我们简单介绍了Llama模型的背景以及具体调用的内容,但是上节课内容并没有去涉及具体的提示词工程部分的内容,主要是讲述如何调用模型以及内部具体的一些小技巧。那在这节课中,我们将深入地讲解提示词工程中的部分技巧,并且将对比Llama家族中的部分模型,那就让我们开始吧!

提示词工程技巧
Prompt Engineering 是一种技术,允许你通过特定指令或包含不同类型的信息(即"上下文")来引导模型改善其对你任务的响应。有几种方法可以实现这一点:

需要注意的是,有些时候,有些任务解决不了,可能是因为模型太小、能力不够的原因,用参数量大一点的模型可能会更好。然后其实对于比较弱的模型而言,提示词工程是非常重要的,但是对于更强的模型而言,详细复杂的提示词反而变得没那么重要,因为模型的能力已经很强了,只要你表达出你基本的意思它就能够理解了。而弱的模型一定要你把问题说得很清楚才看得懂。
Zero-shot prompting(不包含示例的提示词)
那对于提示词工程而言,最简单的就是直接来进行提问,比如说直接就是用冒号来让其理解含义。下面这个例子就是如此,就直接用Message: xxx Sentiment: 的方式来让模型理解,甚至没有通过这样一句“你认为这句话Message:”xxx“的Sentiment是什么呢?”。在这种情况下,对于小模型而言是很难准确的按照要求来进行回复,因为语义信息非常不明显,因此可能我们还需要进一步的调整。

Few-shot prompting(包含少量示例的提示词)
那在直接询问的基础上,Few-shot prompting的意思就是给几个相关的例子作为案例,让模型理解他需要输出的内容是什么。就比如下面同样的问题给到模型,但是不同的是在问问题之前给出了一个完整的案例告诉模型回答的模型。在这种情况下,小模型更有可能能够准确回答出问题。由此得出,在询问问题的时候,给出示范案例是能够显著提升模型输出效果的,尤其是在格式上有要求的情况下。

明确输出格式
假如我们格式上有任何要求的话,其实我们需要清晰的给模型表达出来。比如说上面语义的案例,我们假如修改为“你认为这句话Message:”xxx“的Sentiment是什么呢?最后请以 Sentiment: Positive 或者 Sentiment: Negative的格式输出” 的话,模型是更有可能回复出来的。下面的例子也是一样,假如我们只想让其输出Positive或者Negative的话,那明确的在最后告知只用输出一个词是非常有必要的。
prompt="""
Message:HiDad,you're20minuteslatetomypianorecital!
Sentiment:Negative
Message:Can'twaittoorderpizzafordinnertonight
Sentiment ositive
ositive
Message:HiAmit,thanksforthethoughtfulbirthdaycard!
Sentiment:?
Giveaonewordresponse.
"""
response=llama(prompt)
print(response)
在实际使用过程中,我们会发现大语言模型经常会“偷懒”,即便我们让其写1500字的文章,我们会发现其最多写了800字。那因此假如我们想让其写1500字的话我们最好说请写2500字左右的文章,这样扩大自己要求的说法可能让模型更好的满足我们的需求。不过模型输出的上下文也是有上限的,所以我们假如发现模型一直卡在输出某一个长度,那可能这个就是其最大的长度了。不过我们可以分段让其进行扩写从而获得我们想要的字数。
角色定义
有些时候我们可以指定某个角色给到模型让其扮演,从而能够回答得更加专业。比如当我们直接问一个问题的时候,可能模型只会很泛泛的回答你,但是当我们指定某个角色的时候,或许模型能够根据训练时角色的资料带入到该角色相关的领域内,从而给出更加特质化的回复。
比如下面我们指定是生活导师的话,回复会更加像一名循循善诱的导师而非单纯给你建议的人。假如我们在请教如何讲解某个内容的时候说请作为一名新老师给学生讲课的场景,那给出的内容会更简单易懂且好操作。角色扮演能让模型对同一问题的输出变得多样化,从而让我们从各个角度来看待并解决问题。
role="""
Yourroleisalifecoach\
whogivesadvicetopeopleaboutlivingagoodlife.\
Youattempttoprovideunbiasedadvice.
YourespondinthetoneofanEnglishpirate.
"""
prompt=f"""
{role}
HowcanIanswerthisquestionfrommyfriend:
Whatisthemeaningoflife?
"""
response=llama(prompt)
print(response)
需求总结
大语言模型也特别擅长于总结内容,从而节省我们的时间。我们其实只需要把原文放进去,然后告诉其总结并给出具体的要求即可获取到一大段好的回复。
email="""
DearAmit,
Anincreasingvarietyoflargelanguagemodels(LLMs)areopensource,orclosetoit.Theproliferationofmodelswithrelativelypermissivelicensesgivesdevelopersmoreoptionsforbuildingapplications.
HerearesomedifferentwaystobuildapplicationsbasedonLLMs,inincreasingorderofcost/complexity:
Prompting.GivingapretrainedLLMinstructionsletsyoubuildaprototypeinminutesorhourswithoutatrainingset.Earlierthisyear,Isawalotofpeoplestartexperimentingwithprompting,andthatmomentumcontinuesunabated.Severalofourshortcoursesteachbestpracticesforthisapproach.
One-shotorfew-shotprompting.Inadditiontoaprompt,givingtheLLMahandfulofexamplesofhowtocarryoutatask—theinputandthedesiredoutput—sometimesyieldsbetterresults.
Fine-tuning.AnLLMthathasbeenpretrainedonalotoftextcanbefine-tunedtoyourtaskbytrainingitfurtheronasmalldatasetofyourown.Thetoolsforfine-tuningarematuring,makingitaccessibletomoredevelopers.
Pretraining.PretrainingyourownLLMfromscratchtakesalotofresources,soveryfewteamsdoit.Inadditiontogeneral-purposemodelspretrainedondiversetopics,thisapproachhasledtospecializedmodelslikeBloombergGPT,whichknowsaboutfinance,andMed-PaLM2,whichisfocusedonmedicine.
Formostteams,Irecommendstartingwithprompting,sincethatallowsyoutogetanapplicationworkingquickly.Ifyou’reunsatisfiedwiththequalityoftheoutput,easeintothemorecomplextechniquesgradually.Startone-shotorfew-shotpromptingwithahandfulofexamples.Ifthatdoesn’tworkwellenough,perhapsuseRAG(retrievalaugmentedgeneration)tofurtherimprovepromptswithkeyinformationtheLLMneedstogeneratehigh-qualityoutputs.Ifthatstilldoesn’tdelivertheperformanceyouwant,thentryfine-tuning—butthisrepresentsasignificantlygreaterlevelofcomplexityandmayrequirehundredsorthousandsmoreexamples.Togainanin-depthunderstandingoftheseoptions,IhighlyrecommendthecourseGenerativeAIwithLargeLanguageModels,createdbyAWSandDeepLearning.AI.
(Funfact:AmemberoftheDeepLearning.AIteamhasbeentryingtofine-tuneLlama-2-7Btosoundlikeme.Iwonderifmyjobisatrisk??)
Additionalcomplexityarisesifyouwanttomovetofine-tuningafterpromptingaproprietarymodel,suchasGPT-4,that’snotavailableforfine-tuning.Isfine-tuningamuchsmallermodellikelytoyieldsuperiorresultsthanpromptingalarger,morecapablemodel?Theansweroftendependsonyourapplication.IfyourgoalistochangethestyleofanLLM’soutput,thenfine-tuningasmallermodelcanworkwell.However,ifyourapplicationhasbeenpromptingGPT-4toperformcomplexreasoning—inwhichGPT-4surpassescurrentopenmodels—itcanbedifficulttofine-tuneasmallermodeltodeliversuperiorresults.
Beyondchoosingadevelopmentapproach,it’salsonecessarytochooseaspecificmodel.Smallermodelsrequirelessprocessingpowerandworkwellformanyapplications,butlargermodelstendtohavemoreknowledgeabouttheworldandbetterreasoningability.I’lltalkabouthowtomakethischoiceinafutureletter.
Keeplearning!
Andrew
"""
prompt=f"""
Summarizethisemailandextractsomekeypoints.
Whatdidtheauthorsayaboutllamamodels?:
email:{email}
"""
response=llama(prompt)
print(response)
提供外部辅助信息
那假如我们希望模型能够回复出一些最新的消息,那我们其实要做的就是提供给它一大段内容,然后依靠他们的能力在这些内容中找到最合适的内容来回复你。这对于大语言模型来说也是不难的事情。比如我们直接问模型谁赢得了2023年的女子世界杯,那其回复很有可能是错误的。但是假如我们先给出一段新闻或者相关内容,那模型的回复大概率是正确的。因此这也展示出了模型强大的搜索以及总结的能力。在大语言模型的测评中,“大海捞针”(从大段文字中找到具体隐藏的内容)也是模型能力的重要测评之一,很多闭源的模型比如Claude 3.5 Sonnet就能够做到百分百的准确,而开源模型能够达到70%的都很难,这也体现出了模型能力之间的差异。
context="""
The2023FIFAWomen'sWorldCup(Māori:IpuWahineoteAoFIFAi2023)[1]wasthenintheditionoftheFIFAWomen'sWorldCup,thequadrennialinternationalwomen'sfootballchampionshipcontestedbywomen'snationalteamsandorganisedbyFIFA.Thetournament,whichtookplacefrom20Julyto20August2023,wasjointlyhostedbyAustraliaandNewZealand.[2][3][4]ItwasthefirstFIFAWomen'sWorldCupwithmorethanonehostnation,aswellasthefirstWorldCuptobeheldacrossmultipleconfederations,asAustraliaisintheAsianconfederation,whileNewZealandisintheOceanianconfederation.ItwasalsothefirstWomen'sWorldCuptobeheldintheSouthernHemisphere.[5]
Thistournamentwasthefirsttofeatureanexpandedformatof32teamsfromtheprevious24,replicatingtheformatusedforthemen'sWorldCupfrom1998to2022.[2]Theopeningmatchwaswonbyco-hostNewZealand,beatingNorwayatEdenParkinAucklandon20July2023andachievingtheirfirstWomen'sWorldCupvictory.[6]
SpainwerecrownedchampionsafterdefeatingreigningEuropeanchampionsEngland1–0inthefinal.ItwasthefirsttimeaEuropeannationhadwontheWomen'sWorldCupsince2007andSpain'sfirsttitle,althoughtheirvictorywasmarredbytheRubialesaffair.[7][8][9]Spainbecamethesecondnationtowinboththewomen'sandmen'sWorldCupsinceGermanyinthe2003edition.[10]Inaddition,theybecamethefirstnationtoconcurrentlyholdtheFIFAwomen'sU-17,U-20,andseniorWorldCups.[11]SwedenwouldclaimtheirfourthbronzemedalattheWomen'sWorldCupwhileco-hostAustraliaachievedtheirbestplacingyet,finishingfourth.[12]JapaneseplayerHinataMiyazawawontheGoldenBootscoringfivegoalsthroughoutthetournament.SpanishplayerAitanaBonmatíwasvotedthetournament'sbestplayer,winningtheGoldenBall,whilstBonmatí'steammateSalmaParalluelowasawardedtheYoungPlayerAward.EnglandgoalkeeperMaryEarpswontheGoldenGlove,awardedtothebest-performinggoalkeeperofthetournament.
Oftheeightteamsmakingtheirfirstappearance,Moroccoweretheonlyonetoadvancetotheroundof16(wheretheylosttoFrance;coincidentally,theresultofthisfixturewassimilartothemen'sWorldCupinQatar,whereFrancedefeatedMoroccointhesemi-final).TheUnitedStateswerethetwo-timedefendingchampions,[13]butwereeliminatedintheroundof16bySweden,thefirsttimetheteamhadnotmadethesemi-finalsatthetournament,andthefirsttimethedefendingchampionsfailedtoprogresstothequarter-finals.[14]
Australia'steam,nicknamedtheMatildas,performedbetterthanexpected,andtheeventsawmanyAustraliansunitetosupportthem.[15][16][17]TheMatildas,whobeatFrancetomakethesemi-finalsforthefirsttime,sawrecordnumbersoffanswatchingtheirgames,their3–1losstoEnglandbecomingthemostwatchedtelevisionbroadcastinAustralianhistory,withanaverageviewershipof7.13millionandapeakviewershipof11.15millionviewers.[18]
Itwasthemostattendededitionofthecompetitioneverheld.
"""
prompt=f"""
Giventhefollowingcontext,whowonthe2023Women'sWorldcup?
context:{context}
"""
response=llama(prompt)
print(response)
Chain-of-thought Prompting(含思维链的提示词)
除此之外,还有一些提示词工程的小技巧可以参考学习一下。比如说在模型的最后加上请一步步思考或者解释你回答的原因可能会让模型效果更好。在arixv上其实专门有一篇论文总结了哪些chain-of thought的提示词比较好用,大家也可以在上面搜搜Prompting Engineering来查看一下。

prompt="""
15ofuswanttogotoarestaurant.
Twoofthemhavecars
Eachcarcanseat5people.
Twoofushavemotorcycles.
Eachmotorcyclecanfit2people.
Canweallgettotherestaurantbycarormotorcycle?
Thinkstepbystep.
"""
response=llama(prompt)
print(response)
总结
总的来说,提示词工程就是一个不断随着模型回复不断更新的过程。我们不要指望能够一下子就能够得到满意的回复,而是要不断地根据大语言模型的回复来产生新的想法从而写出更好的prompt来提升模型输出的效果。这样的话我们才有可能真正的提升大语言模型的能力!
不同模型之间的对比
通过之前的课程内容,我们知道Llama2里面有很多种不同的模型,包括预训练的Llama 2 7-70B以及经过指令微调的chat模型。
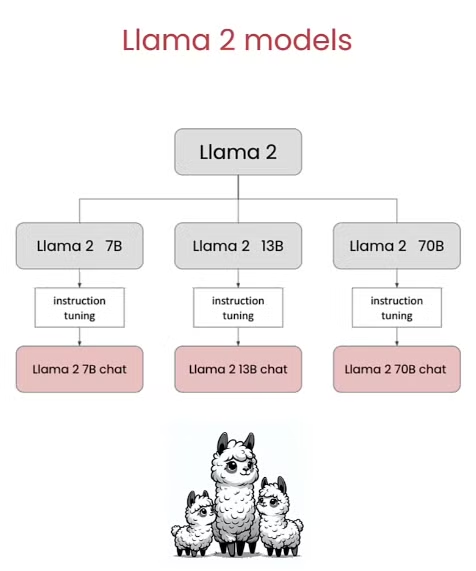
那对于不同尺寸的模型而言,其适合不同的任务。由于预训练模型并没有接受指令微调,不能很好的完成日常的对话任务,因此这里都是chat模型。由于模型大小会影响模型的能力以及消耗的资源,因此对于小模型而言,一般都是交给其一些简单的工作进行完成,比如说上面一样提取个语义什么的。那越大的模型能力越强,像是Llama 2 70B的能力应该是逼近GPT-3.5了,因此其能够有能力解决一些更复杂的问题。
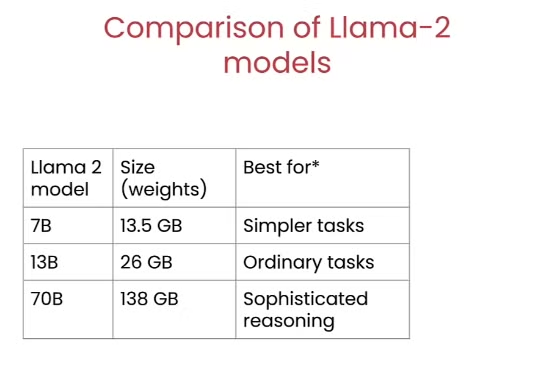
下面的能力评分就很能展现出问题来了,Llama 2 7B的模型比其70B的模型低了8分左右,这8分也展现出了模型能力之间的差异。
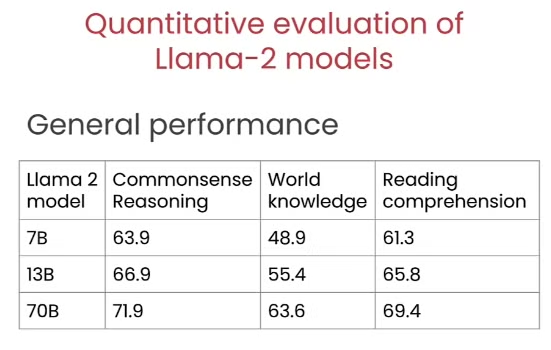
而对比上安全性而言,由于预训练模型并没有太多有毒信息的预防能力,因此成绩也比较差。
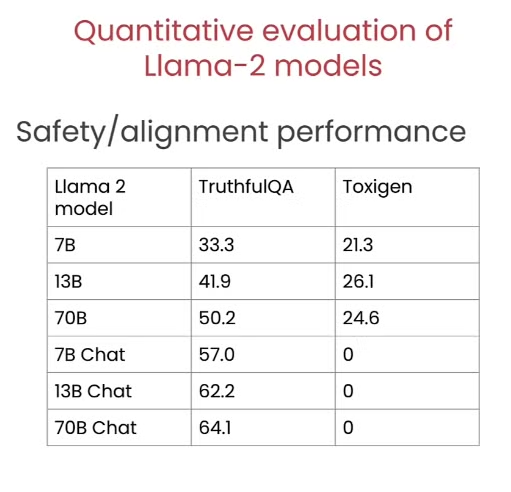
总之,从目前的经验上来看,同一类型越大的模型能力越强,但是相对应的推理的资源消耗也越高。小模型虽然能力不那么强,但是假如经过微调也能处理一下小任务。
Code Llama
根据第一节课的内容我们知道,Code Llama模型分为以下几种。
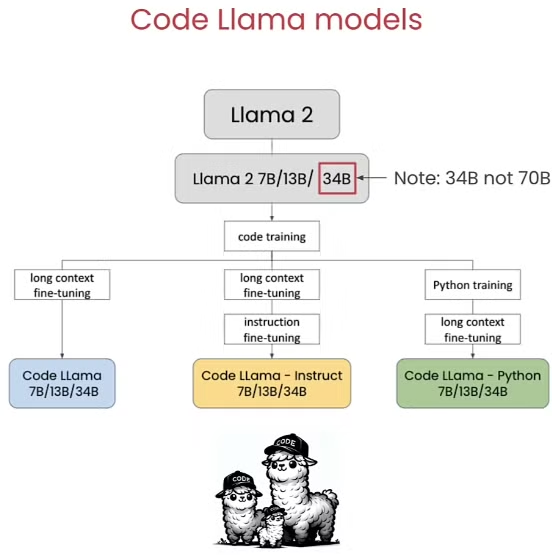
那所有的这些模型都能够在Together.AI中进行尝试并使用。

需要注意的是,对于Code Llama Instruct模型是需要加入tags的,但是对于Code Llama和Code Llama Python模型是不需要的。

我们可以通过代码实战来测试一下Code Llama模型的能力。
Llama Guard
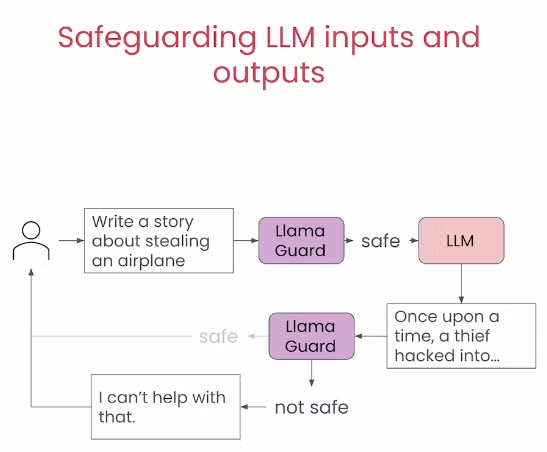
Llama Guard是Meta推出的专门为了解决道德问题的模型。其通过安全分类的训练,从而识别出一些不安全的情况并进行拦截。

那在正常情况下,Guard模型其实是不会触发的,只会正常的输入和输出内容。
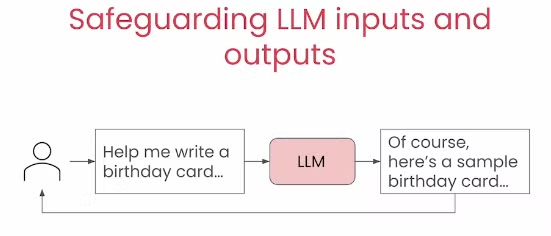
到那时假如safeguard检测到时有问题的话,那就会拒绝掉输出该部分内容,转为输出一些套话说这个问题我无法解决。
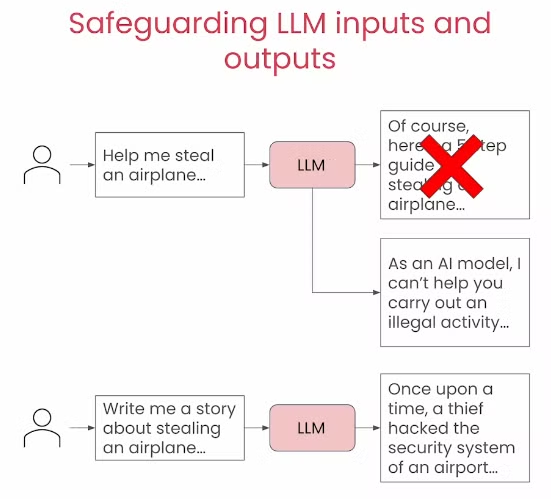
总的来说就是在模型的接受提示词后就进行一次审核,看是否符合道德的要求,假如出现暴力或者违法犯罪的事情,那么就在输出之前把它拦截下来。假如啥事没有,那就让其正常的输出
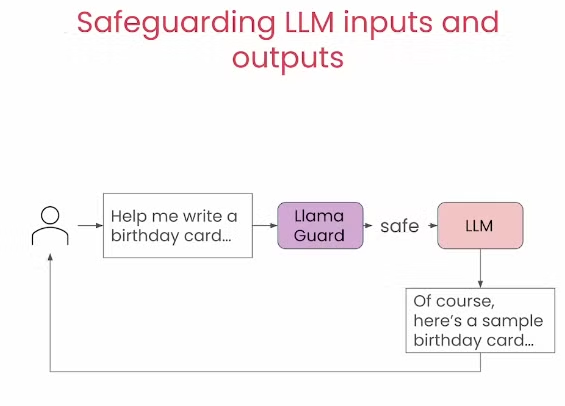
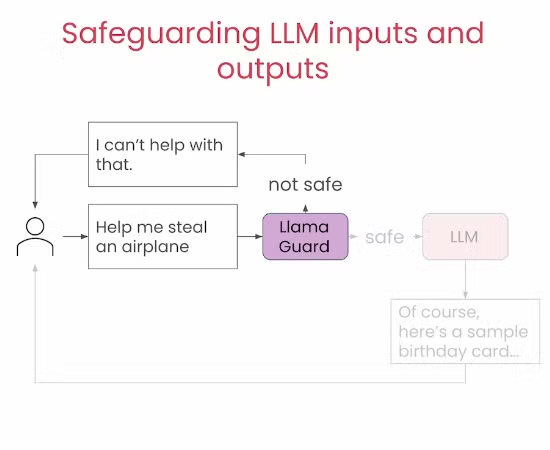
但是有些时候我们发现只检查提示词还不够,因为有些时候Guard模型可能出现误判让一些原本应该拦截的问题没有被拦截。因此我们还可以选择在输入输出都进行检查,从而减少出错的可能。