|
放眼看去,现在各大闭源开源的Code模型还是以200K的居多。 200k Tokens真的够用吗? Amp 团队最近写了一个文章,说200k Tokens才是正道,不仅是够用,而且相当长的时间它就应该是主流。 以Opus 4.5为例子,已发布几周了,它是Amp团队的主力模型,也被公认为目前最强的编程模型。下放!Opus 4.5 在Claude Code 20刀订阅中可用 但它的上下文窗口只有200ktokens。 有人诟病说不如Gemini 3 Pro的好,都2025年了,纯是挤牙膏。 但是Amp团队觉得200ktokens就刚刚好,这不仅仅是它们团队中某个人的偏好,而是整个团队都在践行的一种工作哲学,全员短线程。 为什么要抛弃百万级 Context? Amp团队也是从它们无数爬坑的实践中得的理论,Amp团队最近给 Amp 上线了一个新功能,在命令面板中添加发送至支持的指令。 这个任务不是直接在一个巨大的窗口上下文中完成,而是由一组相互连接的微小工作线程组成的。 最大的一个工作线程用了151k输出 tokens,只有四条用户消息。 平均下来的工作线程长度在80k tokens左右。 即便把这13个相关联的工作线程全部加起来,其实也勉强能塞进一个100 万 token 的窗口里。 那么问题来了,为什么不直接把所有东西丢进一个超大工作线程里,省去开新对话的麻烦呢? Amp 团队的观点是:因为Agent会喝醉 Amp团队在他们的 Context 管理指南里写过这样一句话,如果你喂给 Agent 太多 tokens,它们会醉。 原因很简单,上下文过载的模型行为像醉汉! 模型开始胡言乱语,逻辑混乱,甚至和开发者抬杠,如果继续喂数据,它们吐出来的代码更是一塌糊涂。 Agent的本质是模型、系统提示词、工具以及对话历史的集合。 对话越长,历史包袱越重,充斥着大量与当前任务无关的噪音。 想要Agent表现最佳,必须只提供完成当前任务所需的上下文,多一点都是累赘。 长对话是陷阱 除了效果差,长对话还是成本黑洞。 每一次请求,所有历史 token都要重新发送给模型提供商。成本呈指数级上升,尤其是象Cursor这种现在已经全面按Token收费的厂商。 而且时间越长回答就越慢! 长工作线程往往更长的思考停顿,而且累计起来的结果就是错过缓存窗口,Token爆炸。 那应该怎么做呢? 把线程拆碎,就是把任务拆碎 他们应该最正确的是方式是,任务拆解。 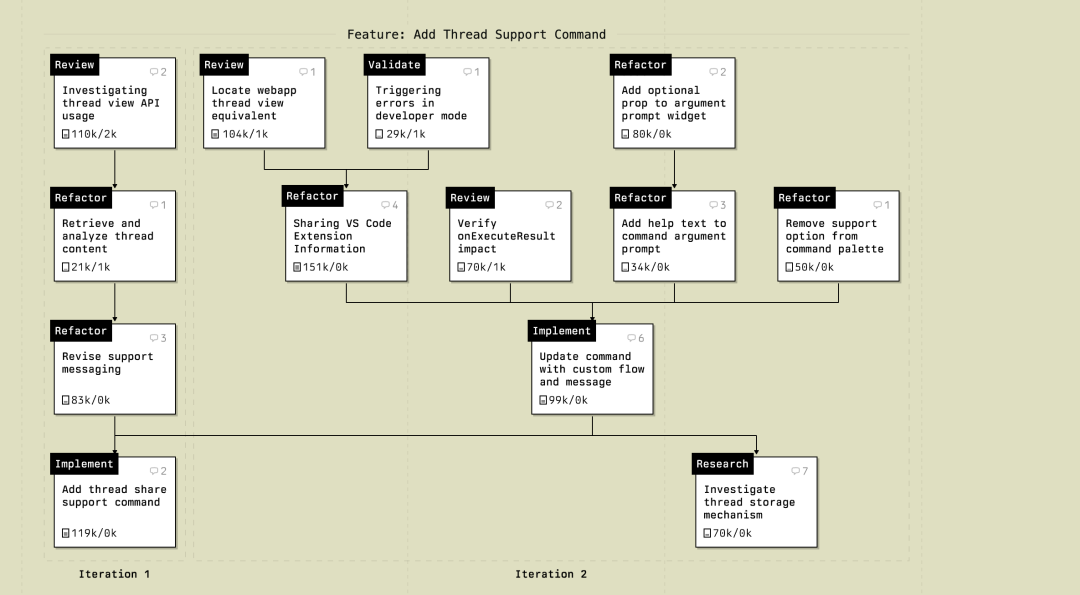
其实传统开发,就是这种模块化开发,把大任务拆成一个个小任务。 AI Code也应如此。 让每一个线程都有一个明确的目标,才能让原本复杂的开发流程变得清晰、可控,而且速度极快。 自下而上的构建流 观察Amp团队的编码方式,这是一种典型的自下而上的构建过程。 首先,开一个工作线程构建基础实现。 如果特别复杂,会先开一个工作线程专门调研代码库,收集上下文。 有了基础后,开启全新的线程来进行调整或重构。 一个改动就是一个线程。使用工具读取上一个工作线程的上下文。 代码写完了,评审环节也是新工作线程。 让 AI 阅读新代码,检查是否符合现有的设计模式,确保没有引入坏味道。 验证阶段,再开几个新线程,写一次性脚本、跑测试、分析性能日志、强制触发错误状态。 在Amp中,开发者通过引用 ID 或 URL 来在线程间传递上下文,这比使用多个 markdown 文件来记录规格和历史要轻量得多。 整个过程非常流畅。 新建线程,输入引用指令关联上一个相关线程。 如果需要主线程的背景,一键切换回去。 这就是高效团队的工作流。 每一个线程都是一个离散的原子任务,无数个原子任务聚合成了一个完整的功能。 方向盘依然在人手中,车速更快,路费更省,逻辑更清晰。 所以,200k tokens 够吗? 就目前来说,只要掌握了模块化子任务,简直是绰绰有余! | 









