|
概述:RAG(检索增强生成)是一种结合信息检索和生成模型的技术,允许用户将自己的数据与大型语言模型(LLM)结合,生成更精确和上下文相关的输出。这篇文章将简要介绍RAG的基本概念,并提供一个简化的教程,帮助初学者从零开始构建RAG应用程序。 
一、学习RAG的挑战在快速变化的AI领域中,特别是关于RAG,存在大量噪音和复杂性。供应商往往将其过度复杂化,试图将他们的工具、生态系统和愿景注入其中。本教程旨在帮助初学者消除这些干扰,专注于从头构建一个简单的RAG系统。 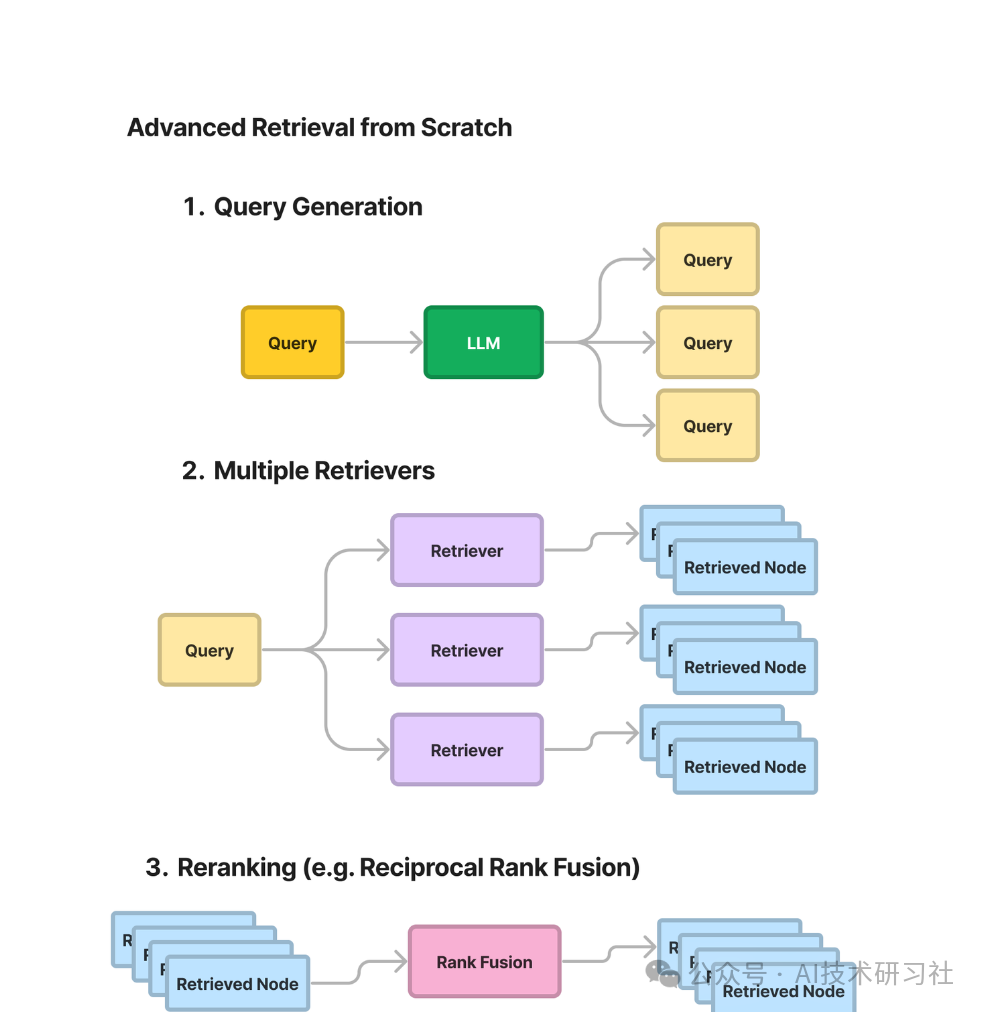
二、什么是检索增强生成(RAG)RAG的核心思想是通过检索工具将用户的自有数据添加到传递给大型语言模型的提示中,以此生成输出。相比单纯依赖预训练模型,这种方法带来了多项优势: 三、RAG系统的基本组件一个RAG系统由以下几个组件构成: 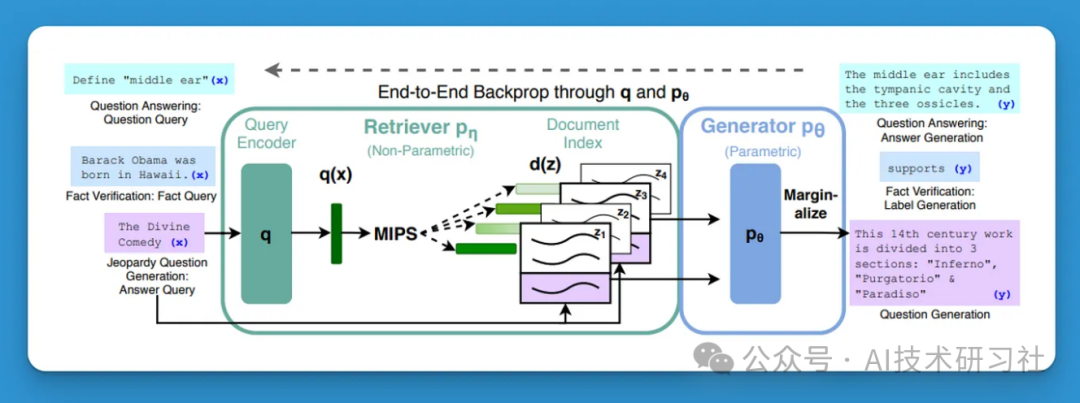
文档集合(语料库) 用户输入 文档集合与用户输入之间的相似性度量
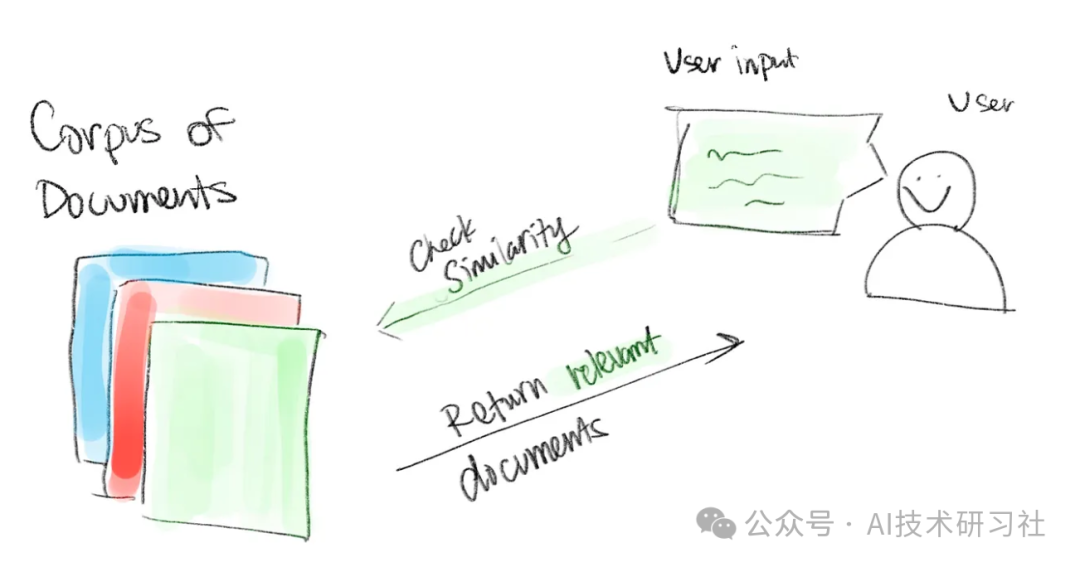
四、RAG系统的操作步骤接收用户输入 执行相似性测量 对用户输入和检索到的文档进行后处理
初学者可以通过以下步骤从头构建一个RAG系统,并逐步学习复杂的变体。 五、示例:构建最简单的RAG系统1. 获取文档集合首先,我们定义一个简单的文档集合: corpus_of_documents=["Takealeisurelywalkintheparkandenjoythefreshair.","Visitalocalmuseumanddiscoversomethingnew.","Attendalivemusicconcertandfeeltherhythm.","Goforahikeandadmirethenaturalscenery.","Haveapicnicwithfriendsandsharesomelaughs.","Exploreanewcuisinebydiningatanethnicrestaurant.","Takeayogaclassandstretchyourbodyandmind.","Joinalocalsportsleagueandenjoysomefriendlycompetition.","Attendaworkshoporlectureonatopicyou'reinterestedin.","Visitanamusementparkandridetherollercoasters."] 2. 定义与执行相似性度量为了比较用户输入和文档集合的相似性,我们可以使用Jaccard相似度。Jaccard相似度是指两个集合的交集除以并集的大小。以下是一个简单的实现: defjaccard_similarity(query,document):query=query.lower().split("")document=document.lower().split("")intersection=set(query).intersection(set(document))union=set(query).union(set(document))returnlen(intersection)/len(union)接下来,我们定义一个函数来返回与用户输入最相似的文档: defreturn_response(query,corpus):similarities=[]fordocincorpus:similarity=jaccard_similarity(query,doc)similarities.append(similarity)returncorpus_of_documents[similarities.index(max(similarities))] 3. 运行示例我们可以通过以下代码运行一个简单的示例: user_prompt="Whatisaleisureactivitythatyoulike?"user_input="Iliketohike"response=return_response(user_input,corpus_of_documents)print(response) 输出将是: 'Goforahikeandadmirethenaturalscenery.' 恭喜,您已经构建了一个基本的RAG应用程序! 六、改进相似性度量与添加LLM虽然我们使用了简单的Jaccard相似度来学习,但它在处理语义上存在局限。为了进一步提升生成效果,我们可以引入大型语言模型(LLM)进行后处理。以下是一个集成开源LLM的简单示例: import requestsimport json
def query_llama(user_input, document):# 假设你有一个运行的LLM服务,可以发送HTTP请求获取生成的文本url = "http://localhost:8000/query"# LLM服务的URLpayload = {"prompt": f"User input: {user_input}\nDocument: {document}\nResponse:","max_tokens": 50}headers = {"Content-Type": "application/json"}response = requests.post(url, data=json.dumps(payload), headers=headers)return response.json().get("text")
response_with_llm = query_llama(user_input, response)print(response_with_llm)
以上代码示例演示了如何将检索到的文档与用户输入结合,使用LLM生成更准确的响应。 七、总结与展望RAG为LLM提供了一个灵活且强大的框架,允许用户利用自有数据来增强生成效果。本教程介绍了如何从头开始构建一个简单的RAG系统,并如何逐步引入更复杂的组件,如LLM。今后,您可以通过更先进的相似性测量和检索技术进一步提升RAG系统的性能。
| 









