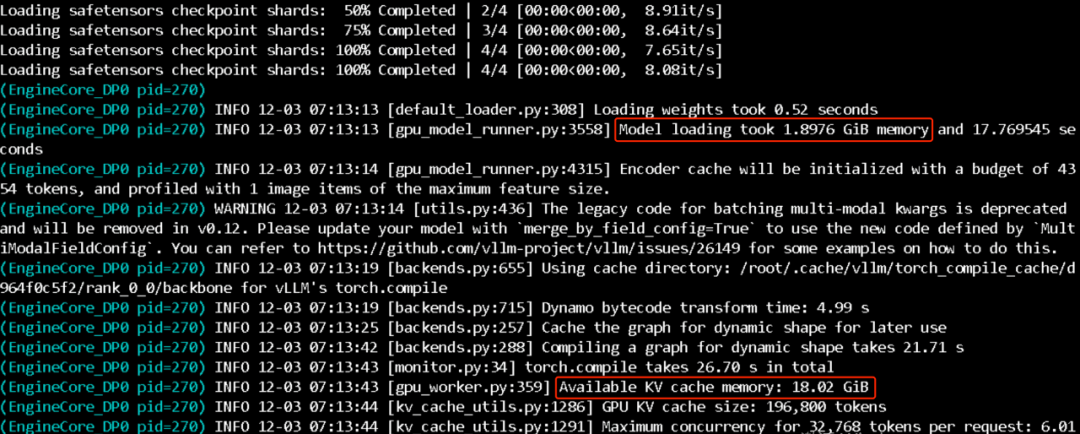 官方教程中的模型调用貌似也不太友好啊,我还是用了为 DeeoSeekOCR 写的 API,简单修改后依然很好用 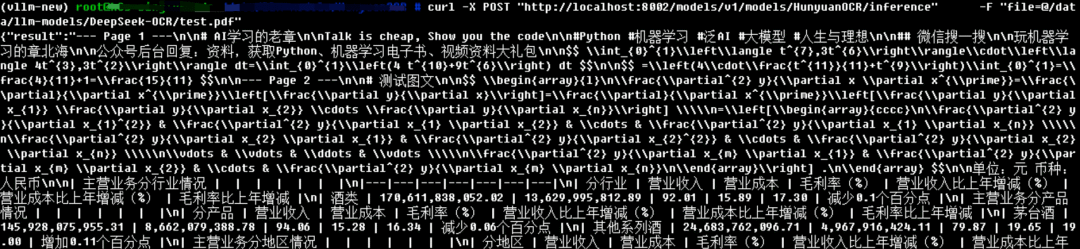 速度飞快,5 页的 PDF 也是秒秒钟搞定 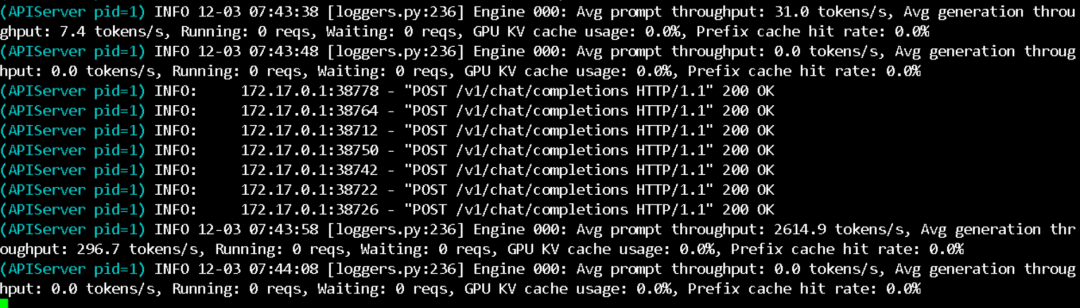 回到最开始问题,启动模型加上参数 --gpu-memory-utilization 0.66,也就是 16GB 启动模型,依然是 OK 的 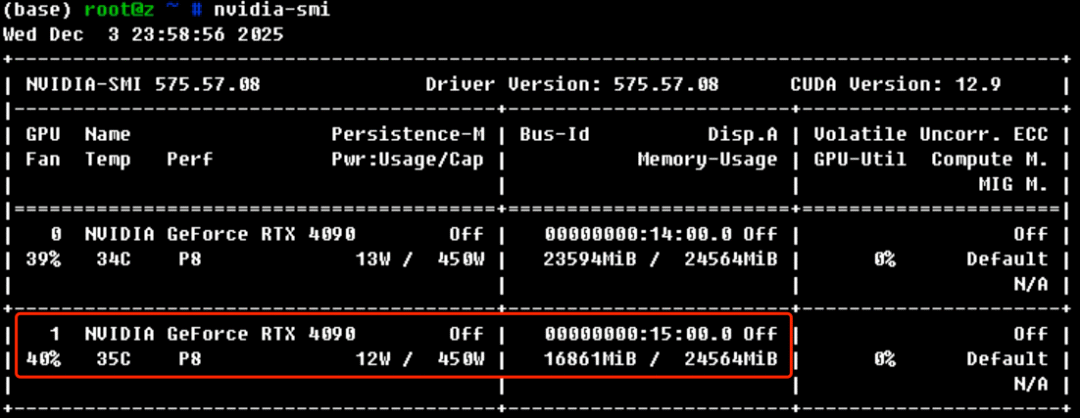 而且速度丝毫没有下降 | 









